简单且高效的静态单一赋值形式构造
摘要 我们提出一个简单的 SSA 构造算法,它允许直接从抽象语法树或者字节码翻译到一个基于 SSA 的中间表示形式。这个算法不需要事先的分析,且保证在中间表示构造期间是 SSA 的形式。这样允许在构造期间应用基于 SSA 的优化。在完成后,中间表示是最小且纯的 SSA 形式。尽管它很简单,我们算法的运行时间与 Cytron 等人的算法相当。
简介
许多现代编译器具有的中间表示(IR)是基于静态单一赋值形式的(SSA 形式)。SSA 旨在通过紧凑地表示 use-def 链,来提高程序分析的效率。在过去的几年里,事实证明,SSA 形式不仅有助于提高分析效率,而且更有利于实现,测试和调试。因此,现代编译器如 Java HotSpot VM[14],LLVM[2],和 libFirm[1] 都是基于 SSA 形式的中间表示。
第一个高效构造 SSA 形式的算法是由 Cytron 等人[10] 提出的。这个算法仍然十分流行的一个原因是,它保证了放置$\phi$函数数量的最小形式。但是,对于需要完全基于 SSA 的编译器,这个算法有个显著的缺点:它的输入程序不得不表示为非-SSA 形式的控制流图(CFG)。因此,如果编译器想要从输入语言(给定的抽象语法树或一些字节码格式)构造 SSA 形式,它必须通过非SSA CFG 绕道,才能应用 Cytron等人 的算法。此外,为了保证最小的$\phi$函数放置,Cytron 等人的算法依赖于其它几个分析和转换:为了计算放置 $\phi$ 函数的位置,需要计算支配树和迭代支配边界。为了避免放置死 $\phi$ 函数,不得不执行活性分析或者死代码消除[7]。两个都需要 CFG 和依赖于其它分析,因而不便于在 SSA 为中心的编译器中使用这个算法。
现代基于 SSA 的编译器使用了不同的方法来构造 SSA:例如,LLVM 使用 Cytron 等人的算法,通过将所有局部变量放入内存(这通常不在 SSA 的形式中)中来模拟非-SSA 的 CFG。这些使用内存操作表达那些变量的简单定义和使用是由代价的。我们的测量表明 LLVM 前端生成的指令中有 25% 是这种类型:在 IR 构造之后立即被 SSA 构造移除。
其它编译器,如 Java HotSpot VM,因为上面提到的不便之处,完全不使用 Cytron 等人的算法。但是,它们也有问题,没有计算最小或者纯的 SSA 形式,也就是说,它们插入了多余的或者死的 $\phi$ 函数。
在这篇文章中,我们
- 提出了一个简单的,新的 SSA 构造算法,它既不需要支配也不用迭代支配边界。因此,它适用于直接从 AST 中构造一个基于 SSA 的中间表示(第 2 节);
- 展示如何在IR构造期间,将这个算法和实时优化结合来降低占用空间(第 3.1 节);
- 描述了一个后期过程,用于构造任意程序的最小 SSA 形式(第 3.2 节);
- 证明了这个 SSA 构造算法可以构造所有程序的纯的 SSA 形式,和可以构造可规约控制流的程序的最小 SSA 形式(第 4 节);
- 表明这个算法可以应用到其它相关的领域,如将一个命令式的程序转换为一个函数式连续传递格式(CPS)的程序,或者在转换后重构 SSA 形式,如生命周期范围拆分或者再具化,已经添加了更多的定义到一个 SSA 值上(第 5 节);
- 证明算法的高效性和简易性。是通过再 Clang 中实现这个算法,然后和 Clang/LLVM 中的 Cytron 等人的算法实现进行比较来证明的。(第 6 节)。
据我们所知,本文提出的这个算法是第一个可以在可规约 CFG 上构建最小和纯 SSA 而不需要依赖于其它的分析。
简单的 SSA 构造
接下来,我们描述我们的算法来构造 SSA 形式。它与 Cytron 等人的算法在基础想法上是有本质的不同的。Cytron 等人的算法在正向操作上是一种激进的方式:首先,这个算法收集了所有变量的定义。然后,它计算了相关 $\phi$ 函数的放置,最后,将这些变量定义点推下去给使用点。相比之下,我们的算法以一种延迟方式后向工作:只有当变量被使用,我们才会去查找它的到达定义。如果它在当前位置未知,我们会后向搜索程序。我们沿途会在 CFG 的连接点插入 $\phi$ 函数,直到我们发现想要的定义。我们使用记录来避免重复查找。
这个过程有几个步骤组成,我们会在这节的剩余部分详细解释。首先,我们考虑单个基础块。然后,我们扩展算法到整个 CFGs。最后,我们展示如何处理不完整的 CFGs,其在 AST 翻译为 IR 的过程中经常出现。
局部值标号

