SELF 自适应优化:探索性编程与高性能共存
摘要
面向对象语言带来许多的益处,其中的抽象性,可以让程序员隐藏来自对象客户端的对象实现细节。不幸的是,在跨越抽象边界如频繁的过程调用中总是伴随着巨大的运行时开销。因此,尽管频繁的使用抽象是这类语言的设计目的,但这是不切实际的,因为,它会导致程序非常低效。
激进的编译器优化会降低抽象的开销。但是优化编译器带来长的编译时间会延长编程环境反馈程序变化的时间。此外,优化也会与源码级别的调试冲突。因此,程序员面临一个两难的选择,不得不在高效的抽象和高效的编程环境之间进行选择。本论文会展示如何通过延迟编译调和这个看起来是矛盾的目标。
融合四个新的技术来达成高性能和高响应:
- Type feedback 通过允许编译器基于获取自运行时系统的信息内联消息发送(message send)来取得高性能。平均来说,在有类型反馈的SELF系统上,程序运行会比在之前的 SELF 系统快1.5倍;而与商业的 Smalltalk 实现对比,两个中型的 benchmark 会快三倍。这个水平的性能是从一个比之前 SELF 编译器更简单和更快速的编译器上取得的。
- Adaptive optimization 在取得高响应的同时不会牺牲性能,通过使用非优化编译器生成初始代码,同时在运行期间使用优化编译器重编程序中重度使用的代码部分。在前一代的工作平台上如 SPARCstation-2,50 分钟的交互中有将近200个暂停超过200ms,21个暂停超过了 1 秒。在当代的工作平台上,只有13个暂停超过400ms。
- Dynamic deoptimization 在需要时通过隐式地重建非优化代码,使得程序员可以远离调试优化过的代码的复杂性。不管一个程序是否被优化过,它都可以被停止,检查和单步调试。比起之前的方法,去优化(deoptimization)支持更多的调试的同时,对于可执行的优化代码添加更少的限制。
- Polymorphic inline caching 实时生成类型信息序列来加速来自于相同调用位置但具有不同的类型对象的消息发送。更重要的是,它会为优化编译器搜集了具体的类型信息。
具有高性能和良好的交互行为的这些技术,让探索性编程既适用于纯粹面向对象语言,也适用于需要更高最终性能的应用领域;调和了探索性编程,繁多的抽象和高性能。
致谢
作者的感谢,暂不翻译。
目录列表
暂不翻译。
图片列表
暂不翻译。
表列表
暂不翻译。
1. 引言
面向对象编程越来越流行,因为它让编程更简单了。它允许程序员隐藏来自对象客户端的实现细节,将每个对象放入对应的抽象数据类型中,操作和状态都只能通过消息发送进行访问。延迟绑定极大地提高了抽象数据类型的能力,通过允许相同抽象数据类型的不同实现,在运行时可以实现进行互换。这个互换指的是一段调用某个对象的一个操作的代码并不总是最终会被执行调用的代码:延迟绑定(也叫动态分发)会选择一个操作合适的实现基于对象的准确类型。因为延迟绑定对于面向对象是最基本的,需要高效的实现来支持。
理想状态下,面向对象语言会全部使用延迟绑定的,即使对于实例变量访问这种基础的操作也是一样。越普遍地使用封装和动态分发,最终的代码具有越高的自由度和重用性。但是延迟绑定会带来效率问题。例如,如果所有的实例变量方位都使用消息发送,编译器无法将一个对象的属性x的访问翻译为一个简单的加载指令,因为对象间的x实现可能是不同的。例如,一个笛卡尔点可能只是返回一个实例变量的值,而一个极坐标点会根据半径和角坐标计算x的值然后进行返回。这种变化恰恰是延迟绑定的意义:x的操作与操作的实现(实例变量的访问和计算)的绑定延迟到了运行的时候才做。因此,x的操作必须编译成一个动态分发的调用(也叫间接函数调用或者虚函数调用),从而可以在运行时选择一个合适的实现。这导致了一个周期的指令变成了十个周期的调用。随着源码自由度和重用度的增加会带来显著的运行时开销;从而看起来封装和高效是不能共存的。本文会展示如何平衡两个。
一个相似的效率问题也出现在渴望使用探索性编程环境上。一个探索性编程环境增加了程序员的生产率通过对所有的编程操作给与立即的反馈;零暂停交互允许程序员集中于手上的任务而不被长时间的编译暂停分心。通常来说,系统设计者在探索性编程环境会使用解释器和非优化的编译器。不幸的是,解释器的开销,伴随着动态分发的效率问题,降低了执行性能,因此限制了这种系统的使用。这篇论文描述如何降低动态分发的开销从而保证一个交互探索编程环境的反馈获取。
我们研究的轮子是面向对象语言 SELF。SELF 的纯语义加剧了面向对象语言面临的实现问题:在 SELF,每个单操作(甚至赋值操作)都涉及延迟绑定。因此,这个语言是降低延迟绑定优化的理想测试用例。同样重要的是,SELF是为了探索编程设计的。每个探索编程环境必须提供程序变化之后快速的转化,和局部程序的简单调试,从而增加程序员的生成率。因此,一个这种系统的优化编译器不仅要解决动态分发带来的性能问题,也要适配交互性:编译必须快速和非侵入性的,还有系统必须支持全时间段的全源码调试。
我们为SELF实现了一个系统,工作的贡献有:
- 一个新的优化策略, Type Feedback,允许任意的动态分发调用被内联。在我们为 SELF 做的实现样例中,类型反馈将函数调用降低了四倍同时提高了 70% 的性能比起没有类型反馈的系统。尽管 SELF 和 C++ 是完全不同的语言模型,新的系统使得 SELF 在两个中型的面向对象的程序达到了优化过的C++性能的一半。
- 一个重编译系统,动态重新编译应用的 “hot spots”。这个系统通过一个快速的非优化编译器产生初始化代码,然后通过一个慢的优化编译器重新编译那些时间紧迫的部分代码。引入自适应动态编译戏剧性地提高了 SELF 系统的交互性能,让优化编译和探索性编程环境结合成为了可能。即使在前一代工作平台如 SPARCstation-2,50 分钟的交互中有将近200个暂停超过200ms,21个暂停超过了 1 秒。
- 一个内联缓存的扩展, polymorphic inline caching,可以加速多态 调用点的动态分配调用。此外多态内联缓存可以做为类型反馈的类型信息源,平均提升11%的性能。
- 一个调试系统,动态退优化为全局优化代码提供源码级别的调试。即使优化代码只支持严格的调试,这个系统可以隐藏那些限制,提供全源码级别的调试(例如,单步调试这类调试操作)。
虽然我们的实现基于动态编译,但是本文中大部分的技术不需要它。类型反馈会直接被整合进传统的编译系统(看5.6节),类似于其它的基于 profile 的系统。源码级别的调试可以通过保留编译前的未优化代码到一个分离的文件来实现(看10.5.3)。多态内联只需要一个简单的桩生成器,并不需要全成熟的动态编译。只有5.3节描述的动态编译系统–从本质上而言–才需要动态编译。
本文描述的技术都不仅仅限定于 SELF 语言。就如10.5.3节的讨论,调试系统具有非常大的语言无关性。类型反馈可以优化任何语言的延迟绑定;如和面向对象语言相比,那些有重度使用延迟绑定的非面向对象语言(如,APL的通用操作符,Lisp的通用算术)也会从这种优化中获得收益。最后,任何使用动态编译得系统都可能从自适应编译中获取提高性能和降低编译暂停得收益。
本论文剩余部分,我们会描述这些技术得设计和实现,并且评估它们对于 SELF 系统的性能影响。所有的技术都全部实现并且足够稳定地成为了公共 SELF 发布包的一部分。第二章呈现 SELF 的概述和随后章节描述的工作概述,以及讨论相关工作。第三章讨论如何动态分发可以被运行时系统优化,例如,编译器外。第四章描述非优化的 SELF 编译器和评估它的性能。第五章描述类型反馈如何降低动态分发的开销,第六章描述 SELF 优化编译器的实现。第七章和第八章评估新的 SELF 编译器对于之前SELF系统的性能,对其它语言的性能,以及调查硬件特性对性能的影响。第九章讨论优化编译器怎么对系统交互行为产生影响。第十章描述我们的系统怎样提供全源码级的调试且不影响编译器的优化性能。
如果你非常的匆忙且已经很熟悉之前的 Smalltalk 或者 SELF 的实现,我们建议你可以跳过第二章(简介),然后阅读每一章末尾的总结,加上结论。
143页的词汇表包含了本文大部分重要术语的简短定义。
2. 背景和相关工作
这个章节展现本论文的一些背景和相关工作。首先,我们简短的介绍 SELF 语言和它的目标,其次是 SELF 系统的概述。然后,我们的新系统的编译过程,最后我们会回顾相关的工作。
2.1 SELF 语言
SELF 是一个 动态类型,基于原型和面向对象的语言,最初的设计是1986年 David Ungar 和 Randall B. Smith 在 Xerox PARC 做的。想要作为 Smalltalk-80 编译语言的一个备选,SELF尝试最大化程序员在探索性编程环境的生产力通过保持语言的简单性和纯净,而不降低表达能力和扩展性。
SELF 是一种纯粹的面向对象语言:所有的数据都是对象,且所有计算的执行都是通过动态绑定消息发送的(包括所有的实例变量访问,即使在接收者对象里)。因此,SELF合并状态和行为i:语法上,方法调用和变量访问是不区分的–发送者不知道消息是简单数据访问的实现还是方法的实现。于是,所有的代码时表达独立的,因为相同的代码可以被不同结构的对象重复使用,只要这些对象正确实现期望的消息协议。换句话说,SELF支持全抽象数据类型:只有对象的接口是可见的,所有的实现细节如对象的大小和结构都被隐藏,即使代码在对象本身里。
SELF 其它主要的重点如下列表:
- SELF 是动态类型的:程序包含无类型的定义。
- SELF 是基于原型的而不是类。每个对象是自描述的可以被独立改变。除了这种方法的灵活性,基于原型的系统可以避免元类(metaclasses)带来的复杂度。
- SELF 有多继承。多继承设计在这些年经历了一些改变。SELF-87 只有单继承,但是 SELF-90 引入了 优先多继承结合一个新的隐私机制为了更好的封装和一个“发送者路径判定”规则为了消除相同优先级父节点的歧义。最近,钟摆又摆回了简单性:SELF-92 消除了发送者路径判定因为它倾向于隐藏歧义,而 SELF-93 消除了优先级继承和来自语言的隐私。
- 所有的控制结构式用户定义的。例如,SELF没有 if 语句。作为替代,控制结构通过消息发送和块(闭包)实现,就像 Smalltalk-80。但是,不同于 Smalltalk-80的是,SELF的实现没有固化任何的控制结构,换句话说,程序员可以改变任何方法(包括那些实现if语句,循环和整型加法的方法)的定义,系统会忠实地反射这些变化。
- 所有的对象是堆分配的且被垃圾回收器自动解除分配。
这些特性被设计来发挥现代计算机的计算能力,使得程序员的生活更简单。例如,表达独立性使得重复使用和重组代码变得简单,但是产生了实现问题,因为每个数据访问都关联了一个消息发送。比起关注最小程序窒执行时间,SELF更关注于最小编程时间。
2.2 SELF系统
SELF系统的实现目标反映了语言:最大化编程生产效率的特点。几个特性为这个目标做出贡献:
- Source-level sematics。系统的行为总是可以用源语言级别的术语解释。程序员应该从不面对一些如 “segmentation fault”,”arthmetic exception: denormalized float“ 的错误,因为这些错误在缺少对底层实现细节的深入了解是无法解释的,这些实现细节超出了语言的定义因此难以理解。因此,所有的 SELF 原语都是安全的:算术操作测试溢出,数组访问执行下标边界检查等。
- Direct execution sematics(interpreter semantics)。 系统应该总是表现如同直接执行方法源码:任何源码改变都是立即生效的。直接执行语义使得程序员免于担心不得不显式调用编译器和链接器,免于不得不处理编译依赖等枯燥的细节。
- Fast turnaround time。 在做出变化之后,程序员不会因为慢速编译器和链接器而等待;这类的延迟应该尽可以能得短(理想下,只是几分之一秒)。
- Efficiency。最后,程序应该总是有效率的运行不受 SELF纯度的影响:程序员不应该因为选择 SELF 而不选择更传统的语言而受惩罚。
这些目标不是轻易能达成的。特别是,因为强调成为程序员正确的语言而不是成为机器的语言,SELF 是很难实现的有效率的。几个关键的语言特性创造了特别难的问题:
- 由于所有的计算都是由消息发送执行的,在底层实现中调用频率极其高。如果简单和通用的计算,这些在传统的编译器中通常只需要单条指令(如一个实例变量访问或者一个整形加法),都调用动态分发的过程调用,程序将会比传统语言运行慢上许多,即使没有一百的慢。
- 相似的,由于没有内置的控制结构,一个简单的 for 循环涉及数十条消息发送和几个块(闭包)的创建。因为控制结构的定义可以被用户改变,编译器不能走捷径地将它们的翻译和手写优化代码模式硬关联在一起。
- 因为总体目标是最大化程序员生产率,系统应该有高频的交互和提供立即的反馈给用户。因此,长的编译暂停(出现在优化编译器中的)是无法接受的,进一步限制了实现者在找寻有效的 SELF 实现的自由。
下面的章节给出当前SELF实现的概述和它是怎样尝试解决上面描述的问题的。在描述基础系统之后,我们会强调新的解决方案,这是这篇文章的主题,以及它们怎么适配已经存在的系统。
2.2.1 实现概述
SELF 虚拟机有如下几个子系统组成:
- 一个 memory system 处理分配和垃圾回收。对象被存放在堆中;一个分代的扫描垃圾回收器回收不使用的对象。对象引用通过两个比特位标签标记在每个32位字的低两位上(标签00 是整形,01 是指针,10 是浮点,11是对象头)。所有的对象处理整形和浮点由至少两个字组成:一个字表示header,一个指针指向对象 map。一个 map 描述对象的格式,可以被看成是对象低级别类型。有相同格式的对象共享相同的map,所以对象的布局信息只会被存储一次。为保持语言规定的自描述对象的抽象,map是写时拷贝:l例如,当一个槽被添加到一个对象时,这个对象会得到一个新的map。
- 一个 parser 读取文本描述的对象,以及将其转化为真的对象存储到堆。方法被表示为简单的字节码集合(本质上是,“send”,”push literal“,和”return“)。
- 给予一个消息名和一个接送者,**lookup system** 决定查找的结果,例如,匹配槽。查找首先检查哈希表(代码表)找寻编译过的代码是否存在。如果存在,代码就被执行;否则,系统执行实际的对象查找(如果需要的化遍历接受者的父对象),然后调用编译器生成机器码来执行方法或者数据访问。
- compiler 转换一个方法的字节码为机器码然后存储到**code cache**。 如果代码缓存中已经没有空间给新的编译过的方法,已经存在的方法会被清理来获得空间。代码缓存保存近似 LRU 信息来决定哪个编译过的方法被清理。
- 最后,虚拟机也包含许多的原语,可以被 SELF 程序调用来执行算术计算,I/O,图形绘制等。新的原语可以在运行时被动态链接到系统。
参考[88],[115],和[21]包含更多的系统细节。
2.2.2 效率
因为 SELF 的纯语义威胁让程序效率极其低下,许多早期的实现尽力使用编译技术优化 SELF 程序。这些技术中有些是非常成功的:
Dynamic compilation 。 编译器按需动态的翻译源方法成编译过的方法。这意味着没有分离的编译过程,执行和编译是交错的。(SELF 动态编译的使用灵感来自 Deutsch-Schiffman Smalltalk system[44]。)
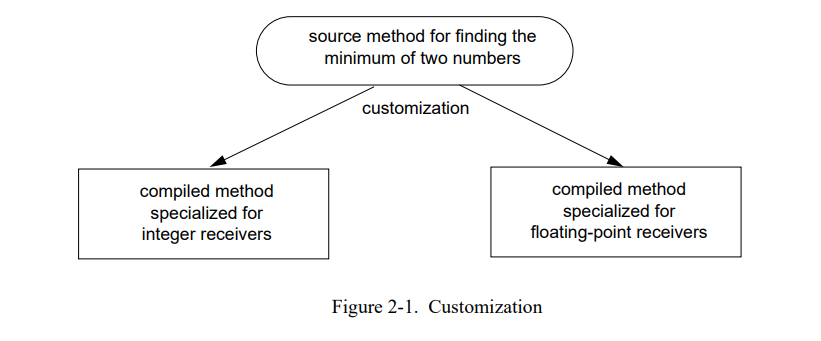
Customization。 定制化允许编译器决定一个方法中许多消息接送者的类型[23]。它利用方法的许多消息是发送给 self 的事实来扩展动态编译。编译器根据每个接送者类型为一份源码创建不同版本的编译代码(Figure 2-1)。例如,方法min:源方法计算两个数的最小值,会被创建为两个不同的方法。这个复制允许编译器客制化每个版本到特定的接受者类型。特别是,在编译时知道 self 的类型使得编译器可以内联所有的发送 self。客制化在 SELF 中是非常重要的,因为许多消息是发送给 self,包括实例变量访问,全局变量访问,和许多用户定义的控制类型。
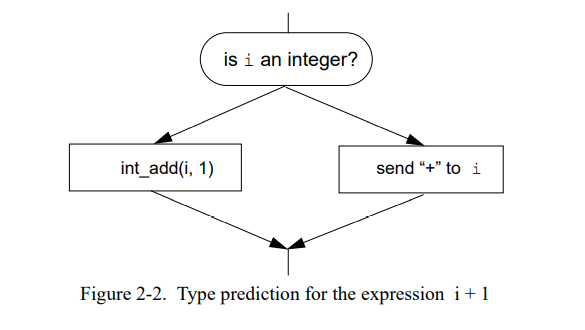
Type Prediction。确定的消息几乎只发送给特定的接受者类型。对于这样的消息,编译器使用最早由 Smalltalk 系统引入的优化[44,132]:它预测接受者的类型基于消息名字并且插入运行时类型检测于消息发送前用于测试期望的接送者类型(Figure 2-2)。类似的优化在 Lisp 系统中被用于优化通用计算。沿着类型测试成功的分支,编译器有关于接受者类型的精确信息可以静态地绑定和内联一个消息的拷贝。类如,现有的 SELF 和 Smalltalk 系统预测 ‘+’ 会被发送给整形 [128,58,44],因为测量显示 这个类型 90% 的时间会出现 [130]。如果测试的开销是比较低且成功的可能性比较高,则类型预测会提高性能。
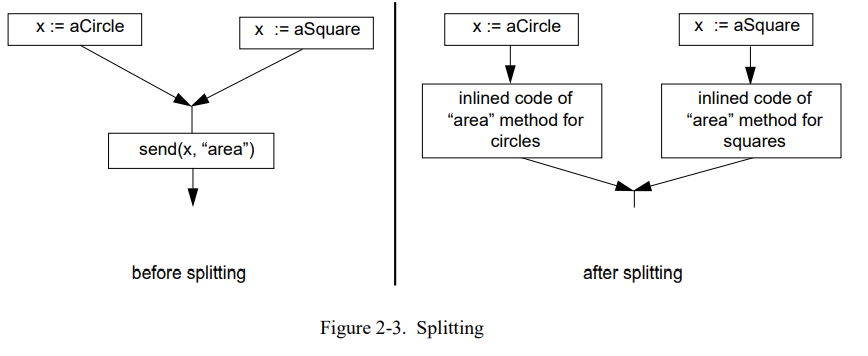
Splitting 是另外一种方法,将一个多态的消息转变为多个分离的单态消息。通过拷贝部分的控制流图 [23,22,24] 避免类型测试。例如,一个对象在 if 语句的一个分支上是一个整形,而在另一个分支上是浮点(Figure 2-3)。如果这个对象是 if 语句之后的消息发送的接收者,编译器可以拷贝这个发送到两个分支。因此在每个分支上都是确定的接受者类型,编译器可以分别内联这两个发送的拷贝。
合并在一起,这些优化将 SELF的性能提升到合理的水平。举个例子,Chambers 和 Ungar 报告了 SELF 显著地跑赢了 ParcPlace Smalltalk-80 的实现在一个小的类C的整形测试用例集上[26]。
2.2.3 源码级的语义
语言和实现特性的结合确保了所有程序的行为,即使错误的部分,也可以通过源码级别的术语独立理解。语言保证了每个消息发送要么找到一个匹配槽(访问它的数据或者运行它的方法),或者导致一个“message not understood” 的错误。最后,这个级别的唯一错误是查找错误。此外,实现保证了所有的原语是安全的。因为所有的原语会检查它们的操作数和结果,如果操作数无法被执行会以明确的方式失败。例如,所有的整型算术原语检查溢出,数组访问原语检查范围错误。最后,因为 SELF 不允许指针算术和使用垃圾回收,所以系统是指针安全的:不会偶然地复写随机的内存区域或者解引用悬挂指针。这些特性的结合让它更容易找到程序错误。
安全原语让高效实现更难[21]。例如,每个整型加法不得不检查溢出,从让它变慢。更重要的是,整型操作的返回值类型是未知的:所有的原语都有 “故障块” 的参数,如果操作失败,一个消息会被发送给这个参数。然后这个发送的结果会变成原语调用的返回值。例如,当前 SELF 系统的整型的 “+” 方法调用 IntAdd:带有失败块的原语会将失败块参数转化为任意精度的整型然后进行相加。因此表达式 x + y 的精确的返回值类型是未知的,即使 x 和 y 都是已知的整型:没有溢出,返回值会是整型,但是当结果太大而不能被表示为一个机器级别的整数时,结果就会时任意精度的整数。因此,即使 x 和 y 是已知的整数,编译器也无法静态的知道表达式 x + y + 1 的第二个 “+” 会调用整型的加法还是任意精度数的加法。安全原语帮助程序员的同时也潜在地使执行变慢。
2.2.4 直接执行语义
SELF 通过使用动态编译模仿解释器。每当一个没有相关编译过代码的源码方法被调用,编译器会被自动调用生成缺失的代码。反过来,每当用户改变源方法,所有依赖于旧定义的编译过代码会被无效化。为了实现这个系统在源码方法和编译过的方法维持一个依赖链接[71,21]。
因为没有显式的编译和链接步骤,传统的编写-编译-链接-运行循环被简化为一个编写-运行循环。程序可以在运行时被改变,所以应用可以被在线调试而不需要从头开始运行。
2.3 编译过程概述
Figure 2-4 较详细地展示了新的 SELF-93 系统的编译过程。SELF 的方法源码以对象的形式存储到堆上,就像其它的数据对象一样。方法的代码被编码为一个简单栈式机器的一串字节码(“instruction”)。这些字节码可以在解释器上直接执行;但是当前的 SELF 系统从没有这样做。反而,这些字节码总是按需地被翻译为机器码。当一个源码第一次被执行,机器码被实时生成。通常,第一次编译的代码是由“快速但笨”的编译器生成的。未优化的代码是字节码的直接翻译所以相当的慢;章节4 更细节地描述非优化的编译器。
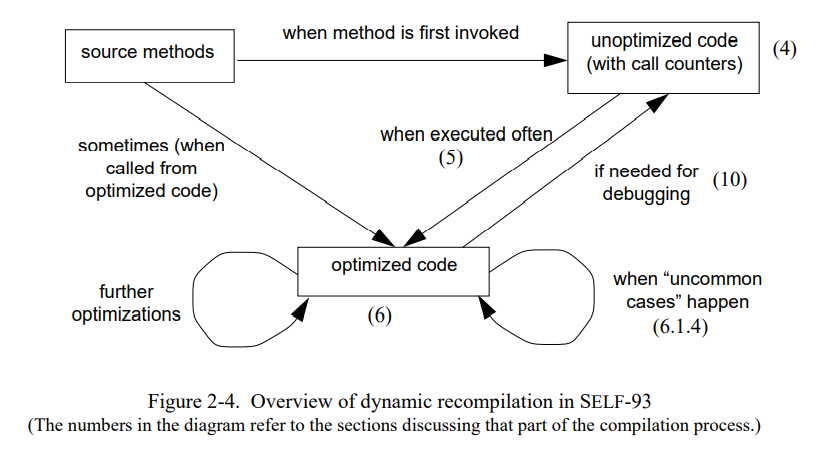
未优化的代码包含一个调用计数器。每当计数器超过一定的阈值,系统会调用重编译系统来决定是否优化是需要的以及应该重新编译哪些方法。然后重编译系统调用优化编译器。章节5详细的解释了重编译过程,章节6描述优化编译器。
作为我们工作的一部分,我开发了一个新的内联缓存的变种,多态内联缓存(polymorphic inline caches(PICs))。PICs 不仅加速多态调用点的运行时分配,也为编译器提供接收者类型的值信息。章节3描述PICs怎么工作的,章节5解释了优化编译器怎么利用 PICs 中的类型反馈信息。