当转换一个源程序时,一系列语句的 IR 通常是以单个基础块结束。我们按程序执行顺序处理这些语句,对于每个基础块,我们都有每个变量到当前定义表达式的映射。当遇到一个变量赋值,我们记录赋值右侧的 IR 作为变量当前的定义。因此,当一个变量读,我们会查找它的当前定义(见算法 1)。这个过程被命名为局部值标号[9]。当一个块的局部值标号完成,我们认为这个块已填充了。特别是,后继只能添加到已填充块中。这个属性在后续处理不完全 CFGs 的时候就会用到。

一个简单的程序及其处理结果如图 1 所示。为了演示,我们通过名字 $V_i$ 表示每个 SSA 值。在具体的实现中,我们只会参考表达式的表示。名称没有其它意义,特别是它们不是命令式语言意义上的局部变量。
现在,如果在基本块中分配变量之前读取变量,则会出现问题。这可以在变量 d 及其对应值$V_?$的示例中看到。在这个场景中,d 的定义可以在从 CFG 根到当前块的路径中找到。而且,源程序中的多个定义可以搜索到相同的使用。下一节显示如何扩展局部值标号到处理这些场景的。
全局值标号
如果一个块没有包含一个变量的定义,我们在它的前驱中递归查找定义。如果块只有有单个前驱,只需要递归地查找它的定义。此外,我们从所有的前驱中收集定义,然后构造 $\phi$ 函数,即连接它们到一个简单的新值。在这个基础块中,$\phi$ 函数记录为当前的定义。
在前驱中查找一个值可能会导致更多递归的查找。由于程序中的循环,它们可能会导致无限递归。因此,在递归前,我们会创建没有操作数的 $\phi$ 函数,将其记录为块中变量的当前定义。然后我们确定$\phi$函数的操作数。如果递归查找返回到这个块中,这个 $\phi$ 函数会提供定义且递归结束。算法 2 给出执行全局值标号的伪代码。它的第一个条件将会用于处理不完整的 CFGs,因此当前假设它总是错的。
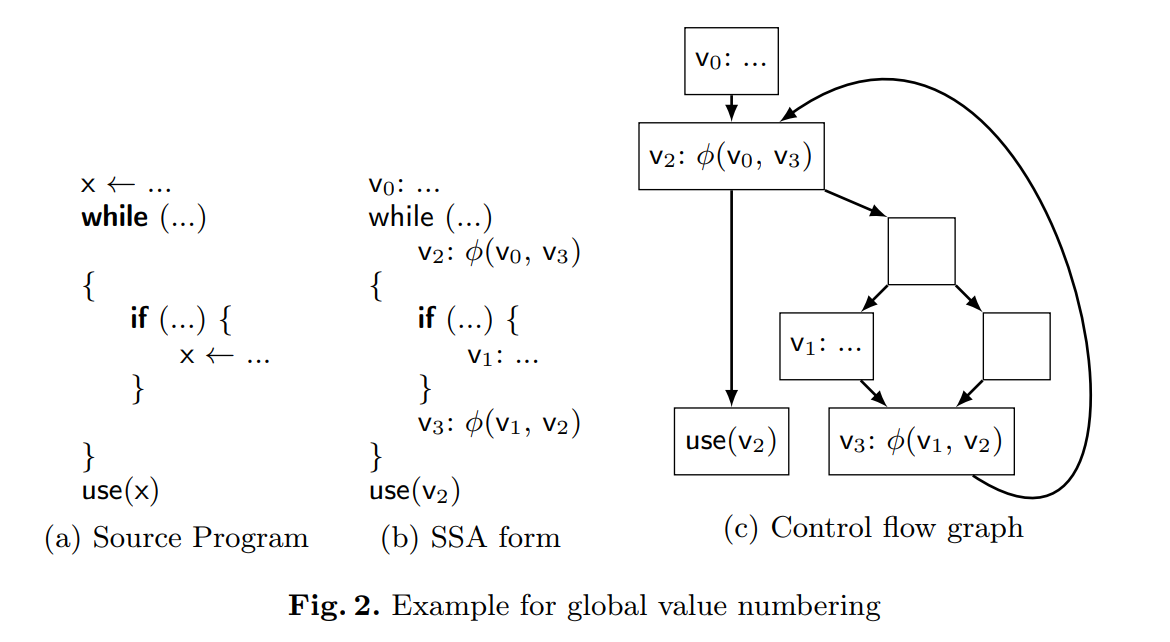
图 2 给出了这个过程。为了演示,值 $V_i$ 的下标按算法插入它们的顺序给出。我们假设循环是在读 x 前创建的,即,$V_0$ 和 $V_1$ 通过局部值标号记录为 x 的定义,然后只有循环之后的语句会查找 x 。当循环之后的块没有记录 x 的定义,我们会执行一个递归地查找。块只有一个前驱时,不需要 $\phi$ 函数。前驱是一个循环头,其中没有 x 的定义且有两个前驱。因此,我们会放置一个无操作数的 $\phi$ 函数 $V_2$。第一个操作数是流入循环的值$V_0$。第二个操作数需要进一步递归。$\phi$ 函数 $V_3$ 被创建然后从它的直接前驱中获得操作数。特别的是,$V_2$ 会比较早的被放置,来打破递归。
递归查找可能会留下一些冗余的 $\phi$ 函数。我们说一个 $\phi$ 函数 $V_{\phi}$ 是细小的,是当且仅当它只依赖于自己和一个其它值$V$任意次:


$\exists v \in V: v_{\phi} : \phi(x_1, … x_n) x_i \in {v_{\phi}, v}$ 。这样的 $\phi$ 函数可以移除,使用 v 的值替换(见算法 3)。作为一个特例,$\phi$ 函数可能除了它本身没有使用其它值了。这意味着它可能不可达,或者在开始块中。我们会用一个未定义值替换它。
此外,如果 $\phi$ 函数被成功替换,其它使用这个替换值的 $\phi$ 函数也有可能会变成细小的。因为这个原因,我们将这个简化递归应用到它所有的使用点。
这种方式能用于无环的语言结构。这个场景中,我们可以在处理块之前填充它所有的前驱。递归将只会搜索所有已填充的块。这确保了我们可以从前驱中取到每个变量的最新定义。例如,在 if-then-else 语句中,包含条件的块可以在 then 和 else 分支处理前被填充。 因此,在两个分支完成之后,连接分支的块会被填充。这种方式在构建循环之后读取变量时也适用。但是,当在循环中读取变量时,正在构建中,一些前驱–至少跳回循环头的前驱–会丢失。
处理不完整的 CFGs
我们称一个基本块是密封的,如果没有更多的前驱被加入到这个块中。由于只有填充块可能有后继块,所以前驱块总是填充过的。请注意密封块不一定是填充的。直观地,一个填充块包含它所有的指令,可以为它的后继提供变量定义。反过来,一个密封块可能会在它的前驱中查找变量定义,因为所有的前驱是已知的。

但是如何在一个未密封的块中处理变量查找,这个块没有这个变量当前的定义?在这个场景下,我们放置一个无操作数的 $\phi$ 函数到块中,然后将其记录为代理定义(见算法 2 中的第一个场景)。因此,我们在每个块中维护这些代理的一组 incompletePhis。当最后这个块密封时,我们为这些 $\phi$ 函数添加操作数(见算法 4)。然后,当 $\phi$ 函数已经完成,我们会检查它是否是细小的。
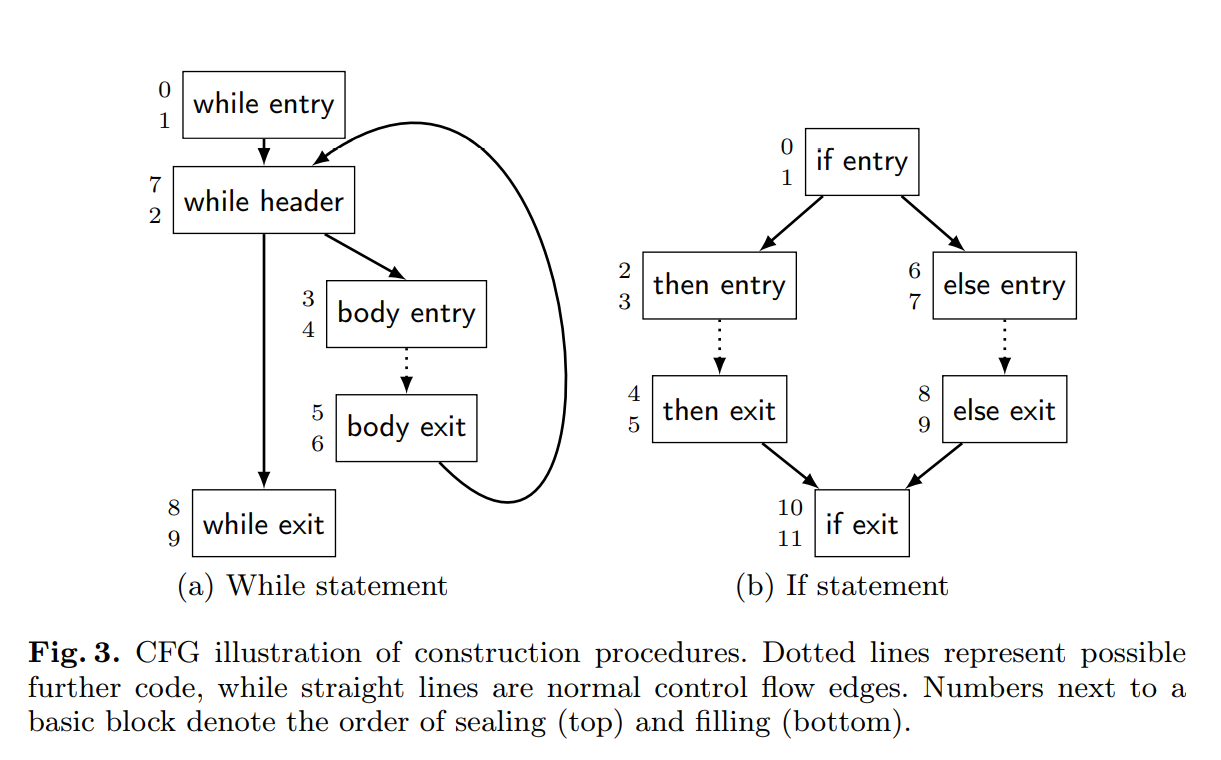
在 IR 构建中,封闭一个块是一个显式操作。我们通过图 3a 中的构建 while 循环的例子的示例如何合并这步。首先,我们构建 while header 块,然后添加一条从 while entry 块到它的控制流边。因为从 body exit 跳出需要在之后添加,我们还不能封闭 while header。下一步,我们创建 body entry 和 while exit 块,且添加从 while header 到这两个块的条件控制流。没有更多的前驱会被加入到 body entry 块中,所以现在我们可以封闭它了。由于循环中的中断指令,while exit 块可能会获得更多的前驱。现在我们填充循环体。这些可能会包含更多的内部控制结构,如图 3b 给出的 if。最后,它们在 body exit 块处收敛。构成主体的所有块都在这个点封闭。现在我们添加一个回到 while header 的边,封闭 while header。这个循环就完成了。在最后一步,我们封闭 while exit 块,然后继续 while 循环之后的源语句的 IR 构建。
优化
实时优化
在前一节中,我们表明了我们会在细微 $\phi$ 函数创建之后,立即优化它们。因为 $\phi$ 函数属于 IR,这个意味着我们能在 SSA 构建期间应用 IR 优化。显然,不可能应用所有的优化。在这节中,我们阐述哪种 IR 优化可以在 SSA 构造期间执行,以及调查它们的效率。
我们从 $\phi$ 函数的优化是否可以移除所有的细微 $\phi$ 函数的问题开始。就像 2.2 节已经提到的,我们递归优化所有使用了已经移除的细微 $\phi$ 函数的 $\phi$ 函数。由于一个 $\phi$ 函数优化成功后只能使得使用前一个的 $\phi$ 函数变得微不足道,这个机制保证我们能优化所有的细微 $\phi$ 函数。在第 4 节中,我们表明,对于可规约的 CFGs,这等价于构建最小的 SSA 形式。
因为我们的方法可能会导致显著的琐碎检查的数量,我们使用下面的缓存技术来加速这样的检查:当构建一个 $\phi$ 函数时,我们记录前两个不同的操作数,它们也不同于 $\phi$ 函数本身。这些操作数作为 $\phi$ 函数非细微性的目击者。当一个新的细微检查发生,我们再比较目击者。如果它们以及 $\phi$ 函数都彼此不同,这个$\phi$ 函数仍然时不平凡的。否则,我们需要找一个新的目击者。因为直到第二个操作数前的所有操作数都等于第一个或者 $\phi$ 函数本身,我们只需要考虑再两个老的目击者之后创建的操作数。因此,这个技术加速了同一个 $\phi$ 函数上的多个细微检查。
这个机制有更多的简单变种,使得可以再大部分但不是全部的场景下构建最小的 SSA:如我们可以不优化已替换 $\phi$ 函数的使用者,而是优化唯一的操作数。这个变体对于 IR 来说特别有趣,因为它本身没有为每个值提供使用者列表。
这个 $\phi$ 函数的优化是众多可以在 IR 构建期间执行的优化的其中一种。通常,我们的 SSA 构建算法允许利用保守的 IR 优化,即,只需要局部分析的优化。这些优化包括:
算术简化 所有的 IR 节点执行窥孔优化,在可能的情况下返回简化后的节点。例如,减法 $x-x$ 的构建总是产生常数 0。
通用子表达式消除 这个优化重用已经存在的被局部值标号识别了的值。
常量折叠 这个优化在编译时间里计算常量表达式,如,2*3 被优化成 6。
拷贝传播 这个优化会移除局部变量不必要的赋值,如,x = y。在 SSA 形式中,并不需要这样的赋值,我们可以直接使用右侧的值。
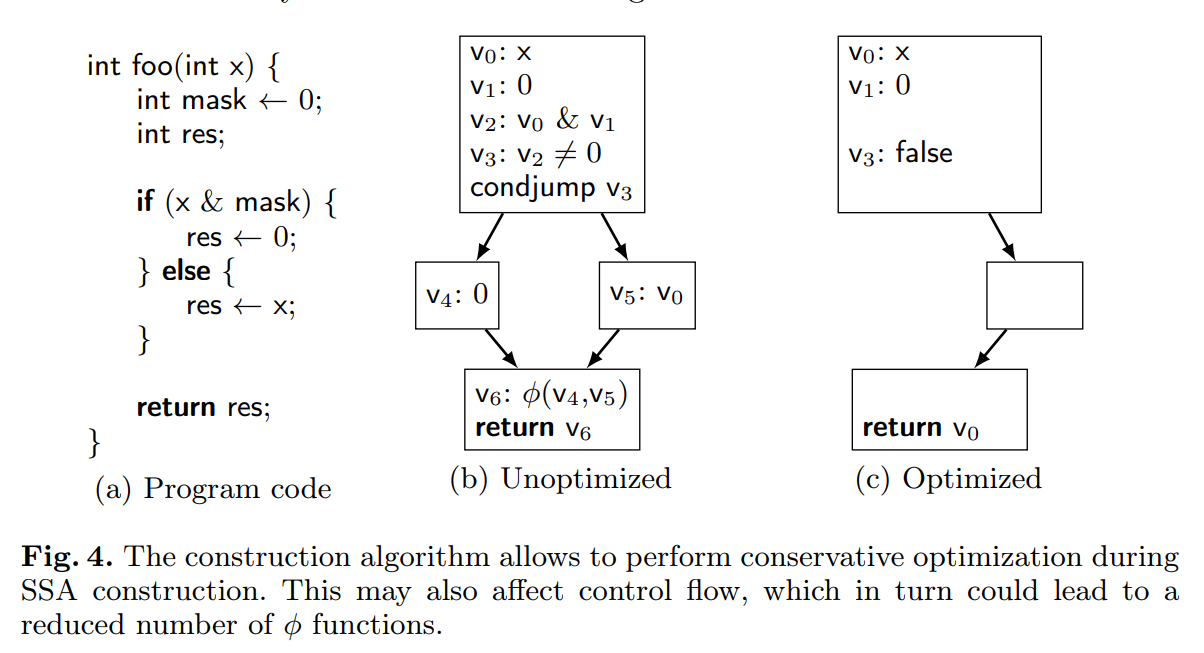
图 4 表明了这些优化的效果。我们想要构造图 4a 给出的代码段的 SSA 结构。没有实时优化,则对应的 SSA 形式的程序如图 4b。使能优化带来的第一个不同是发生在值 $V_2$ 构建的期间。因为和 0 按位与总是产生 0,算法简化触发,简化了这个值。而且,常量值总是有效的。因此,通用子表达式消除在值 $V_2$ 上重用了值 $V_1$。下一步中,常量传播将与 0 的比较折叠为 false。因为条件跳转的条件是 false,我们可以忽略 then 部分。在 else 的部分里,我们执行拷贝传播,将 $V_0$ 注册为 res 的值。类似的,$V_6$ 会消除,函数的结尾返回 $V_0$。图 4c给出优化后的 SSA 形式的程序。
这个例子演示了实时优化可以更多的降低 $\phi$ 函数的数量。甚至比根据 Cytron 等人的定义得到的最小 SSA 形式,它会导致需要更少的 $\phi$ 函数。
任意控制流最小的 SSA 形式
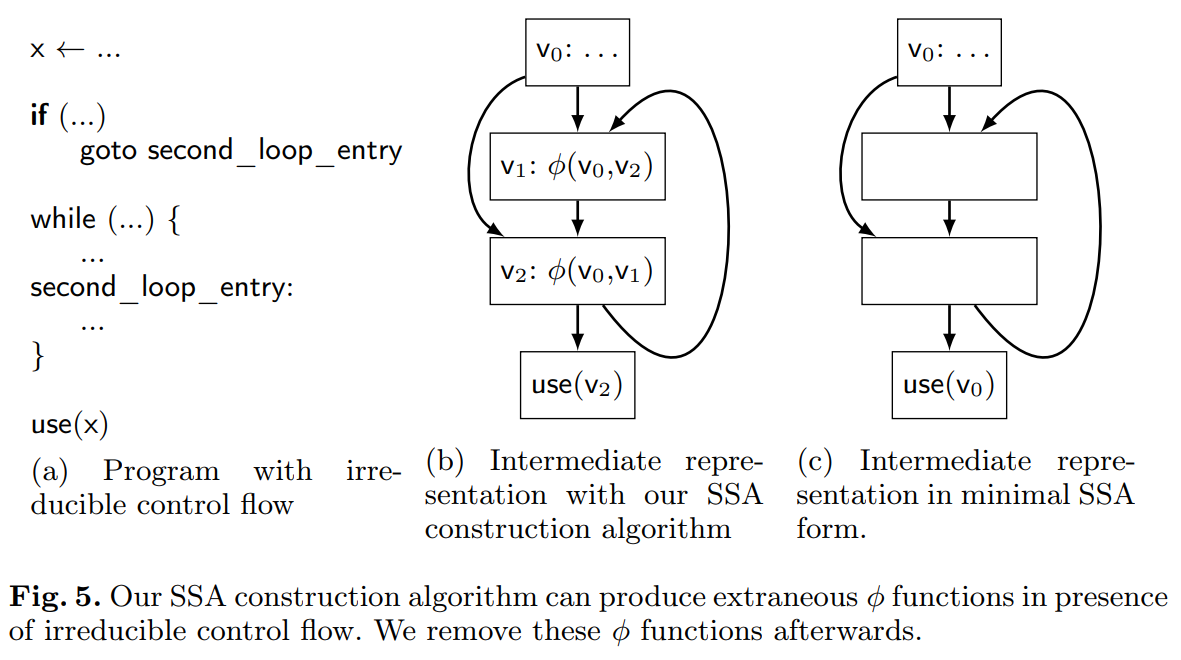