在一些例子中,优化方法会再被重新编译。例如,重编译系统可以因为第一次优化后的方法仍然包含许多可以被内联的调用(比如,第一次优化编译的时候没有足够多的类型信息而不能内联)而决定重新编译。一个优化过的方法也会被重新编译当它遇到 “uncommon cases”:编译器可能预测某些场景从不会出现(如,整型溢出)而忽略了这种场景的代码生成。如果这种被忽略的场景刚好出现,原始优化过的方法就会被重新编译,扩展成处理这些特殊场景的代码(章节6.1.4)。
在本文的剩余部分,我们会按通常的顺序讨论系统的每个组件:首先,多态内联(PICs)和非内联编译器,然后重编译系统,最后是优化编译器本身。
2.4 本工作的收益
本文所描述的所有技术都在 SELF-93 系统中实现了,在如下几个方面有了提升:
- Higher performance on realistic programs。通过自动重编译和程序关键性能段的重新优化,我们的优化编译器可以利用运行时收集的信息。这些额外的信息经常使得编译器产生比之前代码更有效率的代码,即使编译器只执行很少的编译时程序分析。例如,DeltaBlue 约束求解器,当前的代码比之前版本的优化编译器产生的代码快三倍(章节7)。
- More stable performance。新的编译器更多的依赖于动态观察到的程序行为和更少的静态分析,因此不太会受到静态分析技术盲点的影响。脆弱的性能是前一代 SELF 编译器的主要问题:小的源文件改变会导致戏剧性的性能损失,因为改变可能会导致一个特别重要的优化失效。例如,Stanford ineger benchmarks 的一组小改变在前一代 SELF 编译器编译下会减慢 2.8 倍,而在新的编译器下编译只降低 16%(见章节7.4)。
- Faster and simpler compilation。我们的方法依赖于运行时系统的动态反馈而不是使用复杂的静态类型分析技术在更好的运行时性能上有额外的优势。首先,它导致一个简单的编译器(11000 对比 26000 非注释源行代码)。第二,新的编译器比之前的编译器快2.5倍(见9.5节)。对于用户,编译暂停降低了更多(见9.2节)因为系统只是优化一个应用的关键路径。
- Support for source-level debugging。在之前的 SELF 系统,用户可以打印优化程序的栈,但是他们不能在运行的时候改变程序,还有他们也不能执行诸如单步调试等通用的调试手段。我们的新系统提供随时的退优化功能让调试员的工作更简单(见第十章节)。
2.5 相关工作
本节比较 SELF 系统和常见的相关工作;后续章节给出更多的比较细节。
2.5.1 动态编译
SELF 使用动态编译,例如,运行时实时生成代码。动态生成编译代码而不是使用传统的批量式编译的思路源自于快速解释器的需求不断增加;通过编译到本地代码,一些解释器的固定开销(特别是伪指令的解码)可以被避免。例如,假设变量的类型保存不变,Mitchell[97] 建议可以将动态类型解释式程序的一部分转为编译形式。编译过的代码第一次被生成是作为一个表达式解释时的副作用产生的。类似地,线程代码[12]最早被用于消除一些解释过程的固定开销的。
传统上使用解释器或者动态编译器有两个原因:第一,一些语言很难被有效的静态编译,通常是因为独立的源程序没有足够的低级别的类型实现信息来生成高效的代码。第二,一些语言过于强调交互使用因此被实现为解释器而不是慢速编译器。
APL 是一种既难于进行静态编译(因为许多操作是多态的)且强调交互使用的语言。不出意外的话,APL 系统是最早探索动态编译的系统之一。例如,Johnston[80] 描述了一个使用动态编译作为解释的一个高效替代的 APL 系统。这些系统使用的一些机制类似于客制化(如,Guibas and Wyatt[61])和内联缓存(Saal and Weiss[111])。
Deutsch 和 Schiffman 在面向对象语言开创性地使用了动态编译。他们的 Smalltalk-80 的实现动态翻译了 Smalltalk 虚拟机定义的字节码到本地机器码并进行缓存供后续使用;Deutsch 和 Schiffman 估计仅仅使用简单的动态编译替换解释就加速了他们的系统 1.6 倍,使用更复杂的编译器则会有将近 2 倍的收益。
Franz[55] 描述了一个在加载时将紧凑的中间代码表示转为机器码的动态编译的变种。就像 Smalltalk ”snapshot“ 中的字节码,中间表示代码是架构独立的,同时,它也尽量是语言独立的(当前的实现只有Oberon支持)。从中间码到机器码的编译是足够快的使得当前加载器与常规加载器相比差异不大。
动态编译除了语言实现之外对于应用也是有用的[82],它已经在多种方式下被使用。例如,Kessler et al. 用它来实现调试器的快速断点[84]。Pike et al. 通过动态生成最佳代码序列来加速 “bit-blt” 图形原语[103]。在操作系统中,动态编译被用来高效支持细粒度并行[32,105]和消除协议栈的开销[1],以及动态链接[67]。动态编译也在其它领域被使用,如数据库查找优化[19,42],微代码生成[107],快速指令集仿真[34,93]。
2.5.2 客制化
客制化部分编译代码到特定环境的想法与动态编译密切相关因为环境信息直到运行前不总是有效的。例如,Mitchell 的系统[97] 特殊化算术操作到操作数的运行时类型。当变量的类型改变了,所有的依赖于这个类型的编译代码都会被丢弃掉。因为这个语言不支持用户自定义多态且不是面向对象,这个方案的主要动机是降低解释过程的固定开销和将一些通用的内置操作替换为简单的,特定的代码序列(如,用整型加法替换通用加法)。
相似地,APL 编译器为某些表达式创建特定的代码[80,51,61]。对于这些系统,HP APL 编译器[51]最接近 SELF 使用的客制化技术。HP APL/3000 系统按一条一条语句的方式编译代码。除了执行 APL 特定的优化,编译过的代码被特定化根据特定的操作数类型(维数,每一维的大小,元素类型,存储布局)。这些所谓的”硬“代码比起通用的版本可以更高效地执行因为一个APL操作执行的计算可能会因实际参数类型而有很大差异。为了保持语言的语义,在编译表达式的时候,特殊代码之前会有一段验证导言(prologue)保证参数类型确实符合之前给出特定的假设。因此,编译生成的代码可以在之后的表达式执行中安全地重复使用。如果类型是相同的(希望这是常见的情况),无需在进一步编译;如果类型不同,一个新的更少约束性假设的版本会生成(所谓的“软”代码)。从系统的描述中,老的”硬“代码是否会保留是不清楚的,多个硬版本是否可以同时存在也是不清楚的(不同场景的特定化版本)。
客制化也被用于传统的,面向批处理的编译器。例如,Cooper et al. 描述一个 FORTRAN 编译器会创建程序的客制化版本来使能某个循环优化[36]。Nicolau 描述了一个 FORTRAN 编译器会动态地选择一个合适的静态生成的循环版本[99]。Saltz et al. 延迟循环调度直到运行时[112]。Przybylski et al. 为不同的模拟参数集合生成特定的缓存模拟器[104]。Keppel et al. 讨论为不同的应用生成值特化的特定化运行时[83]。在许多面向理论的计算机科学领域,客制化被称为局部求值[15]。
2.5.3 先前的 SELF 编译器
本论文描述的 SELF 编译器有两个前代。第一个 SELF 编译器[ 22,23] 引入客制化和分离,取得相当不错的性能。对于 Stanford integer benchmarks 和 Richards benchmark,程序运行比优化过的 C 慢 4-6 倍,同时比最快的 Smalltalk-80 系统快两倍。编译器的中间码是基于树的,这让它难以显著地提高代码质量因为没有显式的控制流表示。例如,难以找到给定节点的后继(控制流术语),这让跨几个节点的优化难以实现。编译速度通常很好但会有很大的波动因为有些编译器算法的编译时间与源代码大小不是线性的。但是,编译暂停很明显,因为所有的源码都会被全量优化。这个编译器用了 9500 行 C++ 实现。
第二个编译器[21,24](叫 SELF-91)被设计来移除第一个编译器的一些限制且进一步提高了运行时性能。它引入了迭代类型分析和一个更复杂的后端。因此,它在 Stanford integer benchmarks 上取得显著的性能(达到了优化过的C的一半性能);但是,在 Richards benchmark 上的性能没有显著地提高。不幸的是,用户也在他们的程序上遇到相同的差异:一些程序(特别是小整型循环)表现为良好的性能的同时,许多大程序表现并不好(我们会在7.2节详细地讨论这个差异的原因)。编译器执行复杂的分析和优化也带来了编译时间的开销:比起前一代 SELF 编译器,编译慢了几倍。且当前的编译暂停会导致更多的用户不愿意使用新的编译器。比起前一代的编译器,SELF-91 编译i器相当复杂,用了 26000 行 C++代码实现。
2.5.4 Smalltalk-80 编译器
Smalltalk-80 可能是最接近 SELF 的面向对象的语言了,有几个项目在调研加速 Smalltalk 程序的技术。
2.5.4.1 Deutsch-Schiffman 系统
Deutsch-Schiffman 系统[44]代表着最先进的商业 Smalltalk 实现。它包含了一个简单但快速的动态编译器只执行窥孔优化没有内联。但是,不像 SELF,Smalltalk-80 的实现硬编码了某些重要的方法,如整型加法,消息实现的 if 语句,和某些循环。因此,Deutsch-Schiffman 编译器可以为这些结构生成高效的代码,否则只能通过类似于 SELF 编译器做过的优化来实现。Deutsch-Schiffman 编译器大约使用 50 条指令来生成一条编译过的机器指令[45],因此编译器暂停几乎不可见。
除了动态编译,Deutsch-Schiffman 系统还开创了几项优化技术。内联缓存通过缓存最后的查找结果加速消息查找(见第三章)。因此,许多发送的开销可以降低到一个调用的开销和一个类型测试的开销。SELF 也使用内联缓存,且多态内联缓存扩展了它的用处到多态调用点(见第三章)。类型预测加速了普通发送通过预测可能的接送者类型(见 2.2.2节)。所有的 SELF 编译器除了第四章描述的非优化的 SELF 编译器都不同程度的使用了类型预测。优化的 SELF 编译器通过基于类型反馈信息的动态预测接收者类型扩展了静态类型预测(第五章)。
2.5.4.2 SOAR
SOAR(“Smalltalk On A RISC”) 项目通过软硬协同的方式加速了 Smalltalk[132,129]。在软件方面,SOAR 使用了非动态的本地代码编译器(如,所有的方法在解析之后都会被编译成本地代码),内联缓存,类型预测,和一个分代扫描垃圾回收器[131]。就像 Deutsch-Schiffman 编译器一样,SOAR 编译器不执行昂贵的全局优化或者方法内联。在硬件方面,SOAR 是 Berkeley RISC II 处理器的变种[98];最重要的硬件特性是寄存器窗口和标记整型指令。比起其它的 Smalltalk 在 CISC 上的实现,SOAR 软硬件特性的结合是非常成功的:在一个 400ns 的时间周期里,SOAR 与 70ns的微指令 Xerox Dorado 工作站,但比跑在周期时间为 200ns 的 Sun-3 上的 Deutsch-Schiffman Smalltalk 系统快 25%。但是,我们会在第八章中看到SELF系统使用的优化技术极大地降低了特殊支持硬件的性能收益。
2.5.4.3 其它 Smalltalk 编译器
其它的Smalltalk 系统尝试通过标注类型声明来加速程序。Atkinson 部分实现了一个 Smalltalk 编译器,其使用类型声明作为提示来生成更好的代码[11]。例如,如果程序员定义一个局部变量为 “class X” 类型,编译器会查找这个变量的消息发送然后内联调用方法。为了代码安全,编译器在内联代码之前插入了类型检查;如果当前的值不是 class X 的实例,一个非优化的,无类型的方法会被调用。虽然,Atkinson 的编译器一直不是完全的,它可以运行小的用例得到与 Sun-3 上的 Deutsch-Schiffman 系统相比,速度提高了大约两倍。当然,为了获得加速,程序员不得不小心地在代码里标注类型,只有调用使用了正确的类型才会被加速。
TS 编译器[79]使用了类似的方法。类型被指定为一组类,当接送者类型是单类编译器可以静态绑定调用。方法可以单一内联如果程序员标记它们是可以内联的。如果接受者类型是一小组类,编译器为每个类插入类型检查然后分别优化各个分支。这些优化可以被看做是类型预测的一种形式,它是基于程序员提供的类型声明,而不是编译器硬连接的消息列表和预期类型。但是,不像类型预测和Atkinson 的编译器的是,程序员的类型声明不是一种提示而是一种坚定的承承若(这些承诺的有效性通过类型检查器来检查,但是检查器一直式不完善的,因此无法分析 Smalltalk 系统的重要部分)。
TS 编译器的后端使用 RTL-base 中间形式进行粗放的优化。因此(还有它本身是用 Smalltalk 编写的),编译器非常的缓慢,编译一个非常小的 benchmark 需要 15 到 30 秒[79]。有效的关于高效代码生成的公开发布的数据非常少,因为 TS 编译器从没有完整过,只能编译非常小的 benchmark 程序。在 68020-base 的工作站上关于 TS 和 Tektronix Smalltalk 解释器的比较数据显示对于小 benchmark ,TS 是 Deutsch-Schiffman 系统的两倍快,这是标注了类型声明的TS[79]。但是比较不是完全有效的因为 TS 没有实现一些 Smalltalk结构的完全语义。例如,整型计算没有溢出检查。这个对于小的 TS benchmark 的性能会有显著影响。例如,sumTo benchmark的循环(从1到10000一次相加)只包含很少的指令因此溢出检查会有显著的开销。更重要的是,累积求和的结果的类型会无法用 SmallInteger 表示,因为 SmallInteger 运算的结果不一定就是 SmallInteger(当溢出发生,Smalltalk-80 原始故障代码将参数转换为任意长度的整数并返回这些参数的总和)。因此,求和的类型声明(上边界)不得不更通用,这个会显著降低生成的代码的运行速度。
3. 多态内联缓存
面向对象的程序发送许多的消息,因此发送必须很快。本章首先回顾动态类型语言里已经存在的知名的提高查找效率的技术,然后描述多态内联缓存,这是我们开发的一个标准内联缓存的扩展版本。
3.1 离线查找缓存
面向对象语言用消息发送替换过程调用。发送动态绑定消息比起调用静态绑定过程花费更多因为程序必须根据接收者的类型和语言的继承规则查找正确的目标函数。虽然早期的 Smalltalk 系统有简单的继承规则和相对慢速的解释器,方法查找(也叫消息查找)仍然占据执行时间的大部分。
Lookup caches 降低了动态消息绑定的固定开销。一个查找缓存映射了一组(接受者类型,消息名)到目标方法且保存了大部分最近使用的查找结果。消息发送首先用给定的接收者类型和消息名为索引查询缓存。当缓存探测失败它们才会调用(昂贵的)查找函数通过遍历继承图来查找目标函数,然后存储结果到查找缓存,可能会将比较老的查找结果替换掉。查找缓存能有效的降低查找的固定开销。例如,Berkeley Smalltalk,没有查找缓存会慢 37% [128]。
3.2 调度表
静态类型的语言总是通过调度表实现消息查找。一个通用的变种是使用消息名(编码为整数)来索引特定类型消息表,这个表包含了目标函数的地址。然后一个消息发送会包含调度表的加载地址(被存放到每个对象的第一个字中),索引到这个表来获得目标函数的地址,然后调用这个函数。
调度表在静态类型语言中是容易实现的因为表索引的范围,发送给一个对象的可能的消息集合,是静态已知的,因此这些表的大小(和内容)是容易计算出来的。但是,在动态类型语言中也是可能可以使用调度表的,尽管需要一些加法计算[7,50,135]。这些方法的主要缺陷是它们难以被整合进一个交互系统因为当引入新的消息或者类型时,调度表需要定期地被从新排布;在一个大的系统如 Smalltalk-80,这种从新排布需要花费许多分钟,且调度表会消耗几百KB内存。因此,我们不对调度表做进一步的讨论。
3.3 内联缓存
即使用了查找缓存,发送一条消息仍花费比调用一个简单过程的时间来得长因为许多消息发送都需要先探测缓存。即使在理想场景下,一个缓存查找关联了连续得十条指令来获得接送者类型和消息名,形成缓存索引(例如,通过异或和移位接收者类型和消息名),获得缓存条目,然后比较这个条目和实际的接受者类型和消息名来验证缓存的目标函数是确实是正确的。这个情况下,查找缓存是 100% 有效的(访问都命中),发送仍然相当地慢因为每次发送查找缓存的探测都要加上十条指令。
幸运地是,消息发送可以加速因为看到了在一个给定的调用调用点的接收者类型是很少变化的;如果在一个特定的调用点一个消息被发送给一个类型X的对象,下一次这个发送被执行大概率仍然是X类型的接收者。例如,Smalltalk 代码的几个研究表明,一个给定调用点的接收者类型 95% 的时间里是保持不变的[44,130,132]。
这种类型使用的局部性可以通过在调用点缓存要查找函数的地址来加以利用。因为查找结果被缓存“在线”在每个调用点(例如,在命中场景下不会访问单独的查找缓存),这个技术叫**inline cahcing**[44,132]。图 3-1 显示了空的内联缓存;调用函数简单的包含一个系统查找例程。第一次这个调用被执行,查找例程会找到目标方法。但是在跳到目标前,查找例程改变调用指令去执行刚找到的目标方法(图 3-2 )。随后发送执行直接跳到目标方法,完全避开任何查找。当然,接收者的类型可以被改变,所以被调用方法的导语必须验证接收者类型是正确的,如果类型测试失败调用查找代码。
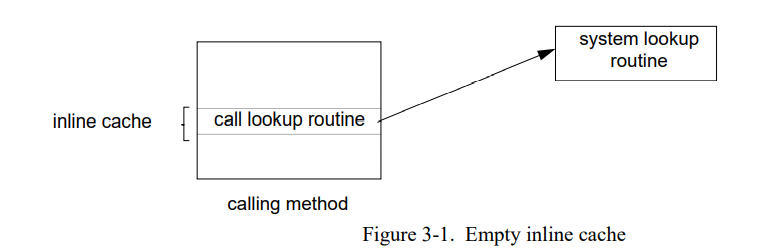
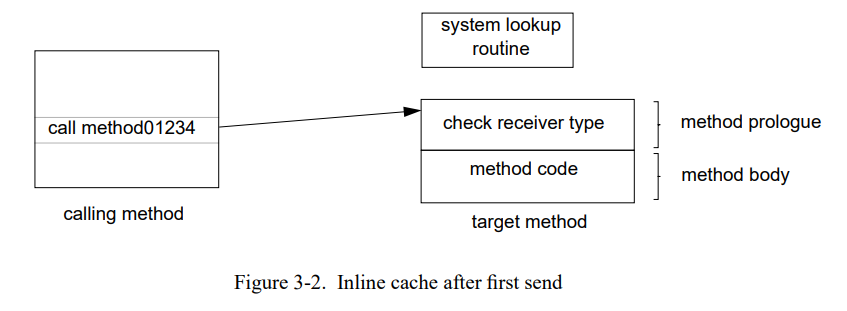
因为以下一些原因内联缓存比离线查找缓存快得多。首先,因为每个调用点都有分离的缓存,不需要测试消息名来验证缓存是否命中–只有在未命中的时候测试才必须做(通过系统查找例程)。第二,内联缓存不需要执行任何的加载指令来获取缓存条目;这个功能通过调用指令隐式地执行了。最后,因为没有显示地索引到任何表,我们可以忽略哈希函数的异或和移位指令。唯一的开销是接收者类型的检查通常用非常少的指令完成(在一个典型的 Smalltalk 系统是两个加载和一个比较跳转,在SELF系统是一个加载和一个常量比较)。
内联缓存在降低查找开销上非常的有效因为命中率高且命中开销小。例如,SOAR(一个RISC处理器上的Smalltalk实现)没有内联缓存会慢33% [132]。我们已知的所有的编译实现的Smalltalk都包含内联缓存,包括 SELF 系统。
3.4 处理多态发送
仅当调用点的接收者类型(和调用目标)保持相对固定内联缓存才有效。虽然内联缓存对主要的发送都工作的很好,但是它不能加速有着几个接收者类型的多态调用点因为调用目标会在几个不同的方法来回切换。
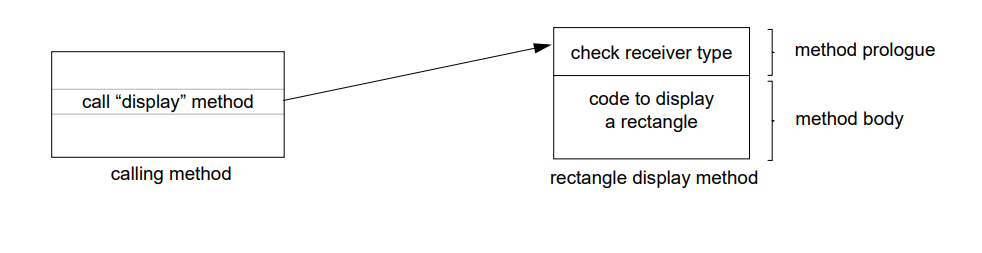
例如,假设一个方法是发送 显示 消息到一个表中的所有元素,然后表中的第一个元素是长方形:
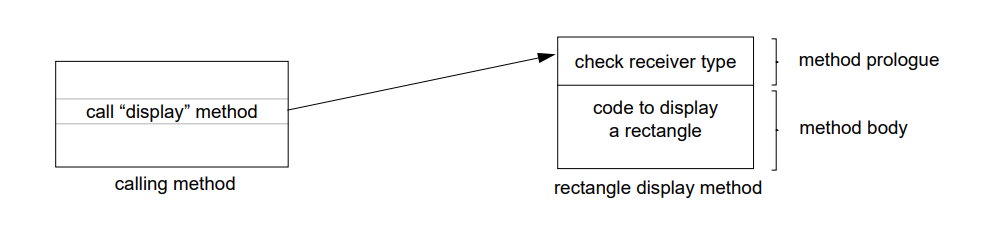
如果表中下一个元素是圆形,控制通过内联缓存中的调用即长方行的显示方法。方法导语中的接收者测试检测到类型错误然后调用查找例程重新绑定内联缓存到圆形的显示方法:
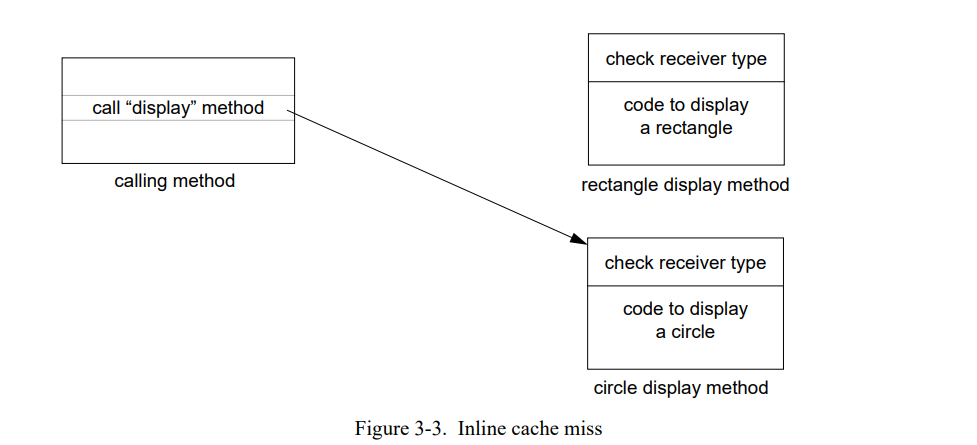
不幸地是,如果表中包含的圆形和长方形不是特定的顺序,内联缓存会一次又一次地失败因为接收者类型总是改变。在这个例子中,内联缓存可能比使用离线缓存更慢因为失败次数太多了。特别是,在大部分呢现代处理器中失败代码其中包含改变调用指令需要无效化指令缓存的部分内容。通常,失败处理也包含相当大的额外开销。例如,SELF 系统链接所有的调用特定方法的内联缓存到一张表如此当方法被重定位到不同的地址或者被丢弃它们可以被更新。
内联缓存失败导致的性能影响在高性能系统中变得更严重,以至于不能在被忽视。例如,SELF-90 的评测显示 Richards benchmark 花费 25% 的时间来处理内联缓存失败[23]。
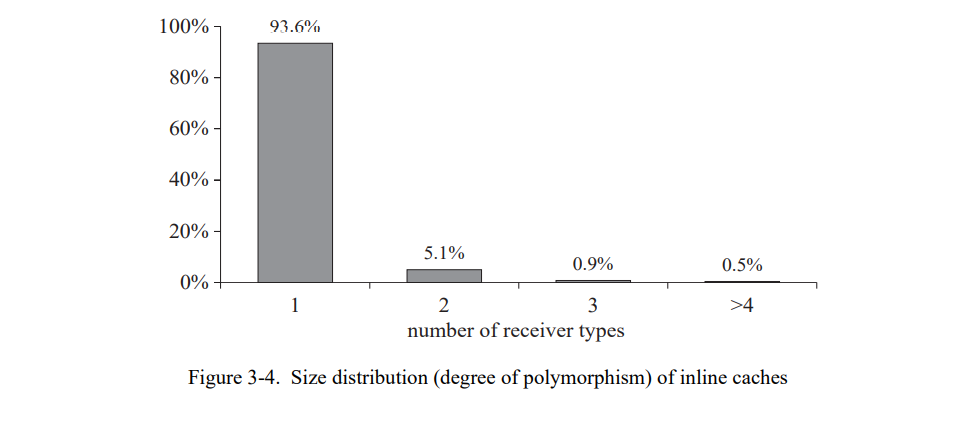
SELF 系统上的一个非正式的多态调用点测试显示大部分的用例多态的度都是比较小的,通常小于十。发送的多态性的度符合三峰分布:大部分的发送是单态的(只有一个接收者类型),部分是多态(少量的接收者类型),非常少的是巨态的(非常多的接收者类型)。图 3-4 显示非空内联缓存的数量分布,例如,调用点展示的多态性的度。这个分布是在使用原型 SELF 用户接口[28]一分钟后获得的。极大部分的调用点都只有一个接收者类型;这是通常的内联缓存也能工作得很好的原因。相当少的调用点有两个不同的接收者类型;一个常见的例子是布尔消息,因为对和错在SELF中是两个类型。极少的调用点有多于五个的接收者类型。(所有的超过十个接收者类型的调用点只有块;节4.3.2 解释了这个巨型态行为。)图 3-4 多态调用的性能可以通过一个更自由的缓存形式来提高因为大部分非单态的发送只有少量的接收者类型。