到目前为止,我们的 SSA 构建算法在非可规约控制流的场景下不能构建最小的 SSA 形式。图 5b 给出了图 5a 显示的程序的已构造的 SSA 形式。图 5c 给出了对应的最小 SSA 形式 – 通过 Cytron 等人的算法构建的。因为变量 x 只有一个定义,通过我们算法构建的 $\phi$ 函数存在多余的。
通常,$\phi$ 函数一个非空集合 P 是冗余的,当且仅当 $\phi$ 函数只是相互依赖或者只依赖其它的一个值$v: \exists v \in V \forall v_i \in P: v_i : \phi(x_1, …, x_n) \ x_i \in P \cup {v}$ 。特别是,当 P 只包含一个 $\phi$ 函数时,这个定义退化为 2.2 节给出的平凡 $\phi$ 函数的定义。我们表明每个冗余 $\phi$ 函数 P ,其包含了一个强连接分量(SCC),也是冗余的。这些暗示着独立于源程序的极简主义定义,其比 Cytron 等人的定义更严格[10]。
引理 1 令 P 是关于 v 的冗余 $\phi$ 函数集。然后强连通分量 $S\subseteq P$ 也是冗余的。
证明,令 $P’$ 为 P 的缩合,即,P 中的每个 SCC 都收缩为单个节点。这导致了$P’$ 是无环的[11]。因为 $P’$ 是非空的,它有个叶子节点 $s’$。令 S 是 SCC,其与 $s’$ 相关。因为 $s’$ 是叶子,S 的 $\phi$ 函数只关联与$v$ 或 S 中的其它 $\phi$ 函数。因此,S 是一个冗余的 SCC。
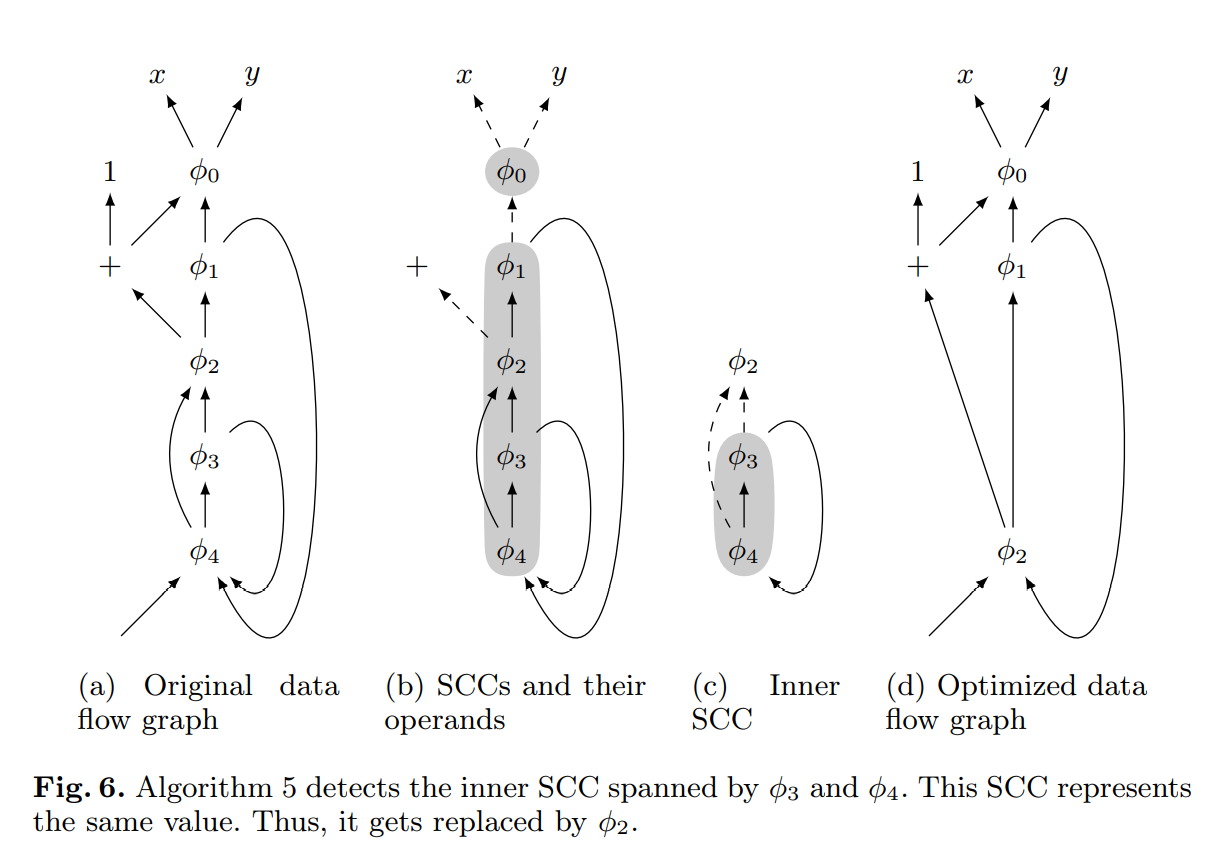
算法 5 利用了引理 1 来移除多余的 $\phi$ 函数。函数 removeRedundantPhis 处理一组 $\phi$ 函数,然后计算它们导出子图的 SCCs。图 6b 显示了来自图 6a 的数据流图生成的 SCCs。每条虚线边指向一个不属于其来源的 SCC 的值。我们按拓扑顺序处理 SCCs,保证当前 SCC 外用到的值已经签约了。在我们的例子中,这意味着我们首先处理仅包含 $\phi_0$ 的 SCC。由于 $\phi_0$ 是 SCC 中唯一的 $\phi$ 函数,在移动平凡 $\phi$ 函数的期间,我们已经处理了它了。因此,我们跳过这个 SCC。

对于下一个包含 $\phi_1-\phi_4$ 的 SCC,我们构造两个集合:集合 inner 包含所有仅在 SCC 内具有操作数的所有 $\phi$ 函数。集合 outerOps 所有操作数不属于 SCC 的 $\phi$ 函数。对于我们的例子,inner = {$\phi_3$, $\phi_4$} ,outerOps = {$\phi_0$, +}。
如果 outerOps 集合是空的,相关的基础块必须是不可达的,且我们会跳过这个 SCC。在 outerOps 集合恰好只包含一个值时,SCC 中的所有 $\phi$ 函数只能获得这个值。因此,我们替换 SCC 为这个值。如果 outerOps 包含多个值,所有在 SCC 之外有操作数的 $\phi$ 函数都是必需的。我们收集 inner 集合剩余的 $\phi$ 函数。因为我们的 SCC 可以包含多个内部的 SCCs,我们递归的用这些内部的 $\phi$ 函数来执行程序。图 6c 我们例子的内部 SCC。在递归步骤中,我们用 $\phi_2$ 替换 SCC。图 6d 给出生成的数据流图结果。
执行实时优化(3.1节)会导致不可规约的数据流。例如,让我们考虑 2.2 节描述的图 2。假设两个给 x 的赋值是从某些其它的变量 y 拷贝过来的。如果现在我们执行拷贝传播,我们获得两个 $\phi$ 函数 $v_2: \phi(v_0, v_3)$ 和 $v_3: \phi(v_0, v_2)$,形成多余的 SCC。请注意这个 SCC 也会出现在用 Cytron 算法构造出来的程序执行拷贝传播之后。因此,算法 5 也可以应用到其它的 SSA 构造算法上。最后,算法 5 可以被认为是 Aycock 和 Horspool 提出的局部简化的概括(见 7 节)。
降低临时 $\phi$ 函数的数量
所提出的算法结构简单,以于实现。尽管,它可能会产生大量的临时 $\phi$ 函数,但可以在 IR 构造期间立即移除。下面,我们描述算法的两个扩展,致力于减少或者消除这些临时的 $\phi$ 函数。
标记算法。对于一个变量,许多的控制流连接并不需要 $\phi$ 函数。所以不是在递归前直接插入,而是我们只标记块被访问过。如果我们在递归期间再次搜索到这个块,则我们将会放置一个 $\phi$ 函数来打破这个循环。在收集了所有来自前驱的定义后,我们会移除标记,然后如果我们找到不同的定义则放置 $\phi$ 函数(或者重用递归放置的那个)。使用这个技术,不会有临时的 $\phi$ 函数被放置在无环的数据流区域。临时的 $\phi$ 函数只会在数据流循环中生成,然后稍后可能会被识别为不需要。
SCC 算法。在递归中,我们使用 Tarjan 的算法来识别数据流环,即,SCCs[17]。如果只有一个值进入循环,就不需要$\phi$ 函数。否则,我们在每个基础块中放入 $\phi$ 函数,因为这些块有个前驱来自循环外。为了添加操作数到这些 $\phi$ 函数,我们会再次应用递归查找,因为这可能需要放置更多的 $\phi$ 函数。这反映了 3.2 节描述的移除冗余 $\phi$ 函数循环的算法。在密封块递归的场景中,算法只是放置了必要的 $\phi$ 函数。下一节给出了必要 $\phi$ 函数的正式定义,然后给出一个只会放置必要 $\phi$ 函数生成最小 SSA 形式的算法。
算法特性
因为大部分的优化将 $\phi$ 函数作为不能解释的函数,尽可能少地放置 φ 函数是有益的。在本节的剩余部分,我们表明了我们的算法不会放置死的 $\phi$ 函数,可以构造出可规约控制流程序的最小(根据 Cytron 等人的定义) SSA 形式。
精简 SSA 形式 当程序中的每个 $\phi$ 函数(传递性)都至少有一个非-$\phi$ 的使用者,则程序被认为是精简的 SSA 形式[7]。当一个使用者需要 $\phi$ 函数时,我们在按需创建它:读一个变量或者另一个 $\phi$ 需要一个参数。所以我们的构建会自然的产生一个精简的 SSA 形式的程序。
最小 SSA 形式 最小的 SSA 形式要求一个变量 $v$ 的 $\phi$ 函数只出现在 $v$ 的不同定义第一次相遇的基础块里。Cytron 等人的正式定义是基于下面两个术语的:
定义 1(路径收敛) 两个非空路径 $X_0 \rightarrow^+ X_J$ 和 $Y_0 \rightarrow^+ Y_K$被认为是收敛到块$Z$,当且仅当下面的条件满足:
$$
X_0 \neq Y_0; \ \ \ (1)
$$
$$
X_J = Z = Y_K; \ \ \ (2)
$$
$$
(X_j = Y_k) \Rightarrow (j = J \bigvee k = K). \ \ \ (3)
$$
定义 2(必要的 $\phi$ 函数) 块 $Z$ 中必须有变量 $v$ 的 $\phi$ 函数,当且仅当两个非空路径 $X\rightarrow^+ Z$ 和 $Y\rightarrow^+Z$ 归约到块$Z$,且块 X 和 Y 都包含 $v$ 的赋值。
只有必要 $\phi$ 函数的程序时最小 SSA 形式。下面是一个证明,我们在第 2 节中给出的带有 $\phi$ 函数的简化规则的算法能在可规约程序中产生最小的 SSA 形式。
如果任意从入口块到 B 的路径都经过了 A,则我们称块 A 支配了块 B。如果 A 支配了 B 且$A\neq B$,则称 A 严格支配 B。除了入口块以外的每个块 C 都有一个独一的立即支配者$idom(C)$,即,C 的一个严格支配者,其不支配 C 的其它任意严格支配者。支配关系可以呈现为一颗树,它的节点是带有立即支配块的基本块。
定义 3(可规约图,Hecht 和 Ullman[12]) 一个(控制)流图 G 是可规约的,当且仅当对于 G 中的每个循环 C,C 中存在一个节点,其会支配 C 中所有的其它节点。
现在我们假设我们的构造算法已经完成,产生了一个带有可规约 CFG 的程序。我们观察到算法 3 中的简化规则 tryRemoveTrivialPhi 对于每个 $\phi$ 函数的当前参数,都至少应用了一次。这是因为都是在一个 $\phi$ 函数的参数第一次设置时应用这个规则的。在另一个操作简化导致参数改变的场景中,这个规则会再次应用。此外,我们的构造算法满足下面的属性:
定义 4(SSA 属性) 在一个 SSA-形式的程序中,一条从变量 $v$ 的 SSA 值定义到它的使用,不会包含 $v$ 其它的定义或者$\phi$ 函数。$\phi$ 函数操作数的使用发生在各自前驱块中,不在 $\phi$ 函数的块中。
SSA 属性确保了只有变量$v$ 的“最近的” SSA值会被使用。此外,它禁止一个变量的多个 $\phi$ 函数在相同的基础块中出现。
引理 2 令 p 是一个块 P 的一个 $\phi$ 函数。此外,令 q 在块 Q 中,r 在块 R 中,是 p 的两个操作数,如此 p,q,和 r 是两两各不同的。则 Q 和 R 中至少有一个是不支配 P 的。
证明,假设 Q 和 R 支配 P,即,每个一个从开始块到P的路径中都包含 Q 和 R。因为立即支配形成一个树,Q 支配 R或者 R 支配 Q。不失一般性的,令 Q 支配 R。此外,令 S 是 P 的相关前驱块,其中 p 使用了 q。则有一条从开始块穿过Q,然后是 R 和 S。这违反了 SSA 的特性。