3.5 多态内联缓存
为了降低内联缓存失败的开销,我们设计和实现了多态内联缓存,一钟内联缓存的新的扩展技术用来高效处理多态调用点。不仅仅是缓存最后的查找结果, 一个多态内联缓存(PIC)为一个给定的多态调用点缓存了几个查找结果到一个专门生成的桩例程里。
在我们发送显示消息到列表元素的例子中,一个系统初始化使用 PICs 就像正常的内联缓存一样:在第一次发送后,内联缓存绑定到长方形显示方法上。
但是当遇到第一个圆形时,不是简单地切换调用目标到圆形的显示方法而是失败处理过程会构造一个短的桩例程然后重新绑定调用到这个短的例程上:
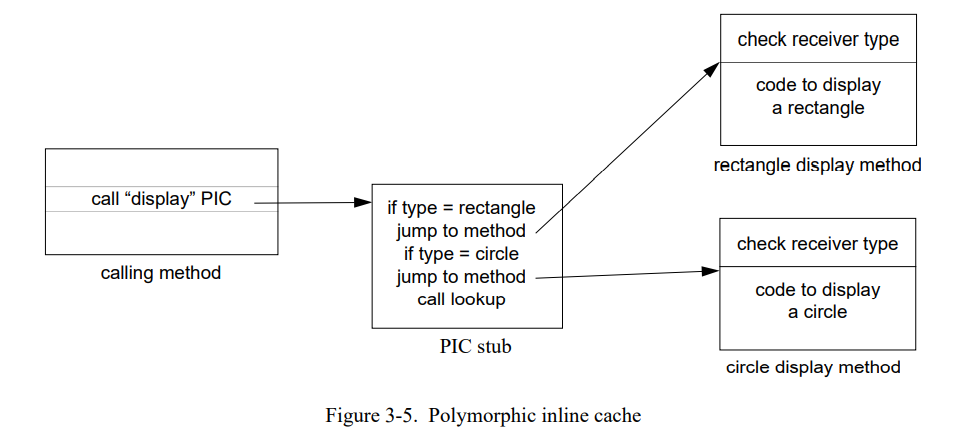
桩(类型匹配)检查接收者是长方形还是圆形然后跳转到对应的方法。这个桩可以直接跳转到方法体中(跳过方法导语的类型检查)因为接收者类型已经验证过了。然而,方法仍然需要导语的类型检查因为它们也会被单态调用点调用此时还是标准的内联缓存。
因为 PIC 当前缓存了长方形和圆形,如果列表里只有长方形和圆形就不会再有失败发生。所有的发送都是快速的,在找到目标前只需要一到两个比较。如果缓存失败再次发生(如接收者既不是长方形也不是圆形),桩例程会简单的扩展来处理新的场景。最终,桩会包含实践中的所有场景,不会再有缓存失败和查找。
3.5.1 变化
上面描述的方案在大部分的场景下工作良好将多态发送开销降低到非常少的机器周期。这一节讨论一些固有问题和可能的解决方法。
Copying with megamorphic sends。一些发送点可能会发送一个消息到非常大的类型数量。例如,一个方法会发送 writeSnapshot 消息给系统的任意的对象。为这样的发送构建一个巨大的 PIC 浪费时间和空间。因此,内联缓存失败处理不会为超出一定类型数量用例扩展PIC;而是,标记这个调用点为巨态且采用反馈策略,可能只是传统的单态内联机制。
在 SELF 系统中,如果超出一定的大小(当前,10个) PICs 就标记为巨态。当一个巨态 PICs 未命中,它不会为了包含新的类型而增长。而是,其中一个场景会被随机选到然后被替换为新的场景。这个系统的一个早期版本使用 “move-to-front” 策略即在前面插入新的场景,往后移动其它的场景且去掉最后一个场景。但是,这个策略已经被放弃因为它的失败开销太大了(所有的10个条目都需要被改变,而不是只有一个)且它的失败率也有非常高的偶然性,例如类型循环的改变。(是的,墨菲定律是成立的–真实程序反应了这个现象)。
Improving linear search。如果每个类型的动态使用频率是已知的,PICs 可以定期重新排序从而将最频繁出现的类型放到 PIC 的开头,降低类型检查执行的平均次数。如果线性搜索不够高效,更复杂的算法如二分搜索或者某些形式的哈希可以被用于许多类型的场景。但是,因为类型的数量平均上是很小的(见图 3-4),这个优化可能不值得大力去做:对于大多数场景一个线性搜索的 PIC 是可能快于其它方法的。
Improving space efficiency。多态内联缓存是大于正常的内联缓存的因为桩例程关联了每个多态调用点。如果空间紧张,有着完全相同消息名的调用点是可以共享一个共同的 PIC 从而减少空间固有开销。在这个设想下,PICs 可以充当快速的特定消息查找缓存。一个多态发送的平均开销很可能高于特定调用点 PICs 因为每个 PIC 的类型数量会增加,这个是由于局部性丢失导致的(一个共享 PIC 将会包含特定消息名的所有接收者类型,调用相关的 PIC 只包含实际出现在调用点的类型)。
3.6 实现和结果
我们为 SELF 系统设计和实现了多态内联缓存并且测量它们的效果。这节所有的测量都是在一个有 48 MB内存的轻量加载的 Sun-4/260 上进行的;用于比较的基础系统是1990 年 9 月的 SELF 系统。这个基础系统使用内联缓存;一个直到特定方法的代码的发送需要 8 条指令(9 个周期)。一个内联缓存失败花费 15 毫秒或者 250 周期。失败时间可以通过一些优化和用汇编重编码关键部分来降低。我们估计这些优化可以降低失败的固有开销两倍左右。因此,我们的测量可能会夸大 PICs 的直接性能优势到两倍左右。另一方面,商业的 Smalltalk-80 实现(ParcPlace Smalltalk-80 系统,2.4版本)的测量表明它花费 15 毫秒处理失败,所以我们当前的实现并不是看上去的那样无理由的慢。
我们实验的系统的单态发送使用了和基础系统相同的内联缓存形式。对于多态发送,一个桩被构造来测试接收者类型和跳转到对应的方法。这个桩有个固定的 8 周期开销(加载接收者类型和跳到目标方法),每个类型测试花费 4 周期。PICs 就像 3.5 节描述的那样实现的。前面章节提到的变化部分基本没有实现,除了调用点可能会被当做巨态当它超过十个接收者类型(但是这种调用没有出现在我们的 benchmarks)。
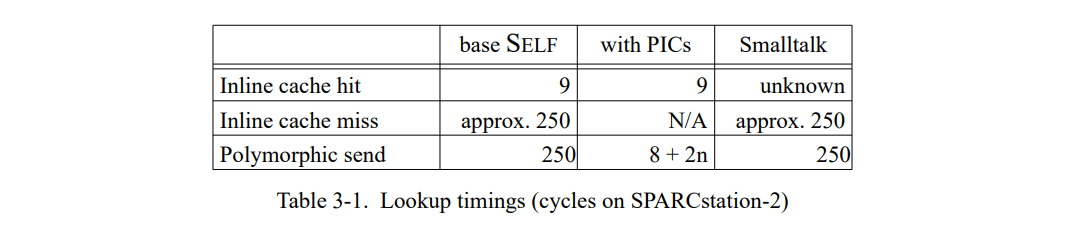
表 3-1 总结了查找时间。基础系统里的多态发送开销依赖于多态调用点的内联缓存失败率。例如,如果发送执行每三次更改一次接收者类型,花费将会接近于 250/3 = 83 周期。对于有 PICs 的系统,平均多态查找开销是用例数量的函数;如果所有的 n 个用例都是完全相似的,平均分发将会涉及 n / 2 类型测试所以花费 8 + (n / 2)* 4 = 8 + 2n 周期。
为了评估多态内联缓存的效果,我们测量了一套 SELF 程序。这个程序(有 PolyTest 的异常)可以被认为是相当典型的面向对象的程序能覆盖各种编程风格。更多的 benchmarks 数据在 [70] 中给出。
Parser。一个递归向下的解析器为早期 SELF 语法版本开发的(550行)。
PrimitiveMaker。根据原语描述生成 C++ 和 SELF 桩例程的程序(850行)。
UI。SELF 用户接口原型(3000行)运行一个小的交互界面。因为用于我们的测试的 Sun-4 没有特殊的图形硬件,运行中占主导地位的是图形原语(如多边形填充和全屏位图拷贝)。对于我们的测试,有三个非常昂贵的图形原语被转为无操作;保留的原语仍然占据全部运行时间的 30%。
PathCache。SELF 系统的一部分,用于计算所有全局对象的名字然后存储为压缩格式(150行)。大部分时间花在一个循环上其迭代处理一个包含 8 个不同种类对象的集合。
Richards。一个操作系统模拟 benchmark (400行)。这个 benchmark 调度执行四个不同的任务。它包含了一个经常执行的多态发送(调度器发送 RunTask 消息到下一个任务)。
PolyTest。一个人造的 benchmark(20行)为了显示 PICs 所能达到的最高加速而设计的。PolyTest 由一个 5 度多态发送的循环组成;发送被执行一百万次。正常的内联缓存在这个 benchmark 会有 100% 的失败率(不存在两个递归发送有相同的接收者类型)。因为 PolyTest 是比较小的,人造的 benchmark,所以计算整个 benchmark 集的平均值的时候不会包含它。
3.6.1 执行时间
为了获得更准确的测量,所有的 benchmark 连续运行 10 次然后计算平均的 CPU 时间。这个程序重复10次,选择最小的平均值(假设比较长的时间是因为其它的 UNIX 程序导致的)。一次垃圾回收被执行在每次测量前为了减少不准确性。图 3-6 显示系统使用 PICs 节省的执行时间(详见附录A中的表 A-2 )。
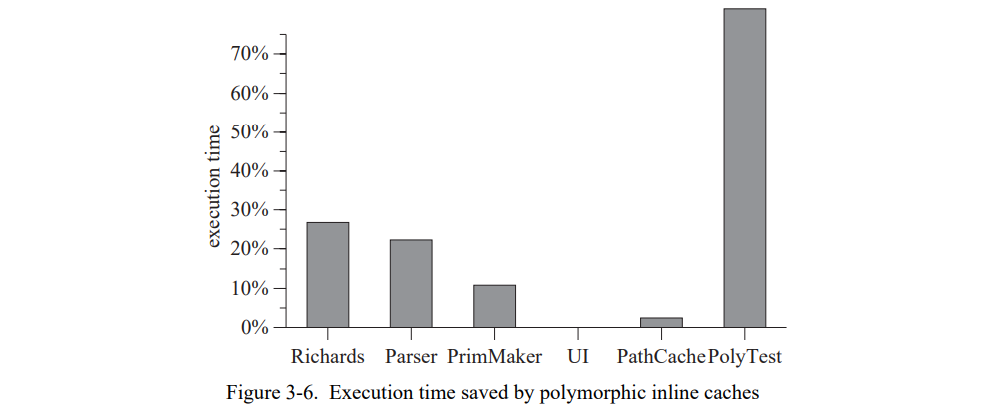
节省的时间从无(UI)到重大的(Richards,Parser)再到壮观的(PolyTest);benchmark 节省的时间的中位数是 11% (去掉 PolyTest)。从单个 benchmarks 观察到的加速与基础系统中处理内联缓存失败的时间紧密相关。例如,在基础系统的 PolyTest 花费了超过 80% 的执行时间在失败处理上,然后超过 80% 的执行时间由 PICs 消除。这种密切的相关性表明 PICs 几乎消除了内联缓村失败的所有固有开销。
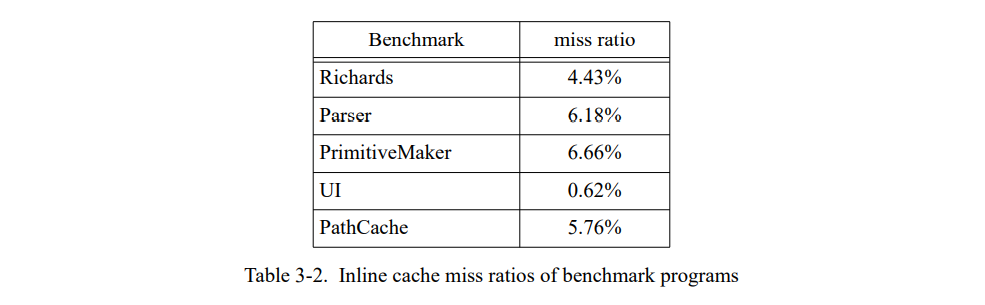
表 3-2 显示了我们的 benchmarks 在基础系统的失败率。虽然 SELF 的实现有自己的优化编译器与 Smalltalk 系统完全不同,但与之前那些 Smalltalk 系统的研究观察到的失败的概率相同的,其观察到的失败概率大约是 5% [44,130,132]。当引入 PICs 时失败率不与加速直接相关因为 benchmark 有完全不同的调用频率(相差五倍以上)。
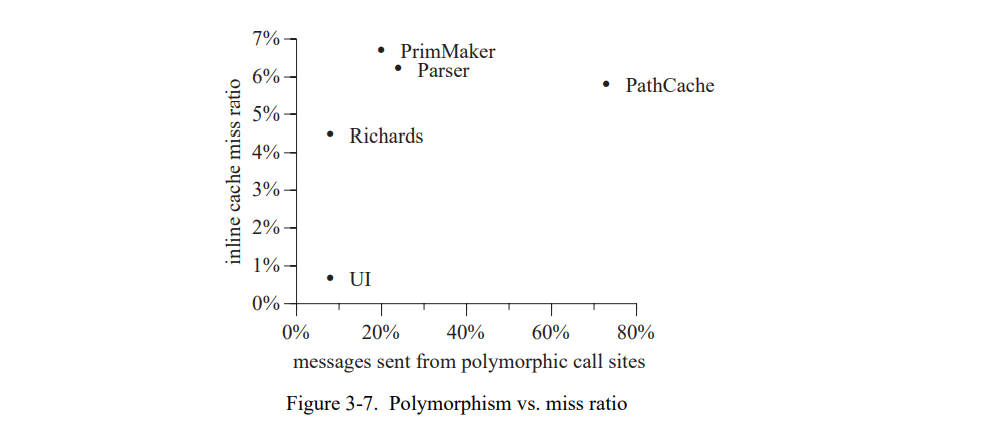
一个可能的期望是内联缓存失败率相关于程序中存在的多态机制的度,通过多态调用点的消息发送的分数来衡量(如,来自内联缓存即遇到了至少两个不同的接收者类型)。例如,一个假设是一个程序发送的80%的消息来自多态调用点有更高的内联缓存失败率比起一个程序只发送 20% 来自多态调用点的消息。有趣的是,我们的 benchmark 程序中没有这样的场景(图 3-7)。例如,PathCache 有超过 73% 的消息发送来自多态调用点而 Parser 有 24%,但是 PathCache 的内联缓存失败率(5.8%)稍低于 Parser 的失败率(6.2%)。PathCache 中只有一个接收者类型在大部分多态调用点中占主导地位(所以接收者类型基本不改变),而 Parser 的内联缓存的接收者类型频繁地改变。因此,按发送频率对 PICs 类型测试进行排序(如 3.2 节的建议)对于像 PathCache 的程序可能是个胜利。
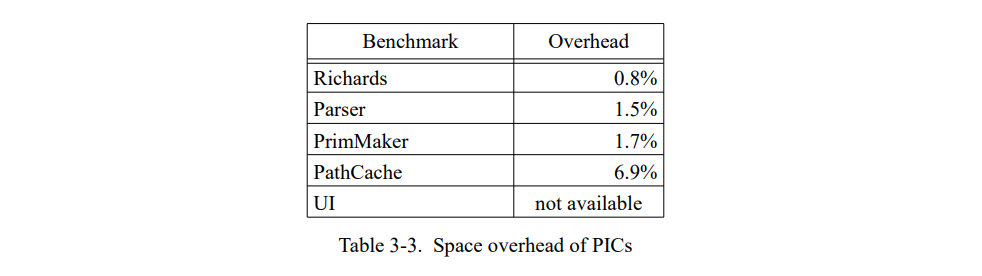
3.6.2 空间固有开销
PICs 的空间固有开销是比较低的,通常小于编译代码的 2%(见 表 3-3)。低固有开销的主要原因是大部分调用点不需要 PIC 因为它们是单态的。因此,即使一个 2 个元素的 PIC 桩占据超过了 100 字节,整体空间开销仍非常适中。
3.7 总结
传统的内联缓存对于大部分的发送都工作良好。 但是,真的多态调用点(例如,调用点的接收者类型改变的比较频繁)会导致显著的内联缓存开销,我们测量下来要消费 25% 的程序总执行时间。
我们用多态内联缓存(PICs)扩展传统的内联缓存从而可以缓存多个查找目标。PICs 非常有效地移除了内联缓存的固有开销,加速了我们的 benchmark的执行达到 25%,中位数是 11%。
虽然我们已经讨论了 PICs 作为加速消息发送的一种方法,但它在SELF系统中的主要目的是为了优化编译器提供类型信息。通过这种类型信息获得的性能提升远远超过本章中观察到的加速。我们将会在第五章详细讨论 PICs 的这方面内容。
4. 非内联编译器
前代 SELF 编译器造成的长时间的编译暂停非常分散用户的注意力,威胁要向提升程序员生产力的目标妥协。例如,开始原型用户接口花费了 60 秒,其中 50 秒是编译时间。虽然 SELF 编译器和标准 C 编译器一样快,但仍然很慢。
4.1 简单代码生成
为了提高系统的响应能力,我们决定实现一个非内联的编译器(“NIC”)。它的任务是尽可能快的编译方法,不尝试任何的优化。最后,它的代码生成策略是非常简单的。编译器直接翻译源方法的字节码到机器码中间没有构造中间表达式。
字节码按如下方式转换:
- 源码字字串(如,‘foo’)被加载到寄存器。如果字串是一个块,块克隆原语会第一个被调用来创建块(除了原语失败块,其会被特殊处理,见下面说明)。
- 原语发送(如,_IntAdd:)被转换为一个 C 或者汇编原语相应的调用。
- 发送被转换为动态分发的调用通过生成一个内联的缓存,除了发送访问一个方法的局部变量,此时相关的栈位置被访问。
寄存器分配相当的简单:表达式栈条目(如,表达式已经被评估但还没有被一个发送消费因为其它表达式需要先评估)被分配到一个寄存器中,一个位掩码追踪活跃的寄存器。局部是栈分配的因为它们可能会被内嵌块向上访问;所有的入参(通过寄存器传送)会被压入栈因为相同的原因。这是需要一些代码分析的地方之一(例如,分析一个方法是否包含任何的块)可以加速代码生成。非内联的编译器包含 2600 行 C++。
编译器只执行两个优化,两个都非常的简单易于实现且有已知的显著收益。首先,原语失败块会别延迟创建直到它们需要的时候。例如,整数加法原语 IntAdd:用一个失败块作为参数。当原语失败时块被调用,例如,因为一个溢出。但是原语调用通常时成功的,因此失败块通常不需要。因此,编译器延迟了失败块的创建直到原语实际失败的时候(如,直到它返回一个特殊的错误值)。这个优化加速了程序大概 10-20% 因为它极大地降低了程序的分配率。
第二个优化是访问接收者中的槽被内联,替代一个有加载语句的发送。虽然加速的结果非常的一般(通常只有非常小的百分比),这个优化降低了已编译代码的大小将近 15% 因为它用一个字的加载语句替换了十个字的内联缓存。
此外,NIC 也使用了客制化,虽然没有从中受益太多(接收者实例变量访问的内联是使用客制化的唯一优化)。客制化被使用因为一个假设即所有的代码都是渗透到SELF系统许多部分的客制化(特别是查找系统),所以 NIC 更容易以这种方式被整合进系统。从 NIC 移除客制化可能会有利因为它会减少代码重复。
NIC 不执行一些其它语言的相似编译器通常会执行的优化。尤其,它不以任何方式优化整数计算,没有特例且不内联任何的控制结构(如,ifTrue:)。这些决策的性能影响会在 4.3 节和 4.4 节测试。
4.2 编译速度
NIC 大致使用了 400 条指令来生成一条 SPARC 指令。这个明显慢于 Deutsch 和 Schiffman 描述的简单编译器其每一条生成指令只需要使用 50 条指令[45]。
这个不同有几个原因。首先,SELF 字节码比起 Smalltalk-80 虚拟机的字节码更高级别。例如,SELF 为通常的发送使用相同 Send 字节码,访问实例变量,访问局部变量,和原语调用因为所有这些在 SELF 上是语义完备的。相比之下,Smalltalk-80 有更面向机器字节码格式;事实上,在早期 Smalltalk 实现上字节码直接由微码解释[43]。例如,Smalltalk 有特殊字节码来实例变量访问(特殊槽号码),局部访问,和最常见的原语(算术和控制转换)。因此,Smalltalk-80 字节码编译器(等同于 SELF 解析器)已经执行了一些编译任务如替换简单的控制结构为跳转字节码和替换算术操作为特定的字节码。作为结果,Deutsch-Schiffman 编译器不得不执行少量的转换 Smalltalk-80 字节码到机器码的工作。相比之下,这些信息没有显式的存在于 SELF 字节码中因为它不是为解释或者头脑中的快速编译设计的。
图 4-3 显示一个 NIC 编译后的粗糙的采样数据通过 gprof 采样工具采样大约 8,000 的编译任务获得。有趣地是,实际的编译任务的时间只是编译方法的分配长两倍。不出意外地是,处理消息发送占用实际编译的很大一部分(编译时间的33%,或者总共的 23% )。但是 Smalltalk 系统中编译器也花费了 17% 的时间(总共的 12%)在解析器的处理任务上,就像槽的搜索,决定一个发送是否是本地槽的访问,和计算哪个字节是语句边界。

另一个开销来源是编译器大量地使用抽象数据结构以简化实现。例如,它使用一个代码生成器对象来从前端抽象代码生成细节,所有移植编译器变得简单。类似地,代码生成器使用汇编器对象以生成指令而不是自己操纵指令字。虽然这样汇编器是相当高效的(编译器调用诸如 load(base_reg, offset, destination) 而不是传递一个字符串“load base, offset, dest”),但是这种组织方式阻碍了一些优化如对一些特定常见的指令或指令序列使用预计算模式。另一方面,它简化了系统因为所有的编译器共享相同的汇编器。
另一种描述编译时间的方式是测量每个字节码的编译时间,如每个源码单元。

图 4-2 显示了编译时间是相当线性于源方法长度的,虽然相同大小的方法的编译时间会有变化有些时候是因为不同的字节码会花费不同的编译时间。例如,加载一个常量 1 比起编一个发送快了许多:前者直接生成一个机器指令,同时后者生成多达十几条指令首先要检查发送是访问一个局部变量还是接收者中的一个实例变量。平均而言,编译器中每个字节码使用 0.2ms 而一个启动开销是 2 ms;这个线性回归相关性系数是 0.78。大部分编译过程是短的,平均是 3 ms(图 4-3)。
4.3 执行时间
未优化的代码是相当慢的;表 4-1 显示它的性能与优化过的 SELF 程序的关系。在大型程序上,未优化的代码运行起来 9 倍慢于优化 SELF 编译器产生的代码,但是更小的程序如有个小循环可能会更慢。一个极端的例子,BubbleSort 慢了两个数量级。

未优化的程序的编译时间都花费在哪了?本节会分析这个问题通过使用 CecilInt (一个巨大的,面向对象的程序)和 Richards (一个较小的,更少多态的程序)为例子来讨论四个主要的原因:寄存器窗口,查找,指令缓存失败,和原语调用 / 垃圾回收。
4.3.1 概述
表 4-2 显示一个简单的 benchmarks 执行时间概况。实际的编译代码约占总执行时间的一半。大约 20-30% 的时间是花费在处理内联缓村失败上的(见 4.3.2 节),另外 20-30% 花费在原语(如整型加法或块分配)和垃圾回收。
表 4-3 显示两个相同程序面向硬件的视图;它包含整个程序执行的数据(即,不仅仅是编译 SELF 代码)。寄存器窗口和指令缓存失败导致了程序的低性能。4.3.4 节和 4.3.5节讨论了两个因素。

4.3.2 查找缓存失败
在不优化的代码中,大部分的调用点是巨型的,即,它们的接收类型在非常大量的接收者类型中变化非常频繁。例如,ifTrue:true 对象的方法发送值到它的第一个参数:
ifTrue:aBlock = { aBlock value }
ifTrue:发送自许多地方,所有传递不同参数的块。因此,值发送是巨态的因为每个 ifTrue 的使用有不同的接收者类型:在程序中。在当前系统中 PICs 缓存只支持多达 10 个不同的接收者类型。,发送总是在 PICs 中命中失败,造成昂贵的查找失败处理异常。同时,所有的这些失败占据了 Richard 执行时间的三分之一以及 Cecil 的 18%。在优化代码中,ifTrue:会被内联,也允许编译器去内联值发送(因为参数总是一个块字面量)。因此,在优化代码值发送不会导致开销。
4.3.3 块,原语调用,和垃圾回收
NIC 创建更多的块(闭包)超过优化 SELF 代码创建的因为它不优化控制结构涉及块的东西(或者其它的,就此而言)。例如,几个块被创建来给一个循环的每个迭代。同时,块创建占据了两个 benchms 大约 5% 的时间。因为如此多的块对象被创建,所以扫描器(局部垃圾回收)是必须的。幸运地是,这些扫描器非常的快因为大部分对象(基本都是块)是不存活的,所以对于两个程序 GC 开销小于 3% 。不优化的代码调用许多原语,即使是简单的操作像整型算术和比较。同时,所有的原语(包括块分配和 GC)使用大约 20-30% 的总执行时间。
4.3.4 寄存器窗口
SPARC 架构[ 118] 定义了一组重叠的寄存器窗口允许一个进程保存调用者的状态通过切换到一组新的寄存器。只要调用深度不超出可用寄存器组的数量,这样的一个保存可以在一个周期里完成不需要任何的内存访问。如果在一个保存指令执行时没有可用的空余寄存器组,一个“寄存器窗口溢出”陷入会发生然后陷入处理透明地释放一组寄存器通过将它的内容保存到内存中。相似地,一个“窗口下溢”陷入被用于重加载即如果需要再一次的话从内存中刷数据到寄存器组中。不幸地是,未优化的 SELF 代码同时有高的调用密度和高的调用深度;例如,一个 for 循环(通过消息和块实现)调用深度为 13。因此,未优化的代码非常频繁的发生窗口溢出陷入和下溢陷入花费大量的时间处理这些陷入。8.2 节会详细地分析这个开销;当前,可以说在当前的 SPARC 实现上未优化代码的寄存器窗口开销达到了总执行时间的 40%。
4.3.5 指令缓存失败
NIC 的代码生成也会消费许多的空间:每个发送花费 15 个 32 位字在加载参数寄存器指令、调用指令、和内联缓存指令上。此外,每个方法导语大约 15 字(导语会测试接收者映射,增量和未重编译测试调用统计数)。因此,未优化的代码有相当高的指令缓存失败的固有开销;Richards 花费了10% 的时间在等待从内存中加载指令,CecilInt 花费了 27% 的时间在指令缓存失效上。
4.4 NIC 对比 Deutsch-Schiffman Smalltalk
NIC 在很多方面与 Deutsch-Schiffman 编译器比较相似。但是 ParcPlace Smalltalk-80(4.0版本)运行 Richards benchmark 在 3.2 秒,比未优化的 SELF 版本快十倍。为社么 Smalltalk 系统如此的快?有多少的性能差距是语言上的不同导致的,有多少的不同是实现上导致的?