引理 3 如果块 P 中的一个变量 $v$ 的一个 $\phi$ 函数是不必要的,但是非平凡的,则它在块 Q 中有一个操作数 q,如此 q 是不必要的 $\phi$ 函数且 Q 不支配 P。
证明,节点 p 至少有两个不同的操作数 r 和 s,都不是 p 本身。否则,p 是平凡的。它们可能是:
- 直接赋值给 $v$ 的结果。
- 必要的 $\phi$ 函数 $r’$ 的结果。但是这就意味着 $r’$ 可以被两个不同的直接给 $v$ 赋值到达。所以有条从 $v$ 的直接赋值到 p 的路径。
- 另一个非必要的 $\phi$ 函数。
假设块 R 中的 r 或者块 S 中的 s 都不是非必要的 $\phi$ 函数。然后一条从一个赋值到块 $V_r$ 中的 $v$ 的路径穿过 R 和一条从一个赋值到块 $V_s$ 中的 $v$ 穿过 S。它们收敛到 P 或者更早的地方。在 P 收敛是不可能的,因为 p 是不必要的。一个更早的收敛暗示着此处有一个必要的 $\phi$ 函数,这违反了 SSA 的特性。
所以 r 或者 s 必须是非必要的 $\phi$ 函数。不失一般性的,令它是 r。
如果 R 没有支配 P,则 r 是受欢迎的 q。所以令 R 支配 P。由于引理 2,S 一定不支配 P。应用 SSA 的特性,$r \neq p$ 产生$R \neq P$。因此,R 严格支配 P。这暗示着 R 支配着 P 所有的前驱,其中包含着 p 的使用,特别是前驱 $S’$ 包含着 s 的使用。由于 SSA 的特性,这是一条从 S 到 S’ 的路径,其不包含 R。应用 R 支配 S‘,产生 R 支配 S。
现在假设 s 是必须的。令 X 在从起始块到 R 的路径上包含 v 的最新定义。因为 R 支配 S,则 SSA 的特性得出这些定义中的一个被包含在路径 $R\rightarrow^+S$ 的块 Y 中。因此,有路径 $X\rightarrow^+P$ 和 $Y\rightarrow^+P$ ,得到 p 是必须的。因为这个是矛盾的,s 是不必要的且追捧 q。
定理 1. 一个有可规约 CFG G 的 SSA 形式的程序,没有任何的平凡 $\phi$ 函数,是为最小的 SSA 形式。
证明,假设 G 不是最下的 SSA 形式,且不包含非平凡的 $\phi$ 函数。我们选择一个不必要的 $\phi$ 函数 p。由于引理 3,p 有一个操作数 q,其是不必要的且不支配 p。通过归纳,q 也有一个不需要的$\phi$ 函数作为操作数,依次类推。因为程序只有有限数量的操作,当伴随着 q 链时,必须有一个环。$\phi$ 函数中的一个环暗示着 G 中的一个环。由于 G 是可以归约的,控制流包含一个入口块,其支配了循环中所有的其它块。不失一般性的,令 q 在入口块,这意味着它支配了 p。因此,我们的假设是错误的,G 要么是最小的 SSA 形式,要么存在平凡的 $\phi$ 函数。
因为我们的构造算法会移除所有的平凡 $\phi$ 函数,对于可归约的 CFGs,产生的 IR 将会是最小 SSA 形式的。
时间复杂度
我们使用下面的参数来提供一个我们算法的精确的最坏情况复杂度:
- B 表示了基础块的数量。
- E 表示了 CFG 边的数量。
- P 表示程序的大小。
- V 程序变量的数量。
我们从 2.3 节给出的简单 SSA 构造算法开始分析。在最坏情况下,SSA 构造需要给每个变量插入带有 $\Theta(E) $个操作数的$\theta(B)$ 个 $\phi$ 函数。结合在所有基础块里的构造 SSA 形式是 $\Theta(P)$ 的事实,它导致了一个比较低的边界$\Omega(P + (B+E) \centerdot V)$。
我们证明我们的算法是符合这个下限的,导致最坏情况复杂度是$\Theta(P + (B+E)\centerdot V)$。我们的算法需要$\Theta(P)$来填充所有的基础块。由于我们变量的映射,我们最多放置 $O(B\centerdot V)$ 个 $\phi$ 函数。此外,我们在块前驱上最多执行$O(E\centerdot V)$次递归请求。总计,这些导致了最坏复杂度是$\Theta(P+(B+E)\centerdot V)$。
接下来,我们考虑 $\phi$ 函数的实时优化。一旦我们优化一个 $\phi$ 函数,我们会检查使用了前者的 $\phi$ 函数是否也可以优化。因为我们的算法最多构造 $B\centerdot V$ 个 $\phi$ 函数,这导致了 $O(B^2 \centerdot V^2)$ 个检查。依次检查需要比较 $\phi$ 函数的最多 $O(B)$ 个操作数。但是使用了 3.1 节描述的缓存技术,每个$\phi$函数执行的检查数量摊销了相关 $\phi$ 函数的检查时间。因此,$\phi$ 函数的实时优化可以在 $O(B^2 \centerdot V^2)$ 里执行。
为了获得最小 SSA 形式,我们需要构造传递相同值得 SCCs。因为我们只考虑 $\phi$ 函数和它们的操作数,SCCs 的大小是$O((B+E) \centerdot V$。因此,为数据流图计算 SCCs 是在$O(P + (B + E) \centerdot V)$。计算集合 inner 和 outer 只考虑每个$\phi$函数和它的操作数一次。因此,它也是$O((B+E) \centerdot V)$。如果只有一个外部操作数,则相同的论点适用于 SCC 的收缩。在其它场景中,我们用子图迭代这个过程,这些子图是由我们的 SCC中的节点适当子集归纳得到的。综上,这些得出 SCCs的收缩的时间复杂度是 $O(P+B\centerdot (B+E) \centerdot V^2)$。
算法的其它应用
SSA 重构
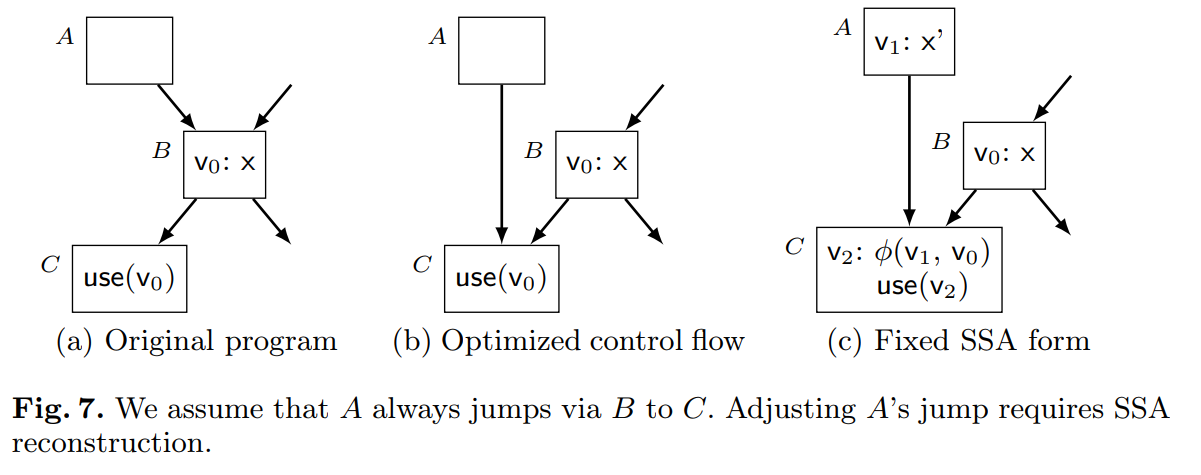
一些转换如活跃范围拆分,再实例化,或者跳转线程等会给 SSA 的值引入额外的定义。因为这些违反了 SSA 的特性,所以 SSA 不得不重构。对于后面的变换,我们运行一个例子来证明我们的算法是如何用于 SSA 重构的。考虑一个分析,确定图 7a 中的基本块 B 当从 A 进入时总是分支到 C(图 7b)。因此,我们令 A 直接跳到 C(图 7b)。但是,定义$v_0$ 不再支配它的使用了。我们可以通过第一次插入 $v_0$ 的拷贝 $v_1$ 到 A 中来解决这个问题。然后,当 V 只是一些引用定义集的句柄时,我们调用 writeVariable(V, A, x’) 和 writeVariable(V, B, x)**,这代表着“相同的变量”。下一步,一个readVariableRecursive(V, C)** 的调用添加了必要的 $\phi$ 函数,生成 $v_2$ 作为新的定义,且用于更新 $v_0$ 的原始使用(图 7c)。
尤其是,对于跳转线程,它希望不依赖于支配计算–这与 Cytron 等人的算法相反:通常,会执行几个迭代的跳转线程直到不可能再提高了。因为跳转线程用非平凡的方式改变了控制流,每个迭代可能都需要重计算支配树。
请注意 SSA 的重构总是运行在完整的 CFGs 上。因此,这边的设定不会出现封闭和非封闭基本块的问题。
CPS 构造
CPS 是函数式编程技术,可以连续的捕获控制流。延续是永不返回的函数。相反的,每个延续调用尾部的另一个延续。

SSA 形式可以被认为是 CPS 的一种严格形式[13, 3]。我们的算法也适用于直接将一个命令式的程序转为函数式的 CPS 程序,不需要第三种程序表示。我们必须将参数放在局部函数中,而不是 $\phi$ 函数。我们将参数放入前驱的调用中,而不是添加操作数到 $\phi$ 函数。就像构造 SSA 形式一样,3.1 节描述的实时优化,也可以用于压缩程序。图 8 演示了 CPS 的构造。
在一个 CPS 程序中,我们不能简单的移除 $\phi$ 函数。而是,我们不得不消除参数,修复函数的类型和调整这个函数中所有的使用。由于这一组转换时昂贵的,值得一开始就不要引入不必要的参数,因此使用 3.3 节中描述的扩展。
评估
对比 Cytron 等人的算法
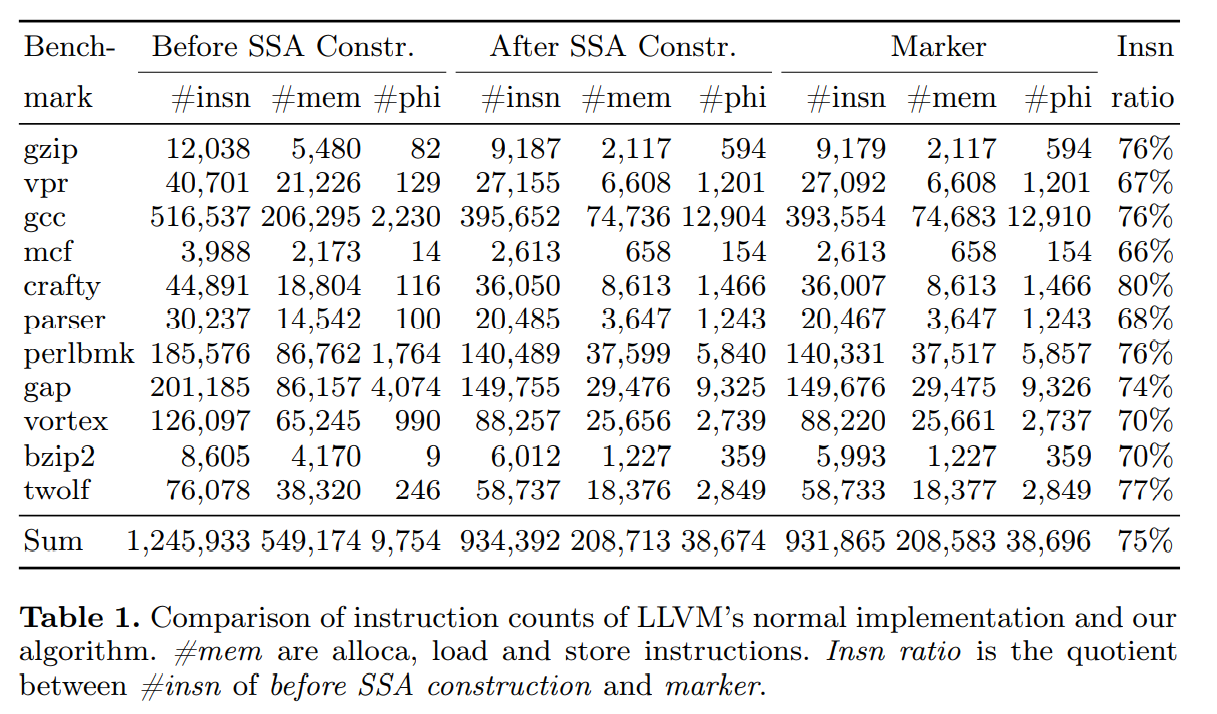
我们在 LLVM 3.1 [2] 中实现了本文提到的算法,将其与已经存在的,高度调优实现的 Cytron 等人的算法进行比较。表 1 给出了两个算法构造的指令数量比较。因为 LLVM 的第一个模型通过加载和存储指令来访问局部变量,我们也立即表示了 SSA 构造前的指令。总计,SSA 构造降低了 25% 的指令数,这表明了临时非SSA IR的巨大固有开销。
比较已构造指令的数量,我们看到了 LLVM 的结果和我们的 SSA构造算法的细微不同。$\phi$ 函数数量不同的一个原因是冗余 SCCs 的移除:3(11 个中的)个非平凡 SCCs 不是来自于不可归约的控制流,不能被 Cytron 等人的算法移除。 $\phi$ 函数和内存指令的数量的剩余差异源自处理不可达代码的细微差异。在大部分的测试集中,我们的算法触发了更多的 LLVM 常量折叠,从而进一步减少了总指令数。利用更多的实时优化,如 3.1节描述的通用子表达式消除,甚至能更进一步压缩总指令数。
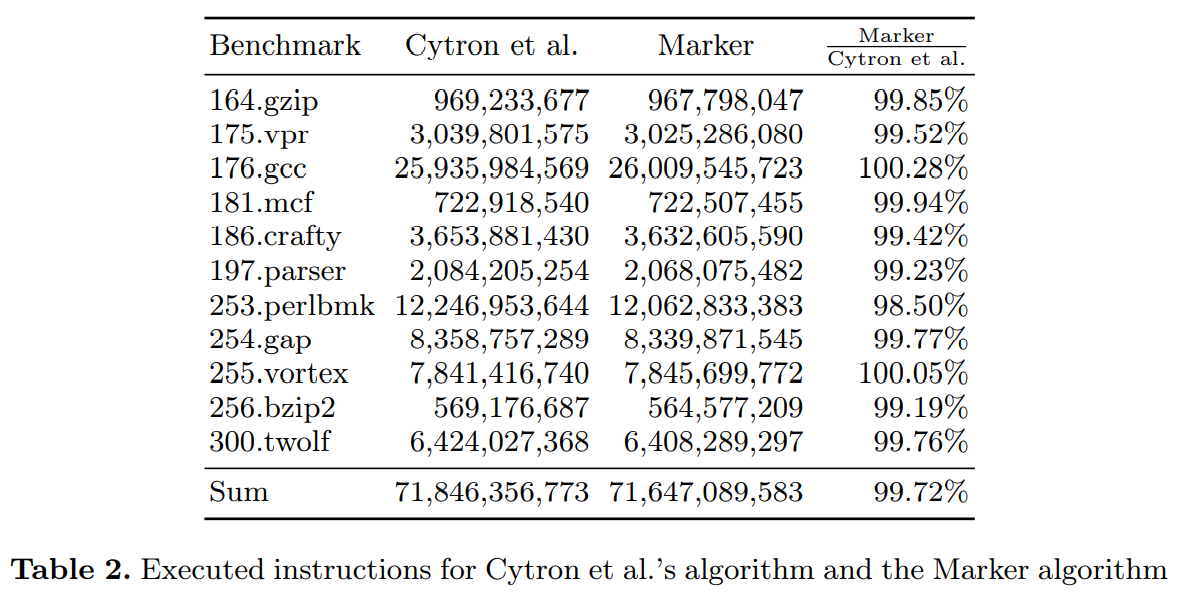
对于两个测试集的运行时比较,我们统计执行的 X86 指令数。表 2 给出了 valgrind 仪表工具收集的数量。虽然每个测试集的结果各不同,但标记算法总共需要少量的 (0.28%) 的指令。所有的测量都是在 3.4 GHz 的酷睿 i7-2600 的 CPU 上执行的,然后与 SPEC CINT2000 测试套的 C 程序比较。