几个不同点可以解释性能差异;通常会想到三个原因,两个是语言不同还有一个是实现不同:
- 硬编码了一组性能关键的方法。就是说,某些消息的含义是固定的所以这些消息的源方法被忽略掉了。通常,Smalltalk硬编码方法实现了 if 和 while 两个控制结构(加上少量的其它循环结构),它也硬编码了整型计算。通过这样做,系统可以定制化(也极大地加速)这些常用的操作而不用实现通用的内联优化。与此相反的,NIC 不定制化任何的操作而总是执行这些消息的发送操作。
- SELF 程序执行更多的消息发送因为访问实例变量总是通过消息执行,然而 Smalltalk 的方法可以直接访问在接收者中的实例变量而不需要通过发送消息。但是,因为 NIC 内联访问接收者中的实例变量,不应该有许多额外的发送,肯定不足以说明一个数量级的性能差异。
- NIC 生成的代码可能比 ParcPlace Smalltalk 编译器生成的代码更低效。例如,Smalltalk 编译器在算术消息中使用类型预测然后为整型场景生成内联缓存,然而,NIC 没有类型预测也从不内联原语。此外,NIC 使用 SPARC 的寄存器窗口而 ParcPlace Smalltalk 不使用。但是,定制化整型计算和局部代码的质量不太可能导致将近十倍的性能差异。
4.4.1 不带硬编码控制结构的 Smalltalk
从这个语言和实现不同的大致测试来说,似乎是第一个–Smalltalk的硬编码控制结构–会对性能产生巨大的影响。为了验证我们的怀疑即 if 和 while 的硬编码是导致性能不同的绝大部分原因,我们禁用了 ParcPlace Smalltalk 系统(4.0版本)中的这些优化,因此所有的控制结构都会生成真实的消息发送。 此外,我们改变了 whileTrue 等的定义类似于它们在SELF 中的等价表示。最后一步是必须的因为这些方法在标准的 Smalltalk 系统中是递归的,所以它们的执行会成为不必要地低效。相反的,它们通过使用新的 primitiveLoop 控制结构来实现即由修改过的编译器来重新组织和开放代码。例如,whileTrue: 的实现如下:
1 | whileTrue: aBlock |
这个改变了的 Smalltalk 编译器转换 primitiveLoop 消息为一个简单的向后跳转到方法的开始,就像 _Restart 原语 SELF 用于实现迭代。 在这些改变之后,所有重要的 Smalltalk 控制结构的实现就与它们在 SELF 相同的功能类似,但后者依旧只有少量的优化。例如,whileFalse: 在 SELF 中是通过 whileTrue: 实现的但在 Smalltalk 中是直接通过 primitiveLoop 实现的。因为我们只是要粗略地评估非内联控制结构的性能影响,所以不会不计成本地实现全部的 Smalltalk 控制结构为 SELF 中完全等价的结构。
这些改变对 Smalltalk 的性能产生深远的影响:原始的系统执行 Richards 要 3.2 秒,而改变后的系统需要 33.1 秒。其它的程序也有类似的减慢(Table 4-4)。因此,它表明少量的控制结构的硬链接加速了 Smalltalk 大约 5 到 10 倍!有点意外的是,这个单一的改变缩短了未优化 SELF 代码和 Smalltalk 的大部分性能差距。
4.4.2 一个内联控制结构的 NIC
上述实验出人意料的结果表明 NIC 中相似的优化可以显著地加速它的代码。为了验证这个假设,我们配置优化的 SELF 编译器来生成代码类似于一个假想的 NIC 会内联 if 和 while 控制结构。这个的意图是为了内联 if 和 while 如此控制结构本身就不会涉及任何的块创建或者发送了。例如,表达式
1 | x < 0 ifTrue: [ doSomething ] |
被翻译为机器码反汇编为如下序列:
1 | <send “x”> |
对于这个实验,优化编译器的各个部分都被关掉所以生成代码的质量和NIC的代码非常的相似。例如,局部变量没有寄存器分配,没有执行后端代码优化。表 4-5 为 Richards benchmark 比较了标准 NIC 的执行时间和当前的编译器(“NIC+”);两个版本的 Smalltalk 系统的执行时间都被进行比较了。清楚地看到,内联两个控制结构极大地提高了已编译 SELF 代码的性能,不但因为已编译代码变得更高效(更少的固有开销和块创建)而且因为所有的非内联控制结构造成的查找失败都被消除了。
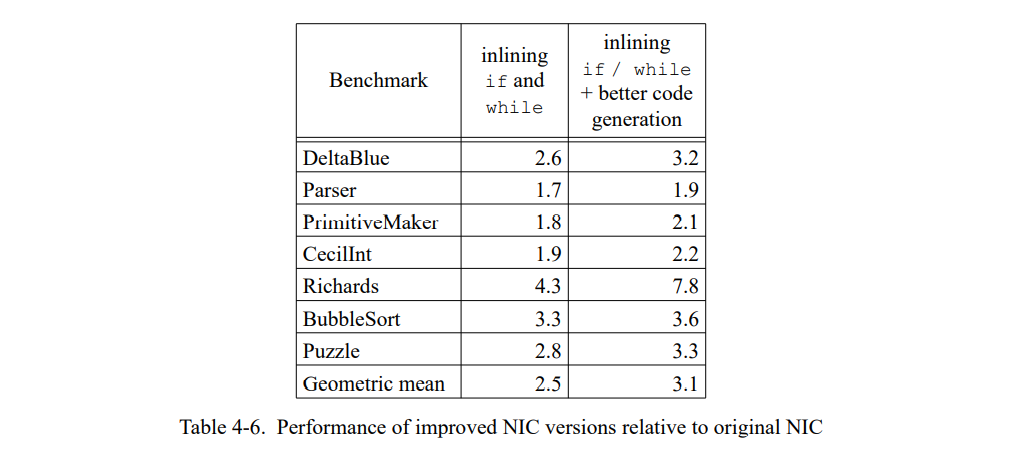
表 4-6 显示内联 if 和 while 可以平均加速程序到 2.5 倍。一个更好的编译器额外执行优化如寄存器分配和拷贝传播达到 3.1 倍。(我们模拟这个编译器通过使能优化 SELF 编译器中的所有的后端优化同时保留其它的限制。)通过更好的代码质量获得额外的加速是有限的(特别是 Richards),因此一个编译器的真实实现即内联了如 if 和 while 的性能应该和上面的数值比较相似,即使代码质量与我们实验设置的有些不同。
为何 ParcPlace Smalltalk 比起 SELF(Table 4-6) 从内联控制结构(5-10倍,见表 4-4)获得更多收益?有许多的不同导致了这个差异。例如,两组 benchmark 是不同的;同时,基础的 Smalltalk 系统优化了更多的控制结构而不只是 if 和 while。此外,两个系统在许多实现细节上是不同的;例如,NIC 使用客制化而 Smalltalk 不使用。最后,因为 Smalltalk 系统绝不会在没有内联重要控制结构的情况下运行,它可能没有对非内联的场景调整过。因为 Smalltalk 的实现细节不是有效的,我们无法确定确切地差异来源,因此无法得知要多么靠近一个非优化 SELF编译器才可以与非优化的 Smalltalk 编译器。
4.5 一个 SELF 解释器的性能预测
鉴于相对慢速的未优化代码和需要相对大空间开销来存储已编译代码,一个解释器是否可以提供相似的性能而几乎没有空间开销呢?
一个 SELF 解释器面对一个大的挑战:它必须高效地解释消息发送,因为 SELF 中几乎所有的事情都与消息发送相关。两个问题让它变得很难:
- 没有内联缓存,发送是昂贵的。一个直接的解释器不使用内联缓存就不得不使用查找缓存替代。不幸地是,查找极端的频繁:例如,Richards 发送大约 8.5 百万消息(不计算局部变量的访问)。如果我们想要解释器以 NIC 的速度运行允许它 50% 的时间用于查找,一个查找必须花费少于 42*0.5/8,500,000s = 2.5us或者大约 55 条指令(假设 SPARCStation-2 的 CPI 为 1.8,见章节 8)。这已经足够一个查找缓存的探测了,但不清楚是否足够覆盖失败开销。当前系统一个真实消息查找的花费是相当高的,大概在 100 到 1000 us。因此,即使是 1% 的相对较小的未命中率都会导致每个发送分摊 1-10us 的失败开销。
- 字节码编码是非常抽象的。如同上面的讨论,这里只有一个发送字节码,即使是一个局部变量的访问都会被表达为这个字节码。为了高效地解释,它可能需要重新设计字节码格式从“real” 消息发送分离出”trivial”消息发送,或者缓存下面讨论的中间表示。
使用一个重新设计的字节码格式,小心优化的查找缓存,和一个巨大的查找缓存,它大搞可能用解释器达到(虽然不容易)NIC 的速度。通过硬编码少数重要的控制结构,一个解释器可能会超过当前的 NIC。不清楚将会节省多大的空间因为重构方法表示可能会使用更多的空间,且查找缓存将会相当的大因为失败开销非常的昂贵。但是,最有可能的是解释器使用的空间会显著地少于已编译代码。
另一种解释器实现方式承诺以使用更多的空间为代价换取更好的性能。解释器可以动态地翻译源方法到已解释的方法(imethods)然后解释这个 imethods。这种方式的主要优势是 imethod 的格式已经转变为高效的解释形式。
例如,它有内联缓存,会显著地加速发送。同时,空间固有开销会保持得比较低因为只有已经缓存的 imethods 使用了扩展的表示而源方法可以继续的使用更抽象和节省空间的表达。
这种方法的缺点是引入了缓存代码的所有问题和固有开销:从源方法到 imethod 的翻译开销,保持 imethod 代码的开销(分配和取消分配,压缩等),以及持续追踪源改变的开销(当源方法改变,imethod 必须刷新)。根据简单解释器的加速,额外的复杂性和空间开销可能是不合理的。
此外,解释器可以只添加内联缓存到直接解释器通过每个发送字节码添加一个指针来缓存每个发送最后调用的方法;每个方法会缓存最后的接收者类型。Smalltalk 解释器已经使用了相似的组织方式[44]。由于大部分字节码都是发送,这种方式下每个字节码大约需要一个字来缓存。
4.6 NIC 和交互性能
添加一个非优化的编译器到 SELF 系统中的一个目标是降低编译暂停,即提高系统的响应能力。当前的 NIC 在多大程度上实现了这个目标呢?如前一节的讨论,这里有许多编译时间(和简化)和执行时间上的权衡。编译速度加倍好还是执行速度加倍好?
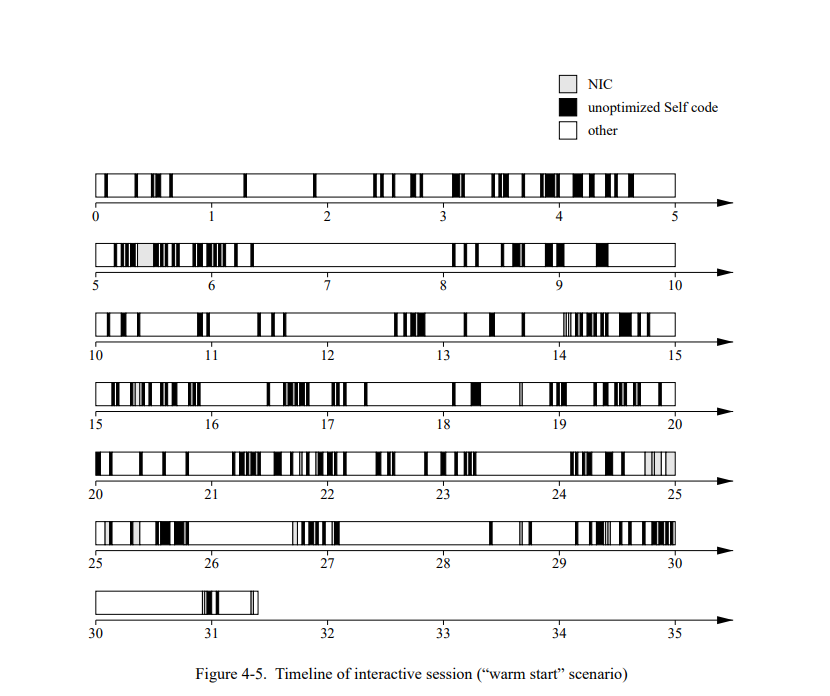
图 4-4 显示了使用 SELF 用户接口进行的一分钟交互的时间线。交互序列被设计来突出初始响应能力:大部分的交互都是第一次执行只有一个“冷”代码缓存,因此必须相当频繁地生成新代码。图 4-5 显示一个大部分代码已经被编译的系统的相似的交互序列。我们通过每秒50次的采样当前系统的活动获得时间线(即,无论是编译还是运行 SELF 代码)然后将结果添加到一个文件中。
基于时间线,我们可以做两个观察:
- 在”冷启动“的时间线中,编译时间超过了 NIC 的执行时间。例如,图 4-4 的前三秒系统花费了相当多的时间在 NIC 中,用来生成上百个新的已编译方法。
- 在两份时间线中,未优化的 SELF 代码只占总执行时间的一小部分且从没有长周期的运行时间。鉴于 NIC 生成的代码非常的不好,所以代码质量对于整体的影响非常的小,让人很意外。
从两份观察可以得到一个更快的编译器或者解释器可以提高系统的响应能力即使它们降低了执行时间。例如,即使两倍慢的速度运行程序解释器也会受益。

4.7 总结
一个非内联的编译器(NIC)是编译过程的第一阶段。它快速地编译代码(通常每个编译少于 3 ms)但是生成的相当较慢的代码,显著地慢于非优化 ParcPlace Smalltalk 编译器生成的代码。一个使用 ParcPlace Smalltalk 编译器的实验显示在没有硬编码通用的控制结构的情况下,Smalltalk 执行慢了一个数量级。另一个实验显示在 SELF 中一个更复杂的编译器其内联(或硬编码)了 if 和 while 控制结构会有显著地加速(大约2.5倍),代价是加法的实现复杂或者丢失了语言的简单性(如果控制结构被硬编码)。或者,一个 SELF 解释器可能会达到当前 NIC 的速度同时降低内存的使用。
与已知不同的是,未优化的 SELF 代码相对的慢速在实现中并不是问题因为系统不会花费太多的时间在执行未优化代码上。交互的SELF会话的时间线显示比起提高已编译代码的速度,编译时间的提高更有利于系统的响应能力,特别是在“冷启动”场景这里有上百个方法必须被快速编译。
5. 类型反馈和自适应重编译
面向对象的程序比起像 C 或者 Fortran 语言写的程序更难以优化。面向对象的编程风格鼓励代码分解和微分编程。因此,程序更小且过程调用更频繁。此外,难以优化这些进程调用因为他们使用动态分发:被调用的过程具体是哪个函数在运行前是未知的因为它取决于接收者的动态类型。因此,一个编译器通常无法在这些调用上应用标准的优化如内联替代或者进程间分析。思考下面的例子(用 pidgin C++ 写的):
1 | class Point { |
当编译器遇到表达式 p->get_x(),此时 p 的声明类型是 Point,它不能优化这个调用因为它不知道 p 的确切地运行时类型。例如,Point 有两个子类型,一个是笛卡尔点,另一个是极坐标点:
1 | class CartesianPoint : Point { |
因为 p 在运行时可以是 CartesianPoint 或者是 PolarPoint 对象,编译器的类型信息不够精确不足以优化这个调用:编译器知道 p 的抽象类型(即,即一组可以调用的操作,和他们的签名)但不是确定的类型(即,对象的大小,格式,和操作的实现)。
重要的是要意识到不是动态类型导致的动态分发调用的问题:如我们上面看到的例子,它也会发生在静态类型的语言上。而是,封装和多态导致的问题,即隐藏了来自对象客户端的对象实现细节和提供了相同抽象类型的多种实现。如果只能访问到程序的源码,静态语言的编译器除了为通用场景的消息发送生成一个动态分发的调用没有更好的方案了。静态类型使得编译器可以检查 get_x() 的消息是合法的(即,对接收者 p 保证有一些实现一定存在),但不能识别哪个实现会被调用。因此,对于消除动态分发调用的问题,我们研究一个动态语言如 SELF 或者研究一个静态类型的语言如 C++ 都是相差不大的。
纯的面向对象的语言加剧了这个问题因为每个操作都调用一个动态分发的消息发送。例如,即使是非常简单的操作如对象变量访问,整型加法,或者数组访问理论上在 SELF 中都调用消息发送。因此,一个纯的面向对象的语言如 SELF 为处理频繁动态分发调用问题的优化技术提供了一个理想的测试集。
我们已经开发了一个简单的优化技术,类型反馈,从运行时系统反馈类型信息到编译器。有了反馈,编译器可以内联任意的动态分发的调用。我们已经为 SELF 系统实现了类型反馈且与自适应重编译结合在一起:已编译代码最初以未优化的形式创建来节省编译时间,时间敏感的代码在后面被重新编译和优化通过使用类型反馈和其它优化技术。虽然我们只为 SELF 实现类型反馈,但这个技术是语言独立的可以应用于静态类型,非纯语言等上面。本章的剩余部分会描述当前工作的基本思想不会涉及到太多的 SELF 相关的细节。下一章会讨论基于此处描述的原理实现的新 SELF 系统的细节。
5.1 类型反馈
面向对象语言(或者其它支持某些延迟绑定的语言,如 APL)主要的实现问题是编译时缺乏静态可用的信息导致的。这是因为,一些操作的确切含义无法静态地确定依赖于动态(即,运行时)信息。因此,只是基于程序文本,非常难以静态地优化这些延迟绑定的操作。
这边有两个方式来解决这个问题。第一个是,动态编译(也叫延迟编译),将编译放到运行时这时有额外的信息可以更好地优化延迟绑定操作。SELF 和之前其它的几个系统(如,van Dyke APL 编译器[51])采用这个方式。与这些系统比起来,SELF 多延迟了一步不尝试立即生成最好的代码(即,当编译代码是第一次需要)。而是,系统首先生成不优化的代码只有之后生成时在生成优化的,即在清楚代码经常使用之后。除了明显节省编译时间,这种方式生成的代码可能比 “eager” 系统生成的代码更好因为编译器有更多可用的信息。
如果不能(或不想)把编译放到运行时,可以使用第二种方式,更常规的方式即将额外的运行时信息放到编译器中。典型地,这些信息通过独立的运行收集然后写入文件,编译器被重新调用然后使用这些额外的信息生成最后的优化程序。
这些方式中都有类型反馈。现在,我们会集中于第一个方式因为它是 SELF 使用的;第二个方式会在5.6节中简单概述。
类型反馈的关键点是从运行时系统扩展类型信息然后反馈到编译器。具体地说,一个带有检测的程序版本记录程序的类型配置信息,即,程序中每个单一调用点的一系列接收者类型(还可能有它们出现的频率)。为了获得类型配置信息,标准的方法分发机制不得不用一些方式进行扩展来记录想要的信息,如,每个调用点保存一个接收者类型表。
当获得程序的类型配置信息,这些信息随即被反馈给编译器所以它可以优化动态分发调用(如果愿意)通过预测比较可能的接收者类型然后这些类型的调用。在我们的例子中,类型反馈信息会为 get_x() 调用预测为 CartesianPoint 和 PolarPoint 接收者,然后表达式 x = p->get_x() 可以被编译为:
1 | if (p->class == CartesianPoint) { |
对于 CartesianPoint 接收者, 上面的代码序列会执行的非常的块因为它去掉了原始的虚函数调用转变成了一个比较和一个简单的加载指令。
类型反馈实际上改变了我们对面向对象语言的优化问题的理解。在传统的视角中,实现级别的类型信息是稀缺的,因为程序短通常没有足够的信息来分辨 p 是 CartesianPoint 还是 PolarPoint。新的观点来自于意识到尽管最初可供编译器使用的实现类型信息确实很少,但却是因为在程序运行一段时间后运行时系统的信息被抛弃了。在 SELF 中,每个内联缓存或者 PIC 包含一个该发送所遇到的确定的接收者类型列表。换句话说,不需要额外的模块提供给类型反馈如果系统使用了多态内联缓存。因此,一个程序类型配置信息是一应俱全的:编译器只是需要去检查程序的内联缓存来知道一个调用点到目前为止哪些接收者类型已经被遇到了。在我们的例子中,对于 get_x 发送的内联缓存将会包含 Cartesian 和 PolarPoint 类型。如果编译器已经访问了这些类型信息,它可以内联任何发送因为所有的接收者是已知的。
使用类型反馈提供的类型信息会实际上简化编译。当缺少类型反馈,SELF-91 编译器执行大量的类型分析试图保留和传播稀缺的类型信息给编译器。使用类型反馈,主要的问题不在是怎样内联一个动态分发调用而是如何选择一个调用来内联。从执行类型分析的艰巨负担中释放出来,面向对象的语言的优化编译器应该是容易编写的不会牺牲代码质量。新的 SELF-93 编译器基于类型反馈只有之前编译器的一半大小,然而它可以内联更多调用,从而生成更快的代码。
5.2 自适应重编译
SELF 系统使用自适应重编译不只是为了利用类型反馈,也是为了界定应用的哪个部分应该被完全优化。下面的图片显示了 SELF-93 系统整个编译过程的概况:

当一个源方法第一次被调用,它被一个简单的,完全非优化的编译器(第四章)编译为了非常快速地生成代码。有一个非常快速的编译器来降低编译暂停对于一个使用动态编译的交互系统是必要的,正如我们将在第 9 章中看到的那样。如果这个方法经常被执行,会使用类型反馈对其进行重新编译和优化。有些时候,优化过的方法被重新编译为了使用额外的类型信息或者使其适应程序类型配置信息的变化。
SELF 系统必须在没有程序员干预的情况下发现重新编译的机会。通常,系统必须决定
- 什么时候重新编译(等待类型信息积累多长时间),
- 什么被重新编译(哪些编译后的代码最能从附加类型信息中受益),以及
- 哪个发送内联,哪个发送分离作为动态分发调用。
下面的章节会讨论这些问题。这里介绍的解决方案都采用了简单的启发式方法,但是尽管如此,我们稍后会看到效果很好。
5.3 什么时候重编译
SELF 系统使用计数器来识别重编译候选者。每个未优化方法有自己的计数器。在这种方法的导语部分,该方法递增计数器并将其与限制进行比较。如果计数器超过了限制,重编译系统被调用来决定哪个(或者全部)方法应该被重编译。如果方法的计数器溢出了但没有重新编译,计数器会被重置为 0。
如果什么都没做,每个方法可能最终都会到达调用极限然后将会被重新编译即使它的执行频率可能不会超过每秒几次,所以优化将难以带来任何益处。因此,调用计数器呈指数衰减。衰减率作为半衰期时间,即,计数器降低一半值的时间。衰减过程通过周期性地将计数器除以常数 p 来近似;例如,调整计数器的进程每4秒唤醒一次则半衰期就是15秒,常数因子是 $p = 1.2$ (因为 $1.2^15/14=2$)。衰减进程将来计数器从调用次数转为调用频率:给定调用极限 N 和衰减因数 P,一个方法在每个衰减周期里必须执行超过 $N*(1-1/p)$ 次才会被重新编译。