实时优化的效果
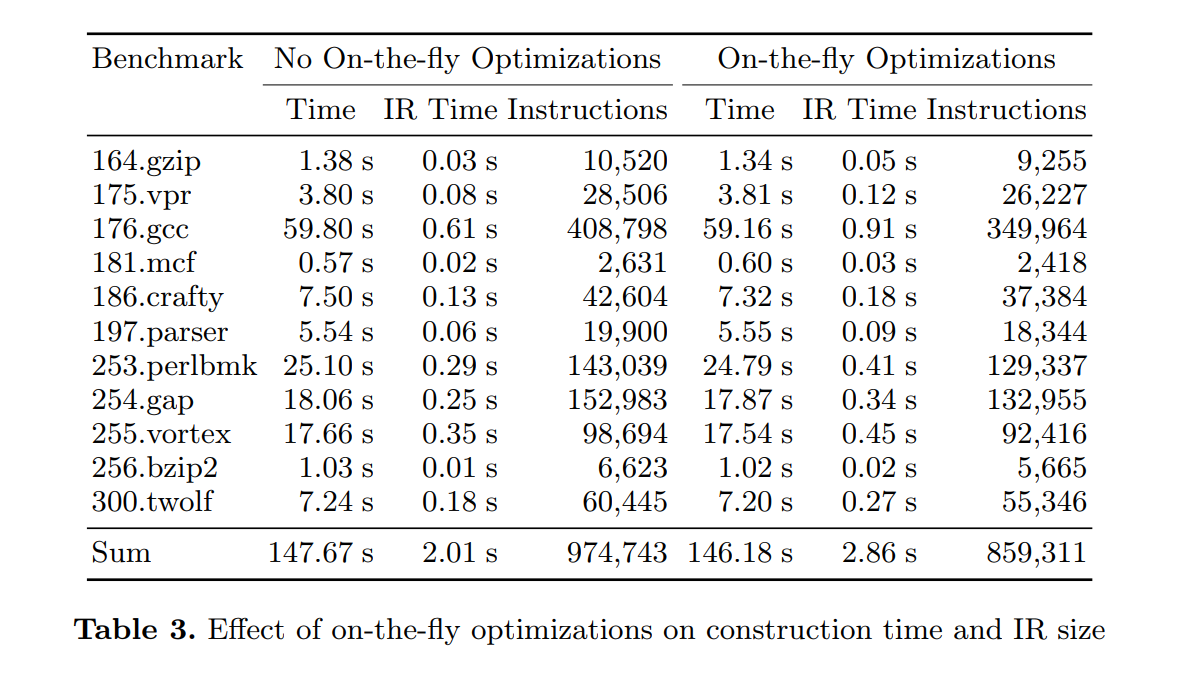
我们也在 SSA 构造的速度和质量上评价执行实时优化(3.1 节描述的)的效果。我们的 libFirm [1] 编译器库始终精选了本文描述的构造算法的变体。这里有许多的优化和 SSA 构造交织在一起。结果如表 3 显示的。在构造期间使能实时优化,导致增加了 0.84s 构造时间,但生成的图只有 88.2% 的节点数量。这些加速了后续的优化,使得整个编译快了 1.49s。
结论
实践中证明这个算法与 Cytron等人的算法一样快。但是,如果这个算法与实时优化结合,总体编译时间会下降。这使得该算法成为即时编译器的有趣候选者。
相关的工作
SSA 形式由 Rosen,Wegman,和 Zadeck [15] 发明,在Cytron等人 [10]给出一个高效的构造算法之后变得流行。这个算法可以在所有呈现 SSA 形式的文本中找到,被大多数编译器使用。对于每个变量,计算所有包含定义的块的支配边界。然后,一个重写过程创建新的变量编号,插入 $\phi$ 函数,然后分派它的使用。这个论文的必要细节已经在第 1 节中讨论过了。
Choi 等人 [7] 给出了前一个构建最小和精简 SSA 形式的算法的一个扩展。它计算每个变量的活跃信息,然后只要 v 存活在相关的基础块里则插入 v 的一个 $\phi$ 函数。这个技术可以用于其它的 SSA 构造算法来确保精简的 SSA 形式,但是会伴随着一些计算活跃信息的开销。
Briggs 等人[6]提出了 半精简SSA 形式,其忽略了有开销的活性分析。但是,它们只能阻止位于基本块里的局部变量创建死的 $\phi$ 函数。
Sreedhar 和 Gao [16] 提出了数据结构,称为 DJ 图,是边来自于 CFG 的增强支配树。比起为每个基本块计算迭代支配边界,这个数据结构只是线性于程序大小,然后能够在线性时间里计算每个变量需要放置 $\phi$ 函数的块。它给出了一个 SSA 构造算法其最坏情况复杂度是源程序大小的三次方。
同时存在一些系列构建算法,致力于简化。Brandis 和 Mössenböck [5] 提出了一个简单的 SSA 构造算法,如同我们的算法一样可以直接在 AST 上工作。但是,他们的算法只限于结构化控制流(没有 gotos)且不构建精简的 SSA 形式。Click 和 Paleczny [8] 描述了一个基于图的 SSA 的中间表示,用于 Java HotSpot 服务端编译器[ 14] ,以及一个从 AST 构造这个 IR 的算法。他们的算法在理念上是 Brandis 和 Mössenböck 的一种,因此,既不能构建精简也不能构建最小的 SSA 形式。Aycock 和 Horspool 给出了一个为了简单设计的 SSA 构建算法 [4]。他们在每个基本块中都为每个变量放置了 $\phi$ 函数。然后,他们应用如下的规则来移除 $\phi$ 函数:
- 移除 $v_i = \phi(v_i, …, v_i)$ 这种形式的 $\phi$ 函数。
- 用 $i_1, …, i_n \in {i, j}$ 替换 $v_i = \phi(v_{i_1}, …, v_{i_n})$ 这种形式的 $\phi$ 函数。
这些能为可归约程序产生最小的 SSA 形式。这个方式明显的缺点是有在每个基本块中插入 $\phi$ 函数的固有开销。这些基本块包括了在包含相关变量真实定义的每个基本块之前的基本块。
结论
在这篇论文中,我们提出了一个新的,简单的,和高效的 SSA 构建算法。比起已经存在的算法,它有几个优势:它不需要其它的分析和转换就能产生最小的(在可归约的 CFGs)和精简的 SSA 形式。它可以直接从源语言构建,不需要通过非SSA CFG 的形式。它也非常适合于在 SSA 构建期间执行几个标准的优化(常量折叠,值标号,等)。这降低了已构建程序占用的空间,这在一些编译时间至关重要的场景是很重要的。在 IR 构建之后,一个后期的过程保证了可以为任意控制流构建最小 SSA 的形式。我们的算法对于 SSA 重建也是有用的,这个场景,直到现在,标准 SSA 构建算法也不能直接应用。最后,我们证明了我们的算法总是能构建精简的和最小的 SSA 形式。
性能方面,在 LLVM 编译器上,我们算法的一个非优化实现略快于高度优化实现了的 Cytron 等人的算法,由 SPEC CINT2000 测试集测量获得。我们期望在微调我们的实现之后,我们可以进一步提高性能。
致谢 我们感谢匿名审阅者提出的有帮助的评论。这个工作一部分是在德国基础研究(DFG)支持下完成的,作为跨区域合作研究中心 “侵入式计算” 的一部分(SFB/TR89)。
引用
略。