原始地,计数器总是预想的第一方式,被使用直到一个更好的解决方法被找到。在我们的实验过程中,我们发现触发机制(”when“)对于良好的重新编译结果而言,远不如选择机制重要(”what“)。因为简单的基于计数器的方法效果良好,我们没有在大量地考察其它机制。但是,有一些关于调用计数器衰减的有趣问题:
- 指数衰减是正确的模型吗?理想地,系统会重新编译那些优化开销远小于未来被调用累积的收益的方法。当然,系统不知道方法未来被执行的频次,但是基于频率的测量也忽略了过去:执行频率低于最低执行率的方法将永远不会被触发重编译,即使它被执行了无数次。
- 调用极限 N 不应该是个常数;而是应该取决于一个特定的方法。计数器真正想测量的是运行非优化代码浪费的时间。因此,一个会从优化中受益的方法应该计数的更快(或者有个更低的限制) 比起一个不会从优化中受益的方法。当然,可能很难估计优化对特定方法的性能影响。
- 当执行在一个更快速(或更慢)的机器上半衰期要怎么适配?假设原始的半衰期参数是 10 秒,但是系统运行在一个新的机器上有两倍的快。半衰期参数应该被改变吗,如果要,怎么变?一种观点是将更快的机器视为一个实时运行减半快的系统(因为每秒完成的操作是之前的两倍),因此降低半衰期为 5 秒。但是,人们也会质疑调用频率极限是绝对的;如果一个方法执行少于 n 次每秒,它不值得被优化。
- 相似地,应该用实时的,或是 CPU 时间,还是一些机器相关单元来计算半衰期时间(如,执行的指令数)。直观上,使用实时的似乎是错误的,因为使用者的思考暂停(或者咖啡暂停)也会影响重编译。使用 CPU 时间也有它的问题:例如,大部分时间被花费在虚拟机上(如,垃圾回收,编译,或者图形原语),半衰期被有效地缩短因为编译方法获得较少的时间来执行和增加它们的调用计数器。另一方面,这种效果可能是可取的:如果没有更多的时间被花费在已编译的SELF代码中,优化的代码不会增加太多的性能(当然有例外,如果优化降低了虚拟机的固有开销,如,通过降低块闭包的创建数量,然后降低分配开销和垃圾回收)。
虽然这些问题引发了许多有趣的讨论,此处不再赘述,大部分因为简单的方案就工作良好了还有就是时间的限制。但是,我们相信它们是未来研究的有趣方向,调查它们最终可能会有更好的重编译决定。
5.4 重编译什么
当一个计数器溢出,重编译系统被调用来决定哪个方法被重新编译(如果任意)。一个简单的策略是总重新编译那些计数器溢出的方法,因为它显然总是会被重新调用。但是,这个策略不总是有效的。例如,假设方法溢出它的计数器只是返回一个常量。优化这个方法将不会受益许多;但是这个方法应该被内联进它的调用者。因此,通常,为了找到一个好的重编译候选,我们需要遍历调用链然后检查触发重编译的方法的调用者。
5.4.1 重编译过程的概述
图 5-2 显示一个重编译过程的概况。从方法的计数器溢出开始,重编译系统向上走栈寻找一个”好“的重编译候选(下一节会解释”好”的含义)。当一个重编译被找到,编译器被调用来重编译方法,然后老的版本被忽略掉。(如果没有重编译者被找到,执行正常继续。)在优化编译过程中,编译器会标记重启点(即,执行会被唤醒的点)然后计算这个点所有活着的寄存器。如果这个编译成功的话,重新优化的方法会替换栈上相对应的未优化的方法,可能用单个优化的激活记录替换多个未优化的激活记录。然后,如果新的优化方法不在栈顶,重编译继续在新优化过的方法的被调用者上进行。在这个方式中,系统优化整个调用链从顶部重编译者到当前执行点。(通常,重编译调用链只是一个或者两个已编译方法深度。)
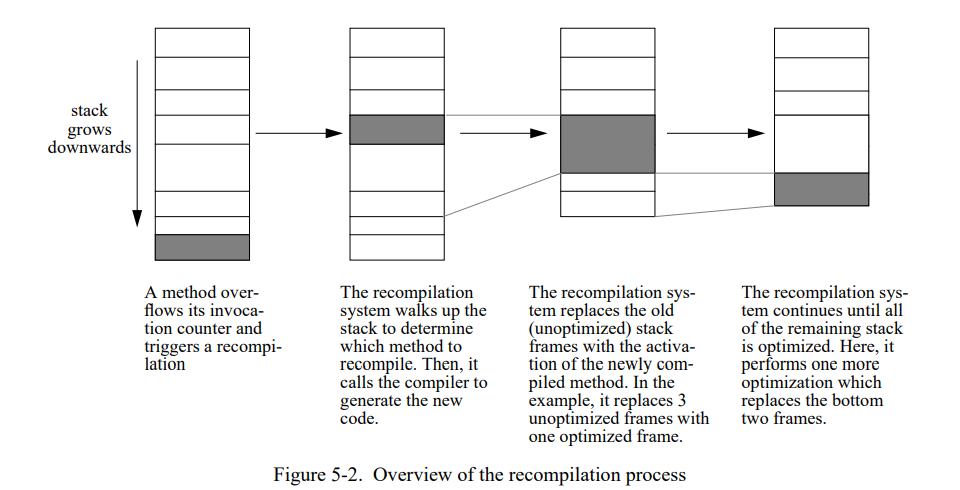
如果未优化的方法不能在栈上被替代,它们会被留下来完成它们当前的激活,但是随后的调用将会使用新的,优化过的方法。替换未优化方法失败的主要影响是会发生额外的重编译如果未优化的方法继续执行一段时间。例如,优化过的方法包含一个循环但无法在栈上被立即替换,重编译系统可能随后尝试只替换优化过的代码的循环体。
5.4.2 选择方法进行重编译
SELF-93 系统通过检测几个指标来选择重编译的方法。对于任何的重编译方法 m,下面的几个值被定义:
- m.size 是 m 的指令数量。
- m.count 是 m 被调用的次数。
- m.sends 是 m 直接产生的调用的数量。
- m.version 记录了 m 已经被重编译了多少次。
搜索一个重编译者可以概括为如下。让 trip 作为刚触发了计数器的方法,recompilee 作为当前的重编译候选。
- 以 recompilee = trip 作为开始。
- 如果 recompilee 有闭包参数,选择闭包的词法封闭方法如果它满足上面描述的条件。这个规则消除闭包通过内联闭包的使用到闭包里。如果内联成功,闭包通常可以完全优化掉。
- 否则,选择重编译者的调用者如果它满足下面的条件。这个规则会向上走栈直到遇到一个方法它或者太大了或者不会出现导致许多消息发送被执行。
- 重复步骤 2 和 3 直到 recompilee 不在改变。
无论何时重编译系统考虑一个新的编译者 m (在上面的 2 和 3 里),它将只会接收新的重编译者如果它遇到了下面的两个条件:
- m.count > MinInvocations 和 m.version < MaxVersion。第一个条款保证方法已经被执行足够多了次数可以考虑它的类型信息的代表。第二个条款防止无休止的重编译同一个方法。
- m.sends > MinSends 或者 m.size < TinySizeLimit 或者 m 未优化。第一个条款接受发送许多消息的方法,剩下的两个接受那种很可能已经通过内联与被调用者合并了的方法。
这些规则基于的假设是频繁执行的方法值得被优化,内联小的方法和消除闭包会导致更快地执行。虽然规则是简单的,但他们似乎可以很好地找到应用程序的“热点”,如第 7 章所示。(探索更准确的方式来评估潜在的保存和评估重编译的开销仍然是未来工作的一个有趣领域。当然,在系统的动态决策过程中(在运行时),做更多精确评估的额外开销也不得不考虑到。)
重编译系统用来找寻一个“好”重编译候选的规则在许多方面镜像了编译器用来选择“好”内联机会的规则。例如,跳过“微小”方法的规则在编译器中有个等价的规则可以使得“微小”方法被内联。理想地,重编译系统在每次决定向上走栈之前要咨询编译器来确保编译器会内联发送。但是,这样的系统是不切实际的:为了做出内联决定,编译器需要太多的上下文,诸如调用者和其它候选者结合时的全部大小(见 51页的 6.1.2 节)。因此,在这样的系统里重编译决议是昂贵的,故这种方式被拒绝了。但是重编译系统和编译器确实共享着 SELF-93 系统里的通用结构;本质上,重编译器走栈的标准是编译器内联标准的子集。
在重编译之后,系统也会检测重编译是否有效,即,它是否实际上提高了代码。如果先前的和新的已编译方法具有完全相同的非内联调用,重编译不会有真正的收益,因此新的方法被标记在将来的重编译不会被考虑了。
5.5 什么时候使用类型反馈信息
当编译一个特定的消息发送,定位一个相关的类型反馈信息是相对简单的。确定这些信息的可信程度非常困难因为一个方法的类型信息可能合并了几个调用者的类型。例如,一个调用者可能使用了一个有极坐标参数的方法 m 而另一个调用者使用了笛卡尔坐标点。在这个用例中,发送到该参数的类型反馈信息将包含两种类型。如果我们在内联 m 到第一个调用时用到这些信息,编译器会在 m 中专门为了这两种类型特定化一个发送即使只有极坐标点曾经发送过,且会浪费代码空间和编译时间。因此,如果一个已编译的方法有超过 N 个调用者,当内联缓存包含超过 M 个类型时(N, M > 0),类型信息会被我们的编译器忽略。伴随着一个巨大的 N 和 M,代码大小和编译时间会增加因为预测的接受者类型集变得很大;而 N 和 M 比较小时,类型反馈的效果下降了因为更多的接收者类型变成未知了由于类型反馈信息被认为是“被污染了”。我们的实现当前使用了 N = 3 且 M = 2 试图在极端中找到平衡。幸运地是,大部分内联缓存只包含一个类型(M= 1),所以它们的信息可以被信任而不用管调用者的数量。
当然,即使有这些预防措施,基于过去的接收者类型预测未来的接受者类型仅仅是一个比较有根据的猜测而已。优化编译器也会做相似的猜测取决于从前一次运行获得的执行画像[137]。但是似乎一个程序的类型画像比起时间画像更稳定[ 57]–通常,在运行时不会创建新的类型了。因此,当一个程序已经运行了一段时间,新的类型不太可能出现了,除非发生异常情况(例如,错误)或程序员更改应用程序。
5.6 添加类型反馈到一个传统的系统
类型反馈不需要SELF-93中使用的“特殊的”实现技术(如,动态编译或者自适应重编译)。如果有的话,这些技术让它更难以优化程序:在一个交互系统中使用动态编译对编译速度和空间效率有很高的要求。因为这些原因,SELF-93 的类型反馈实现不得不处理不完整的信息(即,部分类型画像和不精确的调用计数)以及要避免一些优化从而可以达到好的编译速度。
因此,我们相信类型反馈更容易添加到传统的批处理式的编译系统。在这样的系统里,优化将分三个阶段进行(图 5-3)。首先,执行过程被仪表化来记录接受者类型,例如使用了 grof-like profiler [59]。(标准的 grof profiler 几乎已经收集了类型反馈所需要的大部分信息,除了这些数据是调用者相关的而不是调用点相关的,即,它不会区分 foo 的两个调用如果两个都是来自相同函数的话。)然后,应用运行一个或者多个的测试输入,这些测试输入是产品使用过程中期望输入的代表。最后,已经收集的类型信息和画像信息被反馈到编译器用来生成最后的优化代码。
如上面提到的,静态编译有个优势即编译器有完整的信息(如,完整的调用图和类型画像)因为优化在一个完整的执行之后开始的。作为对比,一个动态编译系统必须基于不完整的信息来作决定。例如,它不能负担起维护一个完整的调用图, 而在第一次重编译时可能时必须的,此时程序仍然处于初始化的阶段时所以类型画像尚不具有代表性。在另一方面,一个动态重编译系统有个显著的优势即它可以动态的适配程序行为的变化。
5.7 其它语言适用性
显然地,类型反馈可以用于其它的面向对象的语言(如,Smalltalk 或者 C++),或者是带有通用操作符的语言其可以用类型反馈信息进行优化(如,APL 或 Lisp)。但它们的效果如何?我们无法给出一个确定的回答因为它可能需要一个实际实现的测量,这种不是有效的方式。因此,我们使用 Smalltalk 和 C++ 作为用例讨论类型反馈的应用。
类型反馈直接应用于 Smalltalk,我们期望能达到与SELF的相似的加速。尽管存在一些语言特性不同(如,原型与基于类的继承),但是这两个语言还是有非常相似的执行特性(如,高频率的消息发送,密集的堆分配,使用闭包来实现用户自定义的控制结构等)因此效率低下的原因非常相似。
C++ 的执行行为(和语言原则)与 SELF 差距非常大,但是尽管如此我们依旧相信它会从类型反馈中受益。首先,巨大 C++ 程序的测量 [16] 已经表明 C++ 程序的调用是 C 程序的五倍,然后 C++ 的虚函数的平均大小只有 30 条指令,是 C 函数的六分之一。第二,我们已经测量的两个 C++ 程序(见 7.3.1 节)在到处使用虚函数时,速度减慢了 1.7 和 2.2 倍,证明当前的 C++ 编译器不能很好地优化此类调用。第三,我们预计 C++ 程序员在将来会使用更多的虚函数因为他们变得更熟悉面向对象的变成风格;例如,面试框架 [92] 的最近版本比起之前的越来越多的使用虚函数了。
给出如下具体的用例,DOC 文档编辑器在测量 [16] 中是每 75 条指令执行一个虚调用;得出一个 C++ 虚调用使用大约 5 条指令且通常会导致两个 load 暂停和一个间接函数调用暂停,我们估计这个程序花费大约 10% 的时间来调度虚函数。如果类型反馈可以消除大部分虚函数调用,且如果 C++ 中的内联的间接受益与在SELF中测量的相似(即,总的节省时间是单个调用固有开销的 4-6 倍),则巨大的加速是可能出现的。
为了类型反馈的效果比较好,每个调用点的接收者的动态数量必须靠近一,即,一个或者两个接收者应该是主要的。C++ 中大部分的调用点具有这个特性[17,57],其它的面向对象的编程语言也是类似的(即,Smalltalk,SELF,Sather 和 Eiffel);这是为什么内联缓存 [44, 70] 在那些动态分发作为实现的语言上是工作良好的。因此,我们期望类型反馈在这些语言上工作良好;更高频率的动态分发调用,更能从类型反馈中受益。
类型反馈也应用在带有类型依赖通过操作符的语言(即,APL 和 Lisp)。如果参数的精确类型实现是未知的,所有的这类语言的操作都是昂贵的,但是如果类型是已知的,则会是非常廉价。例如,Lisp 系统可以使用类型反馈来预测浮点类型作为浮点密集程序的常用算术操作,从而替换静态的整型预测与通过调用运行时例程来处理所有其他类型,就像当前的 Lisp 系统通常所做的那样。
5.8 相关工作
5.8.1 静态类型预测
前代的系统已经在内联操作上使用静态的类型预测,这依赖于它们操作数的运行时类型。例如,Lisp 系统经常内联泛型算术的整型用例然后结合调用一个运行时系统的例程来处理其它类型。Deutsch-Schiffman Smalltalk 编译器是第一个面向对象的系统会为通常的消息名,如 ”+“ 预测整型接收者[44]。但是,没有一个系统像我们的系统一样动态预测类型的;它们没有反馈。
5.8.2 客制化
其它的系统使用类似于客制化的机制,这是运行时类型反馈的极致形式。例如,Mitchell 的系统 [97] 将算术操作特例化为操作数的运行时类型。相似地,APL 编译器为特定的表达式[80, 51, 61]生成特殊的代码。对于这些系统,HP 的 APL 编译器[51]非常的灵活。这个系统在一条一条的语句的基础上编译代码 。为了执行 APL 相关的优化,编译过的代码会根据特定的操作数类型(维度数量,每个维度的大小,元素类型等)被特例化。这种也叫 “硬”编码可以更高效的执行比起通常的版本因为一个 APL 操作的开销是依赖于实际参数类型而变化的。如果代码被用一个不完整的类型来调用,会有一个新的带有比较少假设的版本被生成(也叫”软“代码)。
相似的,Chambers 和 Ungar 为 SELF 引入客制化:已编译的代码被客制化为他们接收者的类型,因此相同的源方法会有不同的翻译,这是由于使用了不同的接收者类型。类型反馈好于客制化:
- 类型反馈可以为所有的发送提供接受者类型,而客制化只能在客制化的函数里提供当前自己的类型。
- 类型反馈可以优化多态调用而客制化不能;
- 类型反馈是可选的–编译器可能会在一个发送上使用而在另一个发送上不使用。客制化(SELF 中的实现)是强制的,所有的代码被客制化到接收者类型里了。
在所有提过的其它系统中,运行时类型信息只是在代码初次编译时被使用。比起本节描述的系统,编译更激进:编译器尝试尽力做到最好的优化,使用(运行时)编译时存在的信息;然后,它从不重新访问代码除非一些异常发生(即,如果一个类型预测失败然后编译器不得不生成少量的特定代码)。然后,当这些系统使用运行时类型信息客制化代码时,它们不使用类型反馈。作为一个结果,这些系统提供很少的有效信息给编译器。即使,编译器可以获得接受者和方法的参数类型或者正在编译的程序,它不能优化那些带有运行时类型信息的方法的操作因为该方法还没有被执行。作为对比,类型反馈系统使用更完整的运行时信息;在我们的系统中,通过延迟优化直到代码已经被经常执行时进行来达成,在批处理式的类型反馈系统通过在优化前执行完整的“训练”运行来达成。
5.8.3 全程序优化
前代系统已经尝试通过其它方法消除动态分发。例如,Apple Object Pascal 链接器[8]将动态分发的调用转为静态绑定的调用,这种是在一个类型已经确定只有一个实现的情况下进行(即,系统只包含一个 CartesianPoint 类不包含PolarPoint类)。这种系统的缺点是仍然会有过程调用的开销即使是非常小的被调用者也有,且一定不会优化多态调用,且排除了通过动态链接的可扩展性。
某些形式的类型推断可以推断具体的接收者类型,从而使编译器能够内联发送。例如,Agesen et al.[5]描述的推理器可以推出一个SELF程序中每个表达式的一组具体可能存在的接收者类型。比起类型反馈信息,类型推理可能会为一些发送计算出更好(更小)的集合因为它可以保证不存在未知的类型。虽然,对于有些发送,信息会变差,例如,即使理论上有几种类型,但实际上只有一种可能出现。类型推理系统对于真正的面向对象的语言只是开始去合并,所以现在还为时过早以优化目的来评估它们的价值。
“全程序”优化的主要劣势是(如确定的类型推理或者链接时优化):
- 首先,整个程序可能不是对优化器全部有效的。今天的工作站上的大部分程序都是动态链接的,因此编译器无法知道程序的确定的类型集合因为“链接时间”被延迟到了运行时间。即使程序硬编码了动态链接库的版本(即,拒绝执行其它版本),虽然已编译的库的版本是已知的但是优化仍然会无法执行。最后,即使这个问题被解决,优化的扩展能力仍然会被动态加载的用户自定义的库限制(即,如同“插件”模块存在于通用的工具如字处理和电子表格)。
- 第二,全程序优化可能代价比较高(因为大量的代码要被分析)而难以被集成到一个快速周转的环境中。
- 第三,不清楚在缺少画像信息来指导优化的情况下全程序优化的效果如何。但是,一旦使用了画像信息,优化器就可以使用画像信息的类型反馈而不是执行一个全局的类型流分析。换句话说,全局分析是否可以显著地提高基于类型反馈的系统的性能还有待观察。
5.8.4 内联
内联已经在过程式语言被广泛地研究了[29,36,39,62,74]。对于这些语言,内联非常地简单因为绝不(或者只是少量)使用动态分发。此外,内联候选很容易被分析因为空间和时间开销在大部分的语言结构上是已知的。相反地,基本没有在纯面向对象的语言中有过实现的信息因为这类语言的每个单一操作都包含动态分发,比如,算术、布尔操作和控制结构。
5.8.5 基于画像的编译
Dean 和 Chambers [40] 描述一个基于 SELF-91 编译器的系统,这个系统使用第一编译作为一个“实验”且记录内联决定和它们的好处到一个数据库中。使用一个发送的环境(即,有接收者和参数的已知信息),然后编译器在后面的编译会搜索这个数据库。(系统绝不是用动态重编译和类型反馈,所以如果一个方法已经内联了多次,或者在已编译的方法被抛弃掉时它可以只利用记录信息。)比起我们基于代码的启发式,这个系统可能可以做出更好的决策因为它记录了更多关于调用的上下文信息以及通过内联启用的优化。
基于 C++ 程序的测量,Calder 和 Grunwald [17] 争论了类型反馈会为 C++ 带来的益处。不幸地是,他们显然不知道前面的工作;他们提出“if conversion”和内联缓存似乎是相同的[44],和一个“if conversion”相同于类型反馈的提议扩展(首先出现在[70])。
一些传统语言的现代编译器从执行画像信息到执行分支调度均使用了运行时反馈来减少缓存冲突[95,96]。其它系统使用画像信息来辅助经典的代码优化 [30],处理内联[29,94],追踪调度,和寄存器分配[136,98]。
Hansen 描述了一个 Fortran 的自适应编译器[63]。他的编译器在运行时优化了 Fortran 程序的内层循环。他工作的主要目标是最小化运行一个程序的总开销,这类程序只大概只会执行一次。所有的优化可以通过静态的方式应用,但是 Hansen 的系统尝试合理的分配编译时间从而可以最小化整体的执行时间,即,编译和运行的总时间。SELF 尝试达成一个相似的目标,即快速地优化程序的重要部分同时最小化用户可察觉的停顿。
5.9 总结
一个面向对象语言的优化编译器无法单独从源码上获得足够的信息。例如,编译器通常无法判断消息发送的精确接收者类型,或者程序在哪花费了最多的时间。“延迟”编译解决了优化这类程序的问题,它推迟了处理难题直到更多的消息被知道。然后,当这些信息是可用的时候,优化更简单且更高效:使用额外的信息,优化编译器可以用更少的时间生成更好的代码。(我们将在第七章和第八章中用经验数据支撑这一论点。)换句话说,延迟赢。
具体地说,SELF-93 用自适应重编译和类型反馈实现了延迟编译:
- 自适应重编译 优化了一个应用的“热点”。初始状态下,代码通过一个快速,非优化编译器生成。如果一个非优化的方法被频繁使用,它会被重编译因而不会因为长周期地运行非优化代码导致变慢。
- 类型反馈 允许编译器内联任意的动态分发的调用即使明确的接受者类型静态不可知。使用在之前执行调用下收集的类型信息(类型反馈),编译器可以优化一个动态分发的调用通过插入一个通用场景的类型测试然后内联-替代被调用者。换句话说,总是在类型A中找那种动态分发调用可以被类型测试(验证接受者类型是A)替换的目标方法然后内联被调用者的代码。
这两种技术都不依赖于 SELF 语言的特定功能,我们相信两种技术都是有用的可以优化其它的静态类型或者动态类型面向对象语言(即,CLOS,C++,Smalltalk)和有类型依赖通用操作符的语言(即,APL 和 Lisp)。此外,类型反馈也可以在静态编译而不是动态编译中实现。
类型反馈和自适应重编译一起提高了面向对象程序的性能通过移除大部分消息发送的固有开销。我们已经为 SELF 设计和实现了这些技术;下一章详细说明实现细节,接着后续章节评估这个性能。
6. 一个SELF 优化编译器
基于为了优化目的使用内联缓存中的类型反馈信息的想法,我们开发了一个SLEF的新优化编译器。这个编译器有三重设计目标:
高编译速度。因为 SELF 系统使用动态(即,运行时)编译,编译器需要尽可能的快来最小化编译暂停。如果有可能,我们会避免昂贵的全局优化和分析然后限制我们使用时间复杂度接近线性于源代码大小的算法。
稳定,对于大程序性能稳定。第二个设计目标是在面向对象程序(即,程序使用数据类型而不是整型或者数组)上超过前一代 SELF 编译器性能,特别是为超大程序提供更好的性能。此外,性能应该合理稳定的:在源程序上小的改动(即,不影响算法复杂度的改动因此直观上应该是性能中立的)不应该显著地影响性能。
简单。前一代 SELF 编译器[21]包含了超过 26,000 行 C++ 代码且使用了许多编译优化。例如,控制流图会跟随类型分析的结果而改变,这会反过来影响分析的结果。因此,编译器相当难以理解和修改。由于配置了新发现的类型反馈信息,我们决定在我们新的编译器中省略类型分析因为我们预计额外类型信息的好处会补偿和超过缺失分析带来的劣势。(由于我们无论如何都知道接受者类型,类型分析可以做的就只是删除一些类型检查。)大约有 11,000 行代码,由此产生的编译器比老的简单得多。
通常,在设计新的编译器的时候我们选择 “RISC-style” 方式,并且只有在检查生成的代码表明值得这样做时才包含新的优化。基于前一代 SELF 编译器的经验,我们一开始就包含客制化,拆分和块创建优化,因为它们已经被证明是有效的。
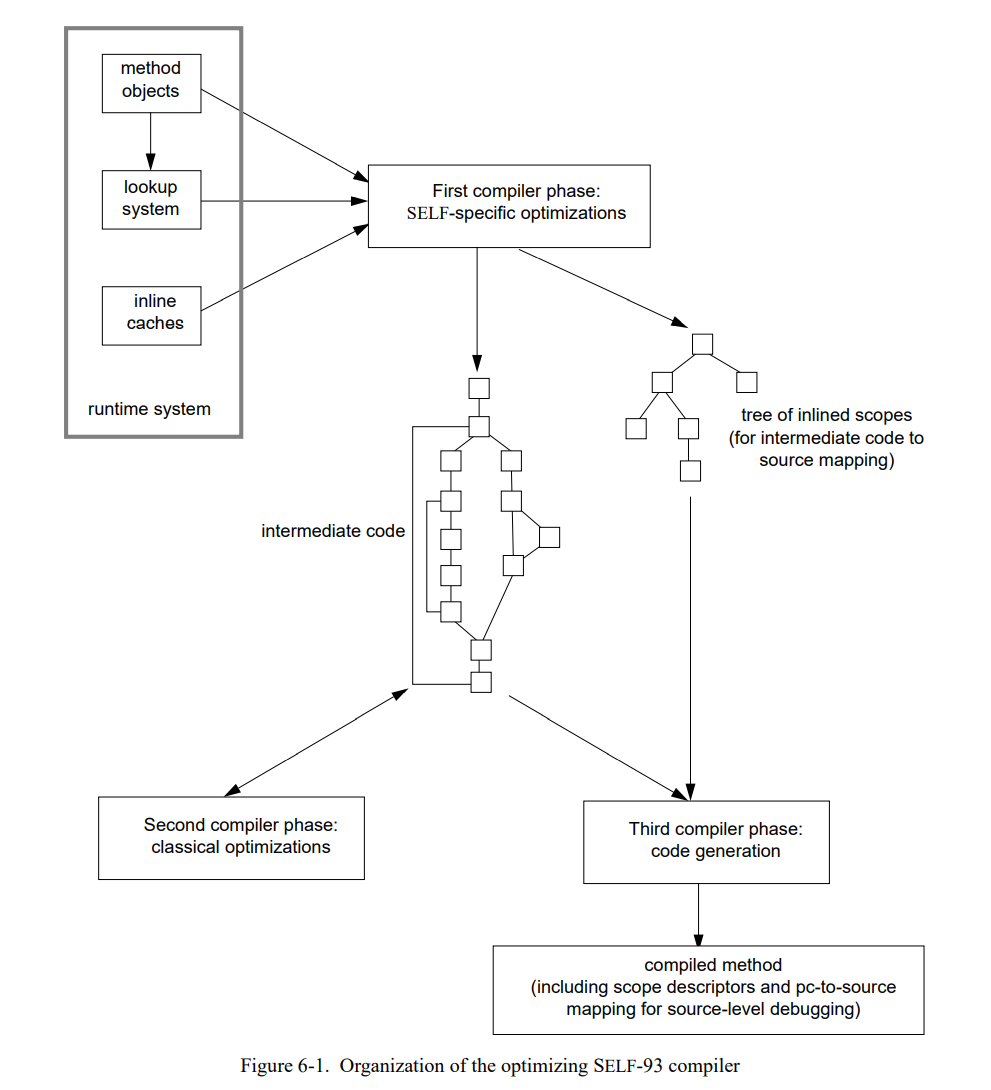
图 6-1 显示这个优化编译器的概况。这个编译器分成了三部分。第一部分执行高级别的优化如基于类型反馈的内联和拆分,生成中间代码节点图。然后第二部分执行一些通用的优化如拷贝传播,死代码消除,和寄存器分配。最后,第三部分完成由中间控制流图生成机器码的过程。
6.1 前端
编译器的第一部分由方法对象(即,源方法的字节码表示)生成中间控制流图。基础的代码生成策略是直接了当的然后依赖于第二部分消除冗余。前端主要的复杂度是内联和拆分算法。
接下来的几节重点介绍前端的特定部分:从程序的内联缓存获得类型反馈信息,决策内联的方法,处理特殊场景。
6.1.1 查找接受者类型
每当编译器遇到发送的时候,它尝试决定可能的接受者类型然后如果需要且可行的话内联发送。表达式对象(图 6-2)表示源程序级别的值如消息接受者,参数或者结果。
在消息内联的时候表达式对象会被传播从而保持追踪已知的类型。例如,表达式 3+4 的数字字面常量 3 和 4 生成的常量表达式如果已经内联则变成 “+” 方法的接收者和参数表达式。
如果接受者是一个常量或者 self,这个接收者类型是总所周知的。(后一种场景中,因为客制化会为每个特定的接收者类型创建一个分离的已编译方法)。如果接收者表达式包含了未知类型,编译器检查前一个编译版本的相应内联缓存(如果任意)。如果它找到一个内联缓存且判定它的信息是可靠的(如下),编译器会根据内联缓存的接收者映射添加 MapExpressions 到 表达式对象。生成的表达式对象总是一个 MapExpression 因为它包含了至少两个类型,一个通过类型反馈获得的 MapExpression,和一个 UnknownExpression。例如,如果一个方法有两个可能的结果类型,无论何时作为控制流合并的一种结果类型信息会被合并从而 MergeExpressions 也被创建。
为了查找当前被内联发送对应的内联缓存缓存,编译器持续追踪当前“被重编译者的范围”和在老代码的当前位置。因为每个已编译的方法包含它内联范围的描述,编译器可以通过方法中的调试信息中的相关信息找到新的被调用者(如果被调用在旧的已编译方法中被内联)或者通过检查内联缓存。
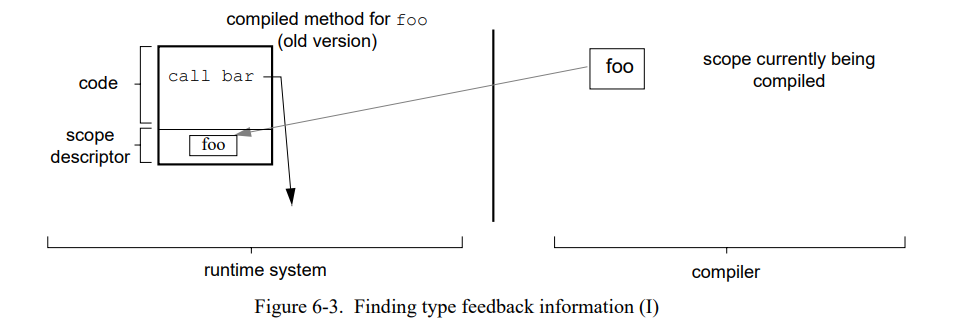
一个例子会阐明这个过程。假设方法 foo 发送了 bar,bar 反过来发送了 baz;同时假设编译器当前正在重编译 foo。初始状态如图 6-3 所示(运行时系统中的数据结构总是显示在左边,编译时数据总是显示在右边)。当为 foo 源方法生成中间码的时候,编译器遇到 bar 的发送。在 foo 老的已编译代码中查找它的当前位置,编译器找到 bar 的内联缓存。当内联这个发送时,编译器沿着内联缓存到它的单一目标然后开始生成 bar 的中间代码(图 6-4)。
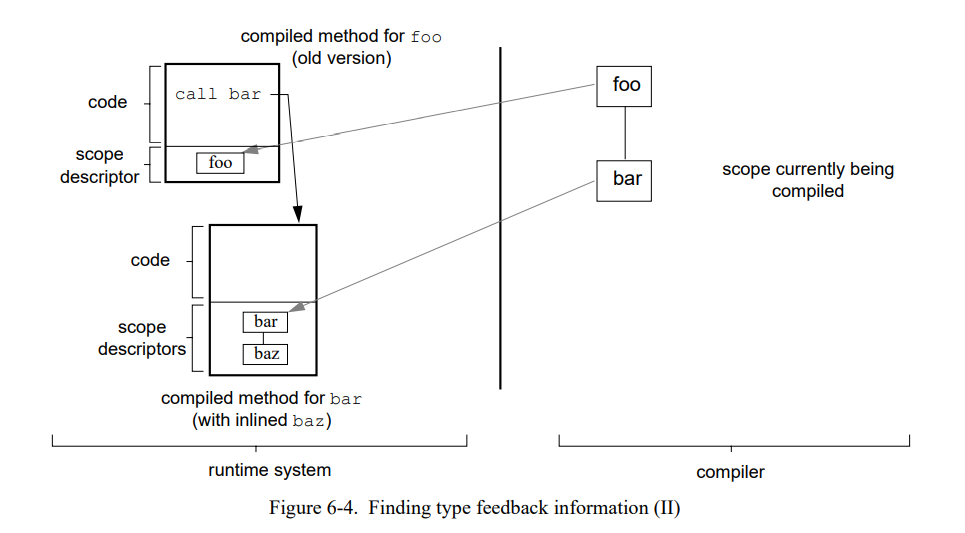
现在,编译器在 bar 中遇到 baz 的发送。这时,在老的已编译代码中没有 baz 相关的内联缓存因为这个发送被内联了。但是编译器可以从 bar 旧的已编译方法的范围描述符中获得发送的接收者类型然后继续内联 baz (图 6-5)。
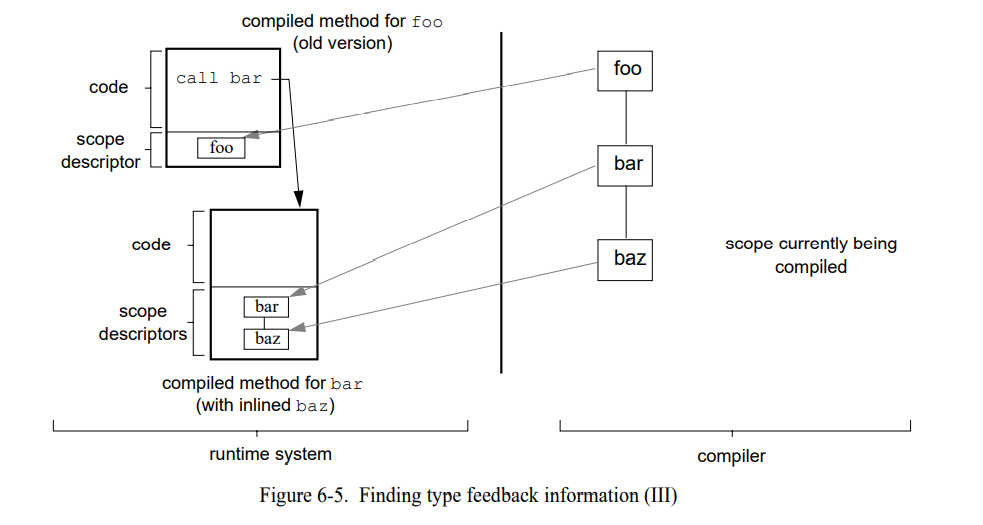
因此,通过老版本的已编译代码的发送链(可能内联也可能没有),编译器可以较小开销地获得类型反馈信息。
6.1.2 基于代码的内联启发式
一旦编译器确定了可能的接收器类型,它就会执行查找以找到目标方法。如果用给予的接收者类型查找成功,编译器不得不决定是否内联目标方法。(因为一些原因编译时间内的查找可能会失败,如动态继承。)以下几个原因表明这是个困难的决定:
- 只基于方法是难以评估决定的影响范围的,因为在内联的方法可能导致其它方法也被内联,然后编译器不能简单的决定哪些其它方法也可以被内联。SELF 的纯基于消息的语言模型让预测尤其的难因为几乎所有的源码字串都是动态分发的发送,它的目标还是未知的。
- 因为相同的原因,难以确定如果一个发送被内联了能节省多少程序源码的执行时间。只有当方法非常小(少于一个或者两个发送)能在内联导致的代码大小开销花费较小然后能有个好的速度提升。
- 最后,即使我们可以准确地估计内联特定发送的影响,整个的性能影响也依赖于其它内联决策导致的结果。例如,内联一个特定的发送在一个场景中是有益的但在另一个场景中却会伤害性能因为其它的内联发送会增加很多的寄存器压力导致重要的变量不得不变成栈上分配的。另一个重要的限制是编译时间–越多的内联,编译暂停越长。这会超过单次编译:如果一个方法从几个地方调用且被错误地内联,它使得这个方法相关的所有编译都变慢,不只是单次编译。
由于这些不确定性,一组简单的启发式规则似乎不太能满足,最好的方式是“先试试看”。例如,编译器可以首先使用乐观假设来创建一个内联范围的树(可能非常大)然后查找每个独立决定的开销和收益从而提出一个修建过的树。换句话说,它会先尝试内联一些函数组然后如果内联没有收益就会回退。
当这个策略保证了生成代码的最好质量的同时,它可能会导致系统性能和系统复杂度变为次优。首先,内联过程已经消耗了大部分的编译时间(见第 9 章)。因此,构建一个 “乐观” ,巨大的调用树就编译时间而言可能很昂贵。第二,“撤销”一个内联决定的实现是很临时的可能会显著地增加编译器的设计复杂度。因为这个原因,我们没有进一步推行这个策略。
Dean 和 Chambers 提出了另一个策略[40],使用第一次编译作为“乐观实验”然后记录决策和它们的收益到内联数据库中。在使用发送的环境(即,接收者和参数的信息是已知的)时编译器会搜索前一次编译“实验”的数据库然后做出已知信息下的最好的内联决策。虽然 Dean 和 Chambers 报告了令人鼓舞的结果(编译速度提高了 2.2 倍,而执行速度最多降低了 1.4 倍),他们的研究只包含了四个程序且没有考虑基于类型反馈的内联,因此这边编译器描述的技术的有效性时未知的。一个内联数据库会添加相当多的代码到编译器中:Dean 和 Chambers 的实现由大约 2500 行代码组成,这会使我们的编译器增加 20% 的大小。遵循我们的 RISC 式设计策略,因此我们决定不 包括这样一个机制,直到它的必要性被证明。
相反的,SELF-93 使用了前代 SELF 编译器的简单局部内联启发式,然后使用了额外来自于运行时系统的反馈。当前,编译器使用两组启发式来做内联决策,基于代码的启发式和基于源程序的启发式。
Code-based heuristics 查找前一版已编译代码(如果有)来决定内联决策的大小影响。这种方式的优势是它不只是查看单独的源方法而是由更大的范围:源方法 A 的已编译方法不只是 A 的代码而是会包含内联过的调用。因此,它让我们观察到了真正的已编译方法的大小,而不是“源方法大小”的模糊定义。因此,这个大小是最接近于内联决策影响的代码大小的比起仅基于源代码指标的估计。从某种意义上讲,基于代码的启发式采用已编译方法作为原始“内联数据库”。自然地,只有优化过的方法可以使用因为未优化的方法不是优化代码的大小的一个好的预测指示(因为几乎每个发送都是实现为一个十个字大小的内联缓存)。
当前地,基于代码的启发式包含四个规则:
- 如果待编译的方法的预估大小已经超过阈值(当前是 2,500 条指令),拒绝方法被内联。这条规则是设计来限制已编译方法最大大小的。(限制大小的估计是基于中间控制流图的节点成本总和。)
- 如果被调用者很小(小于 100 条指令,或者 150 条如果方法有块参数),允许它内联。
- 如果被调用者大于阈值,拒绝它,除非正在被编译的方法的预估大小即使被调用者被内联也可以保持足够小。这个例外允许大方法被内联在调用它们的小的”wrapper“方法,因此,这样总大小不会比被调用者本身大很多。
- 如果上面的规则都没有被应用(或者如果没有以优化的被调用者是有效的),编译器使用基于源码的启发式作为反馈。这个源码的长度是用消息发送的数量来定义的,然后对于”廉价“的发送像局部槽访问会有一些更正。没有超过阈值的方法会被内联只要评估的总大小允许(见上面个的规则 1)。一些总所周知的控制结构被特殊处理(例如,一个for 循环的消息实现)。
通常,第一次重编译基本是会使用基于源代码的启发式,因为老的代码是完全没有优化的因此不能被基于代码的启发式使用。但是,基于代码的启发式在后面的重编译中经常被使用,即,用一个更新的方法替换一个优化过的方法。通过保存前一个已编译方法大小的记录可能可以提高基于代码启发式的效率(即一个”内联数据库“只需要保留已编译优化方法的大小),但我们不尝试去实现这样的机制。
更传统语言(如,GNU C[120])的编译器使用中间代码的大小来引导内联决定,在优化中间代码之前或者之后做这个决定[109]。这种方式依赖于内联候选者必须要在编译时拥有有效的中间代码;这在 SELF 中是没有场景的因为内联候选在一个更早的时间被编译过了。
6.1.3 拆分
Splitting 通过拷贝控制流图[23, 22, 24]的部分信息避免类型测试。我们使用拆分的主要目的是允许编译器为布尔表达式或者相对较小影响的 if 语句生成好的代码。用 Chambers 的术语来说,我们的编译器使用了扩展勉强拆分[21],即,它可能会拆分一个发送即使这个发送不是立即跟随在控制流中的合并之后(“扩展拆分”,见图 6-6),但是在无收益的情况下不会拆分一个发送(“消极拆分”)。当前系统只是拆分拷贝代码量(“其它代码”在图 6-6)比较小的;目前限制是 20 条指令。
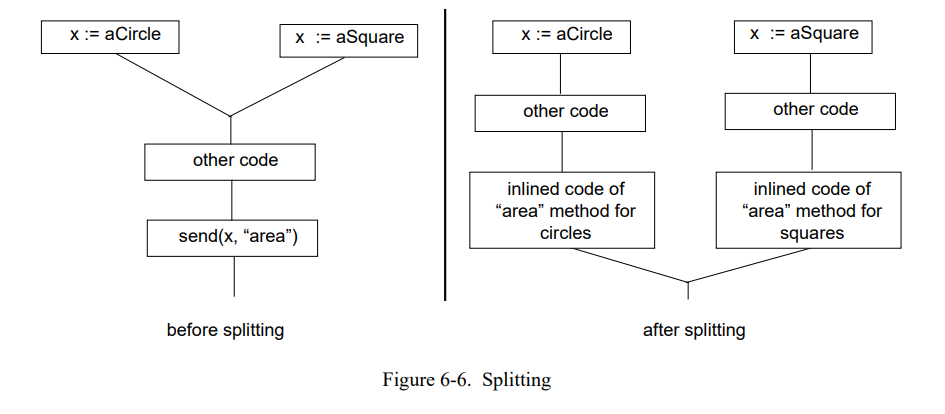
不像之前的 SELF-91 编译器,我们的编译器不执行循环拆分,即,它不会创建循环体的多个副本,每个副本都专门用于特定类型。我们有两个不包含循环拆分的理由。首先,我们不能确信它会显著地加速非平凡程序,因为这些程序通常不被非常小的单层循环支配,而单层循环时才是能得到收益的循环。第二,循环拆分实现代价相当的高因为它需要类型分析来实例化它的收益[21]。
替换前端的拆分执行,我们通过后端优化获得相似的好代码。Heintz[64] 为 Smalltalk 编译器提出了一个优化(叫做“重路由前置”),其在相似的传统语言的后端优化是众所周知[3,10]。我们选择了拆分因为它可以生成好的代码而不用昂贵的分析,因此对于创建一个快速编译器是有帮助的。
6.1.4 不常见的陷入
在 SELF 中,许多操作都是可能有不同的输出的,编译器为这些普通的场景创建特定的代码用来提高效率。例如,编译器根据类型反馈信息特殊化消息发送和为预测(普通)场景生成优化代码。但是,不普通的场景需要怎么编译?如果一个整数加法移除,或者一个发送有在之前重为见过的类型呢,怎么办?
6.1.4.1 忽略不常见场景的辅助
一个明显正确的策略是总要包含所有类型测试中的“otherwise”条款(或者溢出检查)然后为这些场景包含未优化的代码。典型地,这个代码会执行非内联的消息发送。例如,一个通过类型反馈优化的发送如下所示:
1 | if (receiver->type == PredictedType) { |
但是,这个简单的策略有几个严重的缺点:
- 代码大小。非内联发送(即,内联缓存)消费了 许多代码空间(至少十条指令)。因为许多发送都是使用类型预测内联的,处理罕见场景的代码可能会显著地消耗总代码空间的一大部分。
- 编译时间。类似地,一个包含所有“特殊”分支的巨大的控制流图会减缓编译。
- 减缓普通场景。如下一节表明的,包含非普通场景的代码可能会减缓普通场景,特别是发送有块参数的时候。
最后一个缺点是最严重的。图 6-7 显示表达式 i < max ifTrue: [vector at: i] 将要生成的代码,包括所有不常见的情况(假设 i, max,和 vector 是局部变量且被预测为整型)。
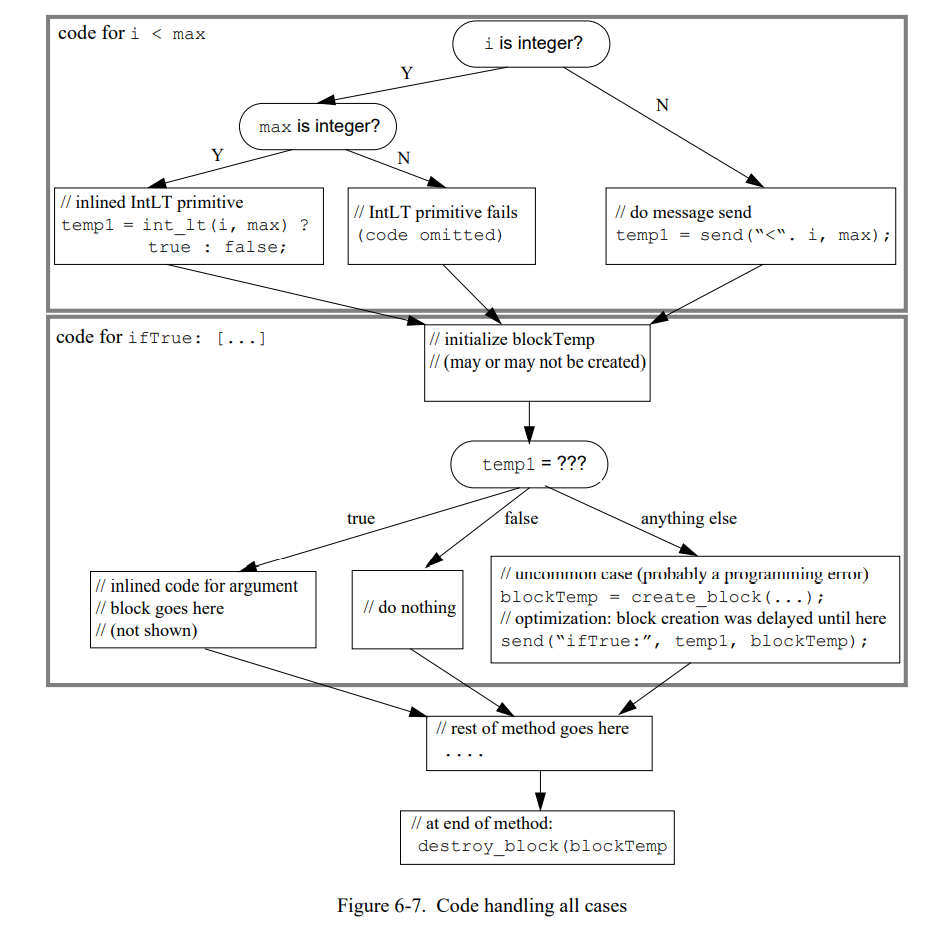
如果代码只是不得不识别异常场景但不需要完全处理它们,就会变得比较简单。(John Maloney 首先提出这个优化,在SELF-91 编译器中第一次实现。)在 SELF-93 编译器,编译器认为不太可能发生的情况的代码会被替换为一条陷阱指令。然后例子编译成图 6-8 显示的样子。
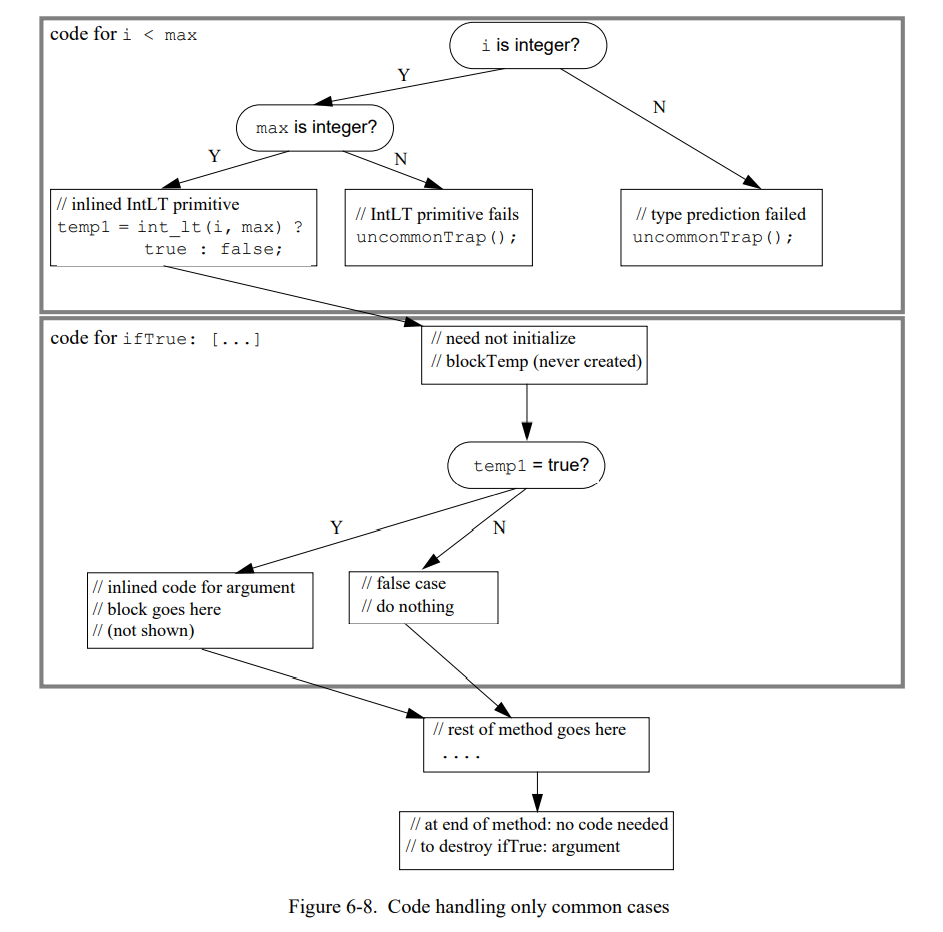
这个版本的代码有几个优势;例如,它消除几个分支和赋值同时创建两个发送和一个闭包。因此,静态代码大小显著降低,加速了执行。因为不常用的场景不会合并到通用场景的代码里,使用非通用的陷阱可以提高类型信息的精度。例如,编译器现在知道 temp1 必须是 true 或者 false(在这之前,它可以是任意的东西因为“<”发送的返回值类型(非整型场景)或者 IntLT 错误原语是未知的)。因为我们的编译器没有执行广泛的类型分析,所以优势不明显;但是对于前代编译器类型分析是基本的功能[21]。
同时,上面的代码会消除参数块相关的固有开销因为它不会再被创建。除了直接保存(初始化 blockTemp 和推出方法时销毁块),为代码生成消除块有显著地收益。如果块可能可以被创建,通过块的变量访问(vector 和 i)不会被寄存器分配因为它们可能通过块的词法链接进行上层访问,因此必须在内存中。至少,这两个变量的当前值必须在每个非内联的发送前写入内存,因为每个这样的发送都会调用这个块。通过消除这个块,编译器同时可以消除这些内存访问。(相似地,如果这个块赋值了一个局部变量,这个变量不得不栈存储,或者不得不在每次非内联发送之后重新从内存中加载这个值。)
到此为止,不需要编译代码来处理非通用的场景可以有显著的性能优势是非常清楚的。即使被提高的代码不是完全处理非通用场景的(如,非整型 i),语言语义会被保存因为代码仍然需要验证所有的类型预测。但是,如果一个非通用场景已经发生会发生什么呢?即使这种场景非常的罕见,它们可能且也需要以某种方式被处理。
6.1.4.2 不常见的分支扩展
SELF-91 编译器通过调用运行时例程来替换非通用场景的代码。如果非通用场景曾经被处理过,运行时创建一个“非通用的扩展”然后修复调用以引用此扩展程序。这个扩展是原已编译代码的延续,即, 它包含了所有从失败点到函数结束的代码,扩展几乎是无优化的从而不会创建更多的扩展。因此,如果编译器预测 i 会是一个整数且预测失败,对 i + 1 的代码将会是如下样子:
1 | if (i is integer) { |
无论何时 i 类型预测失败,代码会跳到这个非通用扩展,发送 + 消息,然后执行这个扩展的大部分非优化代码。因此,通用场景是快速的,但是非通用场景可是相当的慢。
这种方法有两个问题。首先,编译器在判定什么是“不常见”时不得不做出非常谨慎的平衡。如果编译器太保守(只让极端罕见的场景不普通),通用场景的代码将会变慢。如果它将太多的场景处理成非通用的,而这些场景实际上经常发生会导致性能不好。例如,前一代编译器类型推导 + 发送总是有整型接收者然后让非整型接收者变为不普通。因此,所有使用浮点算术的程序会频繁地执行非通用扩展因此性能很差。因此,系统性能时脆弱的:如果编译器预测是对的,性能会很好,但是,如果它们是错的性能会急剧下降。(见 77 页 7.4.2 节)。
第二,这种方式不是空间友好的。因为会对每个非通用场景创建一个新的扩展,一个方法中遇到几个“非通用”场景就将需要几个非通用扩展,因此,会有重复代码。非通用扩展会变得巨大因为它们相当地不优化;同时,因为“非通用”场景总是发生在方法开头(如,第一个 + 发送),扩展程序将会包含整个方法。
6.1.4.3 非通用的陷阱和重编译
为了避免这些陷阱,SELF-93 编译器不使用方法扩展来处理非通用场景。相反地是,它将非通用场景看作是运行时的一种反馈;图 6-9 显示整个处理过程。前几次非通用陷阱被执行时,被假定为时不需要优化的场景。例如,程序员可以传递一个错误的类型给方法,导致一个“消息未识别”的错误。于是,已编译的代码保持不变,只是包含非通用的陷阱的栈帧去优化,即,被几个未优化的栈替换;然后,继续执行。退优化在第十章里会被详细描述;因此,我们不在这进一步描述。
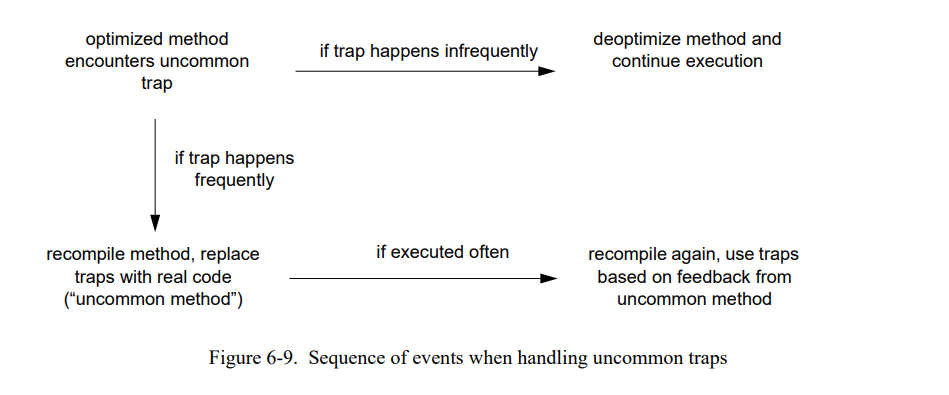
如果更频繁地执行不常见陷阱,这并不罕见,通常是编译器预测错误的结果。例如,一个程序直到当前都是整型然后开始使用浮点数据,因此所有的算术操作开始都是错误的。因此,如果陷阱经常发生,非通用的陷阱处理者会丢弃有问题的已编译方法从而退优化,然后创建一个新的版本。新的版本在它的方式中会更保守只有少数场景会是非平凡的;因此,它会运行得更慢。为了最终重优化这个方法,系统把它标记为“非通用的“然后让它执行一会。
如果新的已编译方法总是被执行,它总会被选出来重新编译。在这个时候,编译器可以再次更积极地使用未通用的陷阱。当这个方法被执行时,根据”非通用“场景填充内联缓存无论这些场景实际是否发生。因此,这些内联缓存的状态揭示了他们是否在考虑非通用(内联缓存是空的)或者不在考虑了(发送至少被执行一次)。在重编译之后,方法被特化到程序使用的一组新的类型上。
因此,SELF-93 系统在需要时对于非通用场景会用更少特化的代码替换过度特化的代码,而不是用通用的延展来扩展特化的代码。用这种方式处理非通用场景有两个优势。首先,在使用非通用陷阱时编译器可以更激进;如果编译器作者的”赌“变成错误的,重编译会纠正错误。第二,它消除(或者至少减少)”好程序“(编译器作者下注的地方)和”坏“程序(赌输的地方)之间潜在的巨大性能差异。(7.4 节将通过一些测量重新审视这个论点)
精明的读者可能关注到了上述方案的陷阱:如果”学习周期“在第一个和第二(最后)重编译间非常短,非通用方法的内联缓存可能没有完全的反应程序的类型使用,因此重编译代码可能很快会再陷入一个非通用陷阱因为它太特化了。因此,系统会追踪已编译代码的版本然后使用指数回退策略来确定允许重新优化之前的最小调用次数。每次方法不得不因为非通用陷阱重新编译,最小的调用次数被乘以一个常量。因此,”学习周期“最终会变得足够长从而获得方法的类型使用场景。
6.2 后端
编译器后端在中间码上执行一些优化然后从中生成机器码。编译器不执行成熟的数据流分析或者图着色寄存器分配为了最大化编译速度。这节的剩余部分会讨论 SELF-93 后端的关键方面。
6.2.1 中间码格式
这个中间码控制流图由大约 30 种不同节点组成。大多数节点类型表示简单的类RISIC操作如赋值,堆加载和存储,或者算术。这些节点通常翻译到一条机器指令。相比之下,一些节点表示特定 SELF 的操作被翻译到特定的代码片段通常有几个机器指令。例如下面几个宏结点:
- Prologue 节点展开成机器的导言代码,包括接收者类型检查,栈溢出测试和栈帧分配。
- TaggedArithmetic 节点实现带标记的整型算术;已生成的代码检查参数的标记(如果需要)然后也检查结果是否溢出。带标记的算术节点有两个后继,一个是成功的场景(两个参数都是整型然后结果不会溢出)而另一个是失败场景。
- ArrayAccess 节点实现访问对象和字节数组,包括边界检查和字节数组存储的值检查(只有 0 到 255 可以被存储到字节数组中。)如同带标记的算术节点,数组检查节点也有两个后继。
- MessageSend 节点实现一个非内联的消息发送以及为发送生成一个内联缓存。一个消息节点有两个后继,一个正常的返回,另一个是非局部的返回。
- TypeTest 节点实现一个 N-维 类型测试然后有 N + 1 个后继(因为有 N 个类型被测试和一个“例外”场景)。把 N-维分支表示为一个简单的节点而不是一系列简单的二维分支简化了控制流图且允许更多有效的测试代码;例如,可以比较简单地用测试序列填充分支延迟槽而不用实现一个通用的延迟槽填充算法。
- BlockCreation 和 BlockZap 节点实现了块的创建和销毁。块创建涉及调用原语而块销毁更简单。(见6.3.3节)。
通常,如果一个功能不能简单地表达为一些简单节点的组合,或者如果它允许编译器为特定结构生成更好的代码(否则只能通过引入更多的通用优化来生成代码而这会被视为代价昂贵的),又或者它能减少控制流图的大小(因此提高编译速度),我们就会引入特殊的节点类型。高级节点会牺牲代码质量的因为低级别的 RTL类型的中间语言可以暴露更多的优化机会。我们决定在这种场景下为了运行时性能牺牲编译速度。
所有的节点使用伪寄存器作为它们的参数;这些伪寄存器随后通过寄存器分配映射到机器寄存器或者栈区间上。伪寄存器被分成几种类型来帮助后端优化整合前端伪寄存器使用的知识。最重要的伪寄存器类型是:
- PReg 是最通用的伪寄存器格式。例如,前端为一个方法的局部变量创建 PRegs。
- SAPReg 是一个单赋值伪寄存器。即使可能存在几个节点同时定义一个 SAPReg (因为拆分),前端保证没有定义会扼杀另一个定义的。也就是说,确定的一个定义点会沿着方法可能的路径执行。因此,SAPRegs 可以自由的拷贝传播而不用计算到达定值信息。
- BlockPReg 是一个保存块和块创建和切换节点需要的额外信息的寄存器。像 SAPReg,它潜在的有几个定义点但不能自由的传播。
- ConstantPReg 是一个保存常量的伪寄存器;方法中的每个常量值都有确定的 ConstantPReg(即,如果相同的常量使用两次,两次使用的都是同一个伪寄存器)。
如同中间代码的节点一样,我们会引入特殊伪寄存器类型在每次都可以简化后端的任务(加速编译)或者允许我们执行特定的优化,而这些优化在没有特殊寄存器的情况下需要更多昂贵的数据流分析。
6.2.2 计算暴露块
后端的第一个阶段会计算暴露块的集合,即,可能会传递参数到其它已函数或者存到堆中的块。这些信息是重要的因为以下原因:
- 如果一个块没有暴露,它就不需要作为一个实际的对象。因此,编译器可以忽略它的创建,节省大量的时间(大约30条指令,不包括垃圾回收的开销)和代码空间(需要四条指令来调用块创建的例程和一条指令“切”块)。
- 如果一个块暴露,它需要在某些点上作为一个实际的对象。因此,编译器必须标记所有块向上访问的变量(即,在词法闭包范围里的局部变量和参数)为上级读或者上级写。每一个非内联的调用必须被认为是一个潜在的上级访问变量的使用或者定义因为块可以被被调用者调用。
计算暴露块集合是相当直接的。首先,一次遍历控制流图中的所有节点构造一个初始化集合。当块(更准确的是,BlockPRegs)被赋值到另一个虚拟寄存器或者是存储节点的源时它们会被加入到集合中。然后,我们通过添加所有词法包含块已经在集合中的块来计算初始集合的传递闭包。
作为附加效果,这个过程也会设置所有通过暴露块访问的伪寄存器的“uplevel-read”或者“uplevel-written”标志。然后,在向上访问的伪寄存器的每个定义点后插入 FlushNode 来保证向上读得到正确的值即便伪就寄存器被分配到物理寄存器上。(当前,向上写变量被寄存器分配模块分配到栈上且绝对不会被缓存到寄存器。)
6.2.3 定义/使用 信息
下一个编译器过程在一次遍历控制流图中计算每个伪寄存器的定义和使用。伪寄存器的定义和使用被记入到一个链接列表中且用基础块分组从而一个基础块内的所有定义和使用在局部拷贝传播中都是有效的。
6.2.4 拷贝传播
拷贝传播,后端实现的最重要的经典代码优化,被分割成两部分,局部传播(在基本块里)和全局传播。在每个过程中,编译器尝试传播 SAPRegs 或者 BlockPRegs (两者都是保证只有唯一的“真实”定义)和所有确定具有唯一定义的 PRegs。因为编译器不计算“到达定值”信息,它只能识别所有可能传播的子集。SAPRegs 表示了主要的寄存器因为入参和表达式栈项保证是单一赋值,因此这些限制并不严重。此外,类似于到达定值的信息在块里是很容易获得的因此局部拷贝传播可以传播多赋值寄存器。
如果被传播的伪寄存器是 ConstantPReg ,控制流图有些时候可以被简化为传播的结果。例如,TypeTest 节点中所有的后继中的一个在一个常量被传播到这个节点时会被消除。(回想一下,前端不执行类型分析,因此可能会生成冗余的类型测试。)
在拷贝传播过程的结尾,编译器消除未被使用的伪寄存器的所有定义,当定义点无副作用。(伪了保证源语言级别的语义,编译器不能消除类似于 1 + 1 的表达式即使结果没有用到,除非编译器可以证明不会发生整型溢出。)
6.2.5 寄存器分配
在执行所有的优化之后,在代码生成前最后的任务是寄存器分配。虽然已知的基于图着色[18]的算法总是能产生非常好的寄存器分配,我们却选择不去实现这个分配算法因为我们考虑它的编译时间花费太高了。作为替代的是,寄存器分配依赖于使用统计。
在执行全局寄存器分配前,一个局部的寄存器分配器分配位于基本块里的伪寄存器。首先,局部分配器扫描基本块里的所有节点从而识别哪个硬链接的寄存器(如保存输出参数的寄存器)被使用到块中。然后,对于每个位于基本块里的伪寄存器,分配器会尝试找一个基本块里完全没有用到的临时寄存器。通常,有足够多的临时寄存器从而能成功地分配基本块里所有的伪寄存器,因此局部寄存器分配非常地快速。
如果所有的临时寄存器在基本块里都至少被用一次,局部寄存器分配器会切换到稍微复杂的方式。为决定两个伪寄存器是否可以共享同一个临时寄存器(因为它们的生命周期不冲突),分配器为基本块的所有临时寄存器计算生命周期(生命周期通过位向量表示,在基本块里每个节点使用一位)。然后,对于每个未分配的局部伪寄存器,分配器尝试找一个临时寄存器,它还没有存在伪寄存器的生命周期里。如果这样的寄存器被找到,它会被分配且更新生命周期位向量。
这两个分配策略的组合非常的成功:局部寄存器分配器通常成功的分配所有可以局部分配的寄存器。因为这部分伪伪寄存器大约占全部伪寄存器的 50% 到 90%,局部分配器显著地降低全局分配器的负担。
全局分配器分配使用简单的使用统计算法分配剩余的未分配伪寄存器。每个伪寄存器有基于它被使用次数的“负重”,有最高负重的伪寄存器被优先分配。使用计数会被循环嵌套深度加重。为了简单和速度,全局伪寄存器的生命周期被表示为源码级别的语句,而不是由中间节点索引的位向量。为了测试两个生命周期是否重叠,确定一个范围是否是另一个的子空间或者字节码范围是否重叠(如果范围完全相同)就够了。原始生命周期很容易被确定:局部变量生存在整个方法中,而表达式栈条目从字节码产生它到字节码消费它之间存活。为了保证正确分配,拷贝传播过程更新伪寄存器的生命周期来包含新的使用点。
总之,SELF-93 的寄存器分配器非常的快速和简单但是尽管如此也产生了相当不错的分配,会在下一章展示测试的性能。尽管一个更复杂的(如,图着色)寄存器分配器无疑可以提高性能,但是它也在编译时间上消耗更多的时间。鉴于交互式,探索性的系统(见 第九章)对编译器的编译速度要求,我们相信当前的分配器代表了分配速度和分配质量间较好的妥协。
6.3 运行时系统问题
这一节讨论几个与运行时系统相关的低级别代码生成的问题:怎么有效的检查一个对象的类型,维护分代垃圾回收的写屏障,当它们词法闭包方法返回时无效(“zap”)块。
6.3.1 类型测试
类型测试是一个频繁的操作:无论何时编译器预测一个接收者类型(基于来自 PICs 的信息,或者基于静态类型预测),不得不在个别方法的内联体之前插入类型测试。因此,快速的类型检测时必须的。理论上,一个类型检测涉及对象类型的加载和与一个常量比较。所有的堆分配对象存储它们的 map (类型)到对象的第二个字中。不幸地是,这边有两个异常:整型和浮点数被表示为一个 32位立即数(即,不是堆分配的)因此无法显式的包含它们的 map;其次,类型被编码到标志位上。因此,一个类型检测首先不得不在加载 map 之前为 “heap-ness” 测试接受者。
1 | and obj, #TagMask, temp extract object’s tag |
1 | isHeapObj: continuation of “heap object” case |
在这个实现中,一个简单的类型测试消费了相当的代码空间和执行时间。幸运地是,我们总是可以通过预测加载映射(没有测试对象的标签)来提高这个代码。如果这个对象是一个立即数加载将会遇到一个“illegal address”的陷阱,因为内存地址必须是字对齐的。如果这样的陷阱发生,陷阱处理程序必须用合适的 map 填充目的寄存器(或者整数 map 或者 浮点 map)然后继续执行下一条指令。
随机映射加载显著地加速了类型测试;新的代码序列是:
1 | ld [obj + #MapOffset], temp speculatively load map |
当反复地测试相同的映射时,很有可能映射常量会被分配到一个寄存器里,进一步降低测试序列为三个指令:load,compare、和 branch。
当然,如果一个陷阱被获取(花费几千条指令)时类型测试时十分昂贵的,所以随机加载方案只是当陷阱很少发生时比较合理。因为这个原因,随机加载没有被用到前一代除了 SOAR 的其它系统中。SOAR 的陷阱处理程序比 Unix 的快很多(很少的周期数和上千条周期数)因为它的硬件和软件都是为快速陷阱设计的。不幸地是,如此快的陷阱处理在典型的工作站中不是有效的。因此,随机加载是冒险的因为当陷阱总是发生的时候性能会显著下降的。幸运地是,PICs 和类型反馈重编译保证陷阱较少的发生在我们的系统中。如果随机映射加载是 PIC 的一部分,我们将最多遇到一个陷阱因为 PIC 会在第一个陷阱(当然,新的 PIC 将会在加载 map 前首先测试标签)之后被当前场景扩展。如果,随机映射加载时已编译代码的一部分,将不太可能有陷阱因为已编译方法的前一个版本在它之前的上千次调用中没有遇到立即数。当一个加载总是导致重复的陷阱,相关的已编译方法会以类似于不常见陷阱的方式重编译。
总之,自适应重编译允许系统使用随机映射加载来加速类型测试。不像非自适应系统,SELF-93 系统在预测失败时不需要付出太大代价,因为它可以重编译一个投机经常失败的方法(变为非投机的测试)。
6.3.2 存储检测
分代垃圾回收需要保持从老年代的到年轻代的引用追踪因此年轻代可以垃圾回收而不会检查老年代中的每个对象[89,131]。潜在包含指向新对象指针的位置的集合总是被称为 remembered set [132]。在每个存储,如果存储创建了一个从老对象到新对象的引用,系统必须保证更新的位置被加入 remembered set 中。这个不变式的维护通常涉及到 write barrier 或者 store check。
对于一些存储,编译器可以静态的知道无需存储检查,例如,当存储一个整型或者存储一个老的常量(因为老的对象从不会在变成新的)。然而,在常见的场景中对于每个存储操作都必须执行存储检查。因为存储时频繁的,一个高效的写保障实现是必须的。SELF-91 的写屏障实现是基于 Wilson 的卡片标记方案[139]。在这个方案中,堆被分为 2^k 字大小(典型的,k = 5..7)的卡块,没个卡在分离的向量里有个关联的字节。一个存储检查只是简单的清理正在更新的位置对应的字节。在垃圾回收时间,收集器会扫描字节向量;每当它找到一个标记位,收集器会检查堆中相关卡片上的所有指针。
字节标记方案的优势是它的速度。在 SELF-91,存储检查除了实际的存储指令外只涉及 3 条 SPARC 指令:
1 | st [%obj + offset], %ptr store ptr into object’s field |
这个代码序列假设寄存器 byte_map 保存了字映射的已调整过的基础地址,即,byte_map_start_address - (first_heap_word / 2^k),因此在计算需要被清理的字节的索引时避免了一个额外的减法。
我们已经减少了写屏障的实现到每个检查存储只要两条额外的指令而不是前一代 SELF 系统的三条指令。我们新的写屏障是基于标准卡标记提升的通过放宽由卡片标记方案维护的不变量。标准卡标记维护的不变量是
1 | bit or byte i is marked <--> card i may contain a pointer from old to new |
我们方案宽松的不变量是
1 | bit or byte i is marked <--> cards i..i+l may contain a pointer from old to new |
此时 l 是一个小的常量(在我们当前的实现里是 1)。本质上,l 让存储检查在选择哪个字节来标记有了些余地 – 标记的字节最多离“正确”字节 l 字节远(在低地址的方向上)。宽松不变量允许我们忽略计算已更新字的确切地址:只要已更新字的偏移(即,从对象开头的距离)小于 l * 2^k,我们可以标记对象地址相关的字节而不是已更新域的字节。因此,通用的存储检查只有两条指令:
1 | st [%obj + offset], %ptr store ptr into object’s field |
通常,一(l == 1)的余量是足够覆盖基本所有的存储(除了存储内存元素的)。例如,在 SELF 系统中卡的大小是 128 字节因此所有存储任意前 30 个对象的域可以使用快速代码序列。包含数组的指针被认为是特殊的:数组元素赋值标记确定的赋值卡因为它可以任意远离数组的开始。
在一个可以决定对象边界的系统中,余量的限制可以完全的解除:除了扫描标记卡,收集器只要向前扫描知道它找到下一个对象头。同样,对于包含指针的数组必须被特殊对待且标记确定的赋值卡。然后,如果一个扫描卡没有包含对象头,或者从卡片开始的最后一个对象是指针数组,收集器不需要扫描超过当前卡片。
虽然存储检查的开销只是每个存储两条指令,它仍然可以代表垃圾回收总开销的一大部分。例如,在 SPARCstation-2 存储检查减少 Richards 8%的性能。详细的分析超出了本文的范围,推荐感兴趣的读者阅读 [72] 获得更多信息。
6.3.3 块切换
考虑下面的方法:
1 | foo = ( | localVar | globalVar: [ localVar: ‘hello’ ] ) |
在这个例子中,方法存储了一个块到全局的 globalVar。如果可能在 foo 返回后调用这个块,将会在 foo 的活动区里访问 localVar,因此活动区必须是堆分配来保证 localVar 仍然是存在的。一个块被调用在它的闭包方法已返回之后在 Lisp 语法中是为 non-LIFO 块或者 upward funarg 。
在当前的SELF实现中,所有的方法活动区都是栈分配的,因此块不会在它们的闭包函数返回之后执行。(这个限制当前是存在的因为在不降低调用的情况下难以实现全封闭。)为了删除(中断)non-LIFO 块调用,块在它们的闭包函数返回前被“切换”。每个块对象包含一个指向闭包范围的栈帧的指针(即,一个词法链接),然后简单地切换这个链接。大部分块被内联因此不需要切换因为没有块对象被曾经创建过。一些块总是被创建然后可以被用一条简单的存储指令切换。第三类块,memoized blocks,能或者不能创建取决于采取的执行路径。下面的伪代码为表达式 x do:[ foo ] 演示了一个场景:
1 | if (x is an integer) { |
当前,在返回包含上面表达式的方法之前,块需不需要被切换?上代 SELF 系统通过初始化块的位置为零和在执行切换存储前测试来解决了这个问题,结果式下面三条指令序列:
1 | cmp block, #0 was the block created? |
为了消除比较和跳转指令,我们用 “dummy” 块对象初始化一个块的位置;所有的保存还没创建块的位置当前会指向这个 dummy 块而不是包含 0 了。作为结果,我们会用单条存储指令无条件切换块,不管它是否创建了。如果块没有创建,存储将会复写 dummy 块的词法链接:
1 | st #0, [block + #linkOffset] zap the block (either real or dummy) |
降低块切换从三条指令到一条指令的缺点是需要一个额外的指令来初始化块的位置因为 SPARC (和其它 RISC 架构)的 32 位常量需要两条指令。但是,全部开销(初始化 + 切换)仍然比较低,特别是当跳转代价昂贵的情况下。此外,如果几个块需要被初始化,dummy 块的地址通常被分配为寄存器,降低除了第一个块以外的所有块的初始化过程回一条指令。因此,SELF-93 的块切换方式比前一代实现显著地提高了。
6.4 缺失
在描述当前编译器的实现之后,还需要再描述未实现的部分。当前,编译器有几个缺点对代码质量产生不利影响;下面说明最重要的一个。当然,这边有许多的优化会提高性能,例如通用的子表达式消除或者循环不变量代码移动。但是,我们会在这个讨论中忽略这些优化因为它们需要全局的数据流分析因此会大大降低编译器性能。因此,我们限制自己的缺点在可以移除或者至少减少对编译时间的影响的范围里。(8.6 节 估算这些缺点的潜在性能影响。)
6.4.1 窥孔优化
通常低效的代码可以被简单的窥孔优化器移除。低效的例子如下:
- 未填充的延迟槽。 延迟槽只能填充固定的代码序列如方法导言;所有其它延迟槽均未填充。
- 跳转链。代码总是包含一些跳转到其它跳转指令(无条件的)的代码,其可以替换为直接跳转到最后的目标。
- 额外加载。值可能会重复地从内存中加载,即使在相同的基础块里。如果要加载的值式向上访问的值就会特别低效,因为整个加载的序列(伴随着词法链)会在这些场景下重复。
- 加载暂停。编译器没有尝试避免加载暂停。在 SPARCstation-2 上,当加载结果被用到下一条指令时,加载需要一个额外的周期。这个额外的周期可以通过在加载和使用加载结果的指令间插入一个不相关指令来避免。在超标量 SPARCstation-10 上,没有加载暂停发生,但在加载之后的指令开启了一个新的指令组(即,没有和加载在相同周期执行),导致相似的性能损失。
6.4.2 重复类型测试
因为编译器没有执行类型分析,一个值可能会被重复测试它的类型即使所有测试包括第一次都是没必要的。例如,考虑下面的方法:
1 | foo: i = (| j. k | |
假设 i 是一个整数然后编译器使用罕见的跳转,编译器会产生下面的代码:
1 | ... |
第二个类型测是冗余的因为 i 在这个点上被确保为一个整型;如果它不是,执行将会让已编译代码留在第一个异常陷阱里。编译器可以异常第二个测试而不需要任何额外的数据流分析因为 i 是一个参数因此不会被赋值(SELF 中参数是只读的)。
6.4.3 简单的寄存器分配
当前的寄存器分配器,除了快速,无法和高质量的寄存器分配器竞争,特别是它的寄存器压力比较高。因为它没有使用干涉图,寄存器没有有效的合并,导致额外的寄存器移动。此外,因为寄存器的生命周期是源码级的术语表示(这粗糙了些),寄存器可能会在一个寄存器块里看起来繁忙但可能并不需要。幸运地是,SPARC 寄存器窗口创建了一个相对的富寄存器环境,因此这个不足通常不会导致许多额外的内存访问。
6.5 总结
SELF-93 编译器面向快速产生好的代码。三个技术帮助达成这个目标。类型反馈 允许编译器内联更多的发送而不需要大量的分析;类型信息可以方便地从运行时系统提取只要较小的开销。基于代码的内联启发式规则 允许编译器做更好的内联决策通过检查内联候选已经存在的编译版本。非通用陷阱 可以激进的用于降低代码大小和提高代码质量通过排除未知的场景;自适应重编译允许编译器从一些被证明过于激进的假设上回退。
编译器后端相当传统,使用高级中级代码格式而不是一个类 RTL 格式,从而保持较高的编译速度。通过利用许多实体的单一赋值属性,编译器可以执行一些全局优化而不需要计算全部的数据流信息。运行时系统中几个创新的解决方案进一步提高代码质量:类型测试消除标签检查开销通过使用随机映射加载,通用垃圾回收的存储检查降低到每个堆存储两条指令,还有块(闭包)高效地失效。
下面两个章节将会评估和分析生成代码的质量,然后第九章会评估它的编译速度来表明它适合一个交互编程环境。
7. 性能评估
这章通过测量一套包含三个小的和六个巨大的 SELF 程序(见表 7-1)。 除了 Richards 测试集,所有的测试程序都是编写的真实用例并不是特意的为测试用途写的。这个应用是不同的程序员写的,表现为一系列编程风格;一个应用(Mango)是通过一个解析生成器产生的。
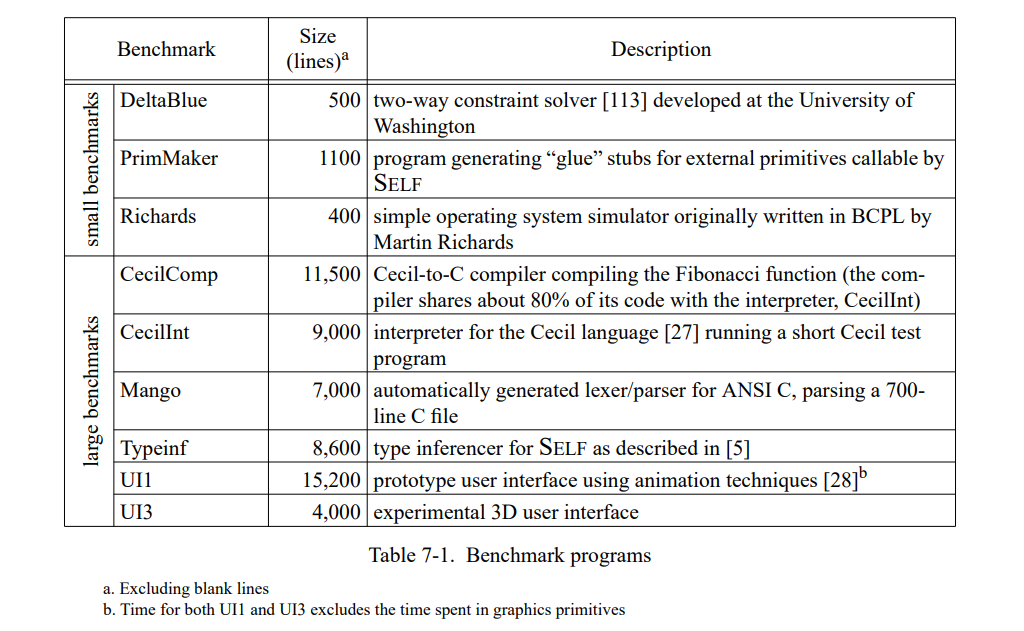
为了评估类型反馈和自适应重编译的收益,我们比较三个不同 SELF 实现(Table 7-2)。SELF-91 是上一代实现使用了迭代类型分析[21];这个系统没有使用重编译,也没有使用类型反馈。SELF-93 是前面章节描述的当前系统,使用了动态重编译和类型反馈。最后,SELF-93-nofeedback 是 SELF-93 关闭了重编译和类型反馈的版本。这不是一个正常使用的版本,但因为它优化了所有的方法却没有使用类型反馈,我们可以把它和 SELF-93比较用来估算类型反馈的影响。此外,类型分析(SELF-91也使用了)的影响可以通过比较 SELF-91 和 SELF-93-nofeedback 来估算。
为了评估 SELF 系统的绝对性能,我们也把它和 Smalltalk 及 C++ 进行比较。Smalltalk 时一个动态类型语言,理念上与 SELF 极其相似。我们使用的实现,ParcPlace Smalltalk-80,是广泛使用的商业实现且被当作是当今最快速的可用的 Smalltalk 实现。为了提供另一方面的参考,我们也比较了 SELF-93 和最广泛使用的静态类型面向对象语言,C++。我们使用 GNU C++ 编译器[56],因为它基本是最广泛使用的 C++ 实现能产生很好的代码,以及 Sun CC, 基于将 C++ 预处理为 C 的典型 C++ 实现。(我们比较这两种编译器因为两个有显著的性能不同点。)表 7-3 列出了所有系统的主要实现特征。
7.1 方法
SELF 程序的执行时间反应了(重)优化代码的性能,即,它们不包含编译时间。对于重编译系统,程序会一直运行直到性能看起来是稳定的(在几次运行中没有重编译发生),下次运行不在调用编译,就会被使用。SELF-91 和 SELF-93-nofeedback 不使用动态重编译,所以我们可以使用第二次运行的结果作为测量数据。
除非另有说明,我们在总结性能比较的时候会遵循惯例使用几何平均。例如,“系统 A 两倍快于系统 B” 意味着测试集执行时间的几何平均值的比值是(B 花费的时间除以 A 的)2。
为了准确地测量时间,我们写了一个 SPARC 模拟器基于 spa[76] 和 shade[34] 追踪工具以及 dinero 缓存模拟器[66]。模拟器建模了 SPARC 架构的 Cypress CY7C601 实现运行在 40 MHz,即,SPARCstation-2(SS-2)工作站使用的芯片。同时也精确地建模了 SS-2 的内存系统,伴有着不同缓存组织的异常。我们不使用原来的 SS-2 的缓存配置因为它在缓存失效率上会遭受大幅的变化,由于代码和数据位置不同(我们已经观察到变化会导致总执行时间高达 15% 的波动)。SELF 中会更频繁的出现缓存失效的情况因为已编译代码和数据是动态分配的,系统小的改变都会导致代码和数据的相关对齐,然后导致冲突失效数量的改变。因为我们测量的系统没有专门为了更好的缓存进行优化,这些变化可以认为是随机的,它们的存在让精确评估两个系统或者相同系统的两个版本变得比较困难。
为了替换 SS-2 中的统一直接映射 64K 缓存,我们模拟了一个 32K 两路关联指令缓存和一个 32K 两路关联数据缓存,用了写分配子块放置。同时,我们预置了一个足够大的写缓存可以接受所有的写。作为原始的 SS-2 工作站,缓存行是 32 字节长度的,缓存失败的惩罚是 26 个周期。伴随着缓存配置的改变,变化会变得足够小(占执行时间的 2%)因为缓存时两路组相连(因此降低了冲突失败的数量)且拆分成了 I- 和 D-caches (因此在指令和数据间是没有缓存冲突的)。因为模拟的缓存配置降低了缓存失败的变化范围(即,冲突失败的数量),它的失败大部分是容量失败。因此,大程序通常仍会发生更多的缓存失败且运行得更慢,就像它们在真实的机器上。换句话说,这个模拟缓存配置仅仅只是降低了我们数据中的“噪音”,仍然真实地建模了程序缓存的行为。因为这些降低的噪音,我们可以更准确地评估编译器优化的性能影响。
我们验证自己的模拟器通过比较真正的执行时间,这个时间是在一台空置的 SPARCstations-2 工作站以单用户模式在模拟时间跑出来的。当模拟真实的 SPARCstation-2 缓存组织,结果非常吻合,全用例的不同小于 15%;模拟时间通常某些方面会好于测量时间,可能是因为模拟器没有建模好 CPU 和缓存被操作系统干扰的部分。使用关联缓存组织的模拟时间在真实执行时间的 70-90% 之间,取决于测试集和特定的测量运行(重调用直接映射缓存显示了缓存有效性宽的变化)。我们将这些不同归因于更好的缓存组织然后忽视操作系统的开销。
7.2 类型分析不会提高面向对象程序的性能
首先,我们通过比较 SELF-93-nofeedback 和最快的前一代实现,SELF-91 来测量新编译器的基础性能。图 7-1 显示结果()只是快了一点()尽管它使用了类型分析,更昂贵的类型预测,和更激进的后端。一个生成代码的非正式分析让我们相信 SELF-91 速度高于 SELF-93-nofeedback 的部分来自于编译器后端的差异。例如,SELF-91 会把除 2 编译为一个 Richards 内部循环的移位,而 SELF-93-nofeedback 不会做这个优化。通常,SELF-91 产生的代码基本显著地不执行没必要的寄存器分配。
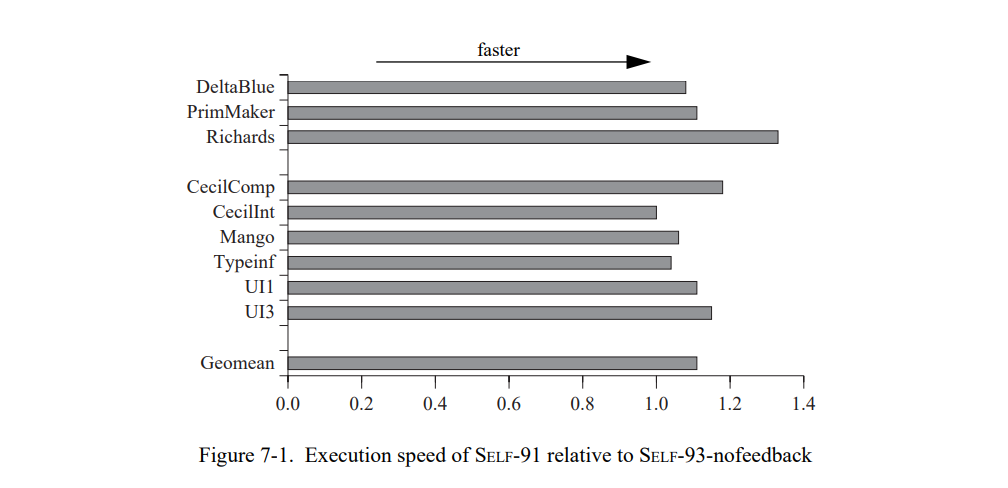
如果大部分的性能差距可以通过 SELF-91 的超级后端解释,是不是就意味着类型分析没有性能影响?图 7-2 确认了我们测试集里的程序似乎没有从类型分析中受益:平均上,SELF- 91 没有比 SELF-93-nofeedback 内联更多的发送。通常,类型分析不能推断非内联消息发送的返回值类型,以及非内联发送的参数类型,或者可分配槽类型(即,实例变量)。因为发送到这些值是非常频繁的,消息发送的大部分都不能从类型分析中受益。对于我们测试集中的面向对象程序,类型分析的好处是非常小的。(7.5.4 节将会更细节地讨论类型分析。)
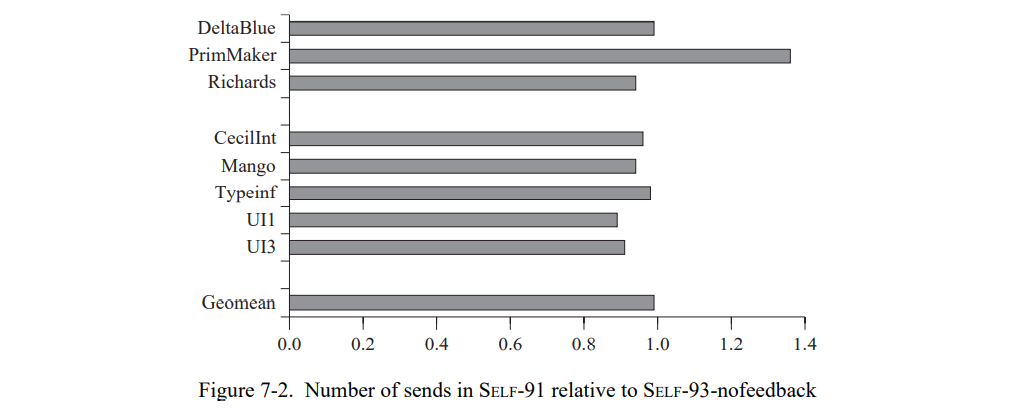
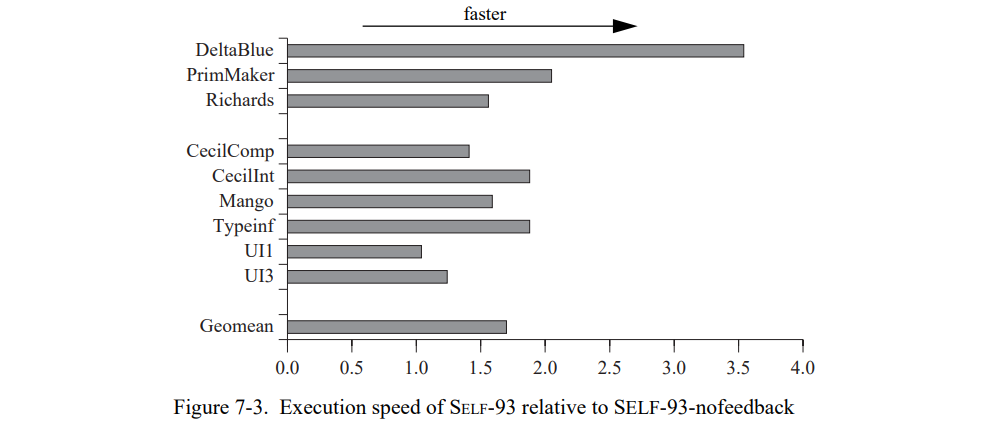
7.3 类型反馈工作
为了评估类型反馈的性能影响,我们比较 SELF-93 和 SELF-93-nofeedback。因为 SELF-93-nofeedback 比 SELF-91 具有竞争力,我们有理由确定任何类型反馈获得的加速不是人为的削弱 SELF-93-nofeedback 系统,而是一个真正的性能提升。图 7-3 显示我们测量的结果(附录 A 中的表 A-3 包含了详细的数据)。类型反馈显著地提高了生成代码的质量,从而比 SELF-93-nofeedback 有 1.7 倍的提升(几何平均),甚至 SELF-93-nofeedback 总是优化所有的代码而 SELF-93 只是局部代码被优化。重编译系统在利用 PICs 提供的类型反馈来生成更好的代码和找到应用的时间关键路径上似乎特别成功。
类型反馈同时也大幅度降低了测试集程序执行调用的数量(图 7-4)。平均上,类型反馈降低了 3.6 倍调用频次。显然地,类型反馈暴露了许多新的内联机会,这是 SELF-93-nofeedback 没有开发的,因为它缺少接收者类型信息。例如,在 SELF-93-nofeedback 中 Richards 大约一半的非内联发送是访问方法,其只是返回(或者设置)一个实例变量的值[70]。所有的这些发送在 SELF-93 里都被内联。
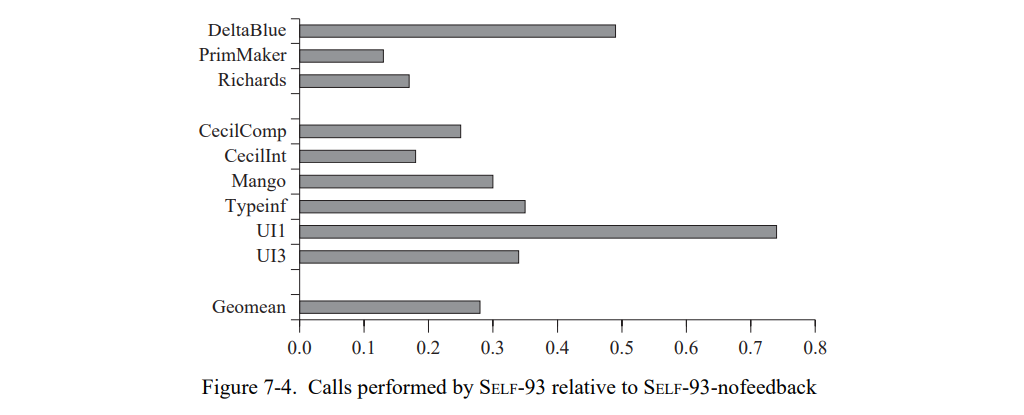
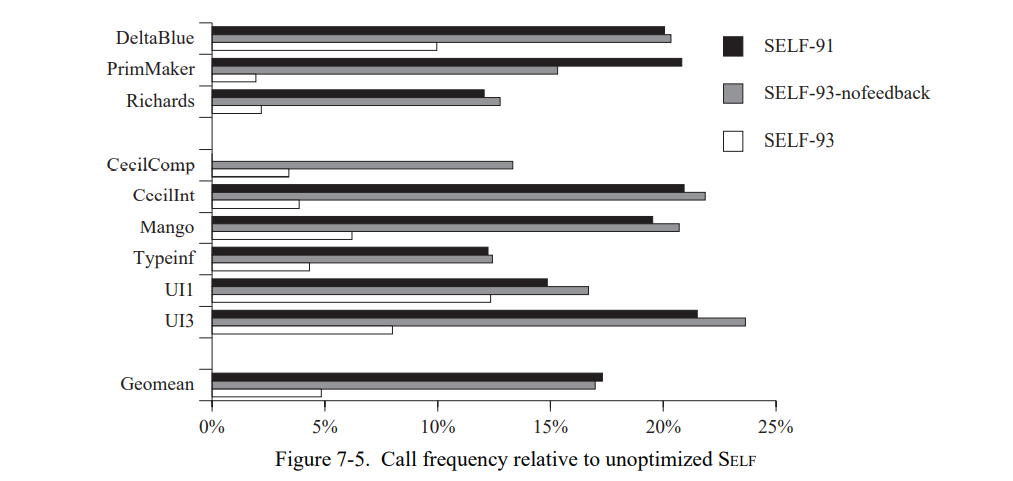
查看完全未优化 SELF 调用的数量也是很有趣的。在未优化的SELF上,每条消息发送被实现为动态分配调用,除了访问接收者中的实例变量;未优化的程序运行许多次会慢于 SELF-91 和 SELF-93(见第四章)。SELF-93 比起未优化的 SELF (图 7-5 )少执行了 5% 的调用。作为对比,SELF-91 和 SELF-93-nofeedback 保留了原始的 10%-25% 的调用。
可以预测的是,消除的调用与加速是有一些相关性的:通常,内联一个调用可以提升性能。但是,这个相关性相当的弱(见图 7-6)。如附录 A 中的表 A-4 所示,
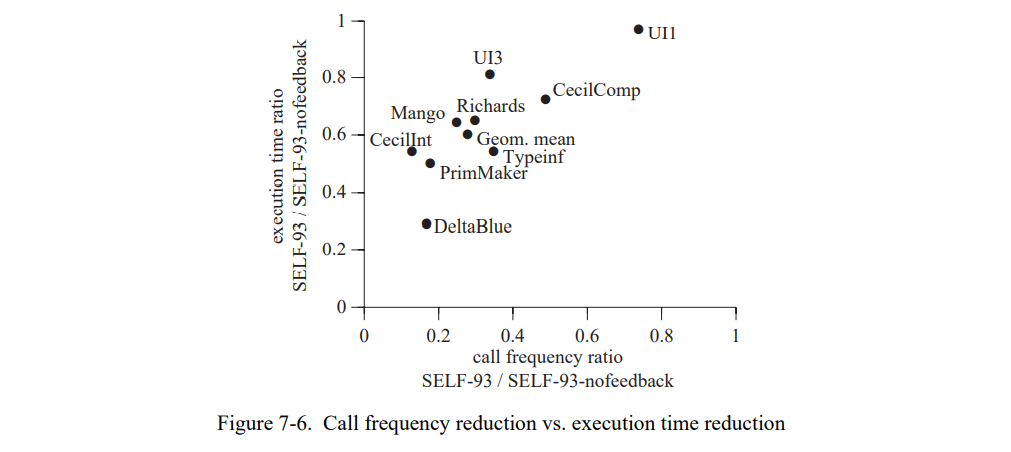
每个调用节省的时间(平均每个测试)有十倍的变化,每个调用从 0.5 到 5 的范围(或者每个可删除调用大约有 10 到 100 到可消除指令)。因为每个测试的平均,它们可能低估了每个内联调用的真正差异:一些内联决策可能导致负受益(如,因为它们增加了太多的寄存器压力,导致太多的溢出周期,比消除调用固有开销的减少的周期还多),然后也有导致更高收益(即,因为它们允许昂贵的原语来常量折叠)。但是,激进的内联通常导致显著地增加 SELF 程序的性能。这种效果与其它语言的研究形成鲜明的对比(如 C 或者 Fortran),这些语言内联被认为只有少量的收益,如果有的话[29,36,39,62,74]。我们将这些差异归因于 SELF 和传统语言的一系列显著差异:
- 在 SELF 中,相对于 C 或者 fortran 过程(方法)平均而言都比较小,因为每个操作(包括非常简单的,如整型算术和数组访问)都与消息发送相关。同时,面向对象的编程语言鼓励代码重构为分离出相关抽象之间的共性,这也会导致更小的代码。
- C 和 Fortran 程序员在写程序时会有更多的性能意识,基于 “调用时昂贵的”的假设。本质上,就是程序员一开始就手动内联了非常小的函数(一行或两行)。
- SELF 使用闭包来实现控制结构和用户自定义的迭代器,因此内联一个调用可以使得编译器免于创建一个闭包,因此节约了至少 30 条指令。因此,内联一个简单的调用会默认导致显著地提升即使没有源码级别的冗余(如通用子表达式),这可以被认为是内联导致的结果。有趣地是,现代计算机架构为传统语言创造了相似的情况。例如,如果循环在提高了数据依赖信息可以并行化[62],内联一个调用可能会显著地加速一个 Fortran 程序。这个加速不是来自于被内联代码执行时间的减少而是来自调用者出现了更多的优化。
图 7-7 表明测试集间的性能提升区别比较大。x 轴表示类型反馈(即,SELF-93-nofeedback 和 SELF-93 的不同)节省的总执行时间。方框总结了每个类别的重要性,即,对于整体加速的贡献。取决于不同的测试集,减少调用固有开销将节省总执行时间开销的 6% 到 63%,中位数是 13% ,算术平均是 25%(几何平均是:18%)。降低的类型测试的数量的贡献几乎和加速一样多,其的中位数是 17% 而平均值是 19%,闭包创建减少的数量也是如此。
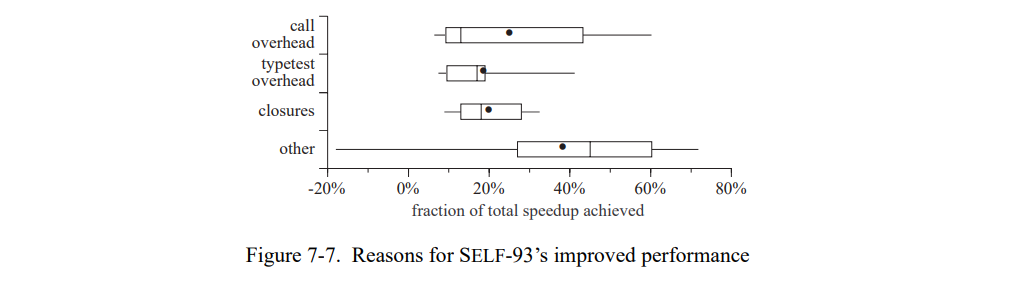
其它的效果(如随着编译方法大小的增加效果越好)对于加速做了更大的贡献(中位数 45% ,平均数 38%)但是有更大的波动。对于一个测试集,贡献实际上是负的,即,减缓执行。减缓的一个可能的原因是劣化了寄存器分配(因为增加了寄存器分配),或者更高的指令缓存失效。所有的这些测量都包括了缓存的效果。
总之,图 7-7 中的测量结果显示,使用类型反馈获得的性能提升并不总是于减少的调用正相关。在大部分的测试集中,调用开销以外的因素更能节省执行时间。基于类型反馈的内联是正在使能的优化,它使得其它优化效果更好,因此,除了从消除调用中获得的直接收益也创建了间接的性能收益。
7.3.1 与其它系统比较
为了提供一些关于 SELF 绝对性能的上下文,我们测量了用 C++ 和 Smalltalk 编写的 Deltablue 和 Richards 版本。(其它的测试集在 C 和 Smalltalk 是不可用的。)我们测量了两个 C++ 版本。第一个版本手动优化,通过只在必要的时候声明函数为“virtual”。在第二个版本中,所有的函数都被声明为虚函数,就行它们在 Smalltalk 和 SELF 隐式定义的一样。但这不是说所有的函数都是动态分分发的;至少当接收者类型是已知的时候 GNU 编译器会静态地绑定调用。
因为不可能在模拟器中运行 Smalltalk,我们只能获得过程时间测量。就像 7.1 节讨论的,我们估算模拟时间大约是 10-25% 低于经过时间,因为模拟不包含 OS 的固有开销且模拟有个更好的缓存组织。为了比较 SELF 和 C,我们估算 Smalltalk的时间是经过时间的 75%。
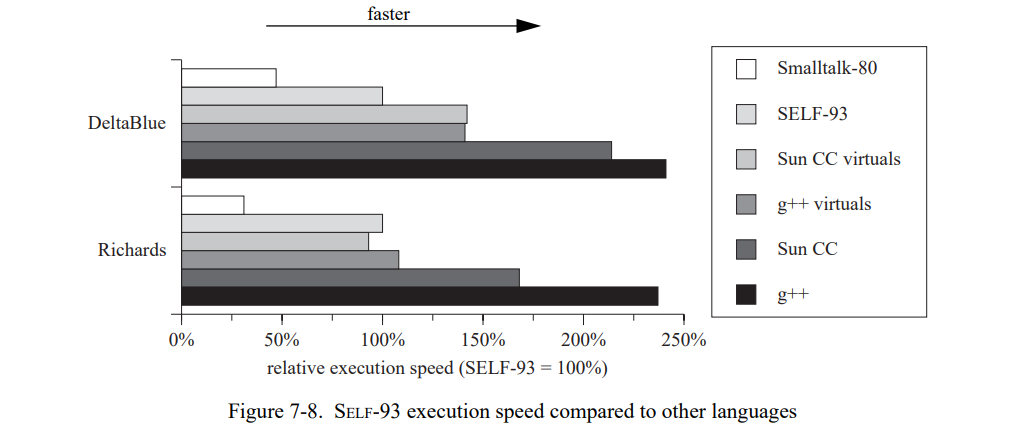
对于这些测试集,SELF-93 比 ParcPlace Smalltalk 运行快两到三倍,后者被认为是最快的商用版本 Smalltalk 系统(见图 7-8),即使 SELF 语言更纯粹从而更难以有效的实现[21]。因此,SELF-93 只是比优化过的 C++ 慢 1.7 到 2.4 倍,尽管本质上是不同的语言模型,且事实上 SELF-93 的后端确实劣于 C++ 编译器。如果所有的函数都近似像 SELF 的语义一样被标记为 virtual,C++ 的速度优势会显著地下降到 SELF-93 的 0.9 到 1.4 倍。虽然 C++ 编译器比起 SELF-93 潜在的能执行更多的经典优化,在这些场景下也无法产生更高效的代码,因为它们无法优化动态分发的调用。当然,C++ 程序仍然不支持泛型运算,算术溢出检查,数组边界检查,以及用户定义的控制结构。
总之,SELF-93 编译器可以将 SELF 的性能带到一个可以与其它面向对象语言比较的高度,且不需要对 SELF 的纯语义妥协。
7.3.2 不同的输入
一个可能的质疑是,上面 SELF-93 的结果是使用相同输入测量的,这是可以”训练的“[137]。直观上来说,比起对传统系统的影响,对SELF的影响更小。首先,反馈主要的收益是类型信息;因此程序的”类型构像“比起时间构像更重要。比起时间构像,类型更可能在各种输入见保持不变。(Garrett 等[57] 最近的研究为 Cecil 和 C++ 验证了这个假设。)第二,系统可以动态地自适应时间里的修改,重优化新的”热点“的类型构像,且重编译来包含新的类型。
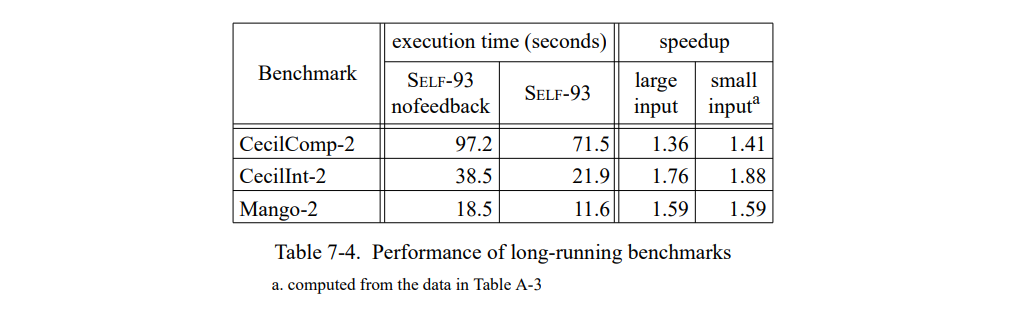
另一个潜在的异议是,到目前为止已有的性能测试的测试运行都太短了。(上面测试集相对比较短便于简单模拟。)为了保证小的输入不会扭曲性能数据,我们测量了三组大输入的测试集。表 7-4 表明大输入的加速与小输入的加速是相似的。
7.4 性能的稳定性
除了有高性能,类型反馈也有另一个优势:比起使用源码静态分析的系统,它提供了更稳定的性能。在小的源码修改之后,基于单独静态分析的系统可能会丢失关键的信息,因此使得一个关键的优化失效和性能缺失。例如,假设一个程序内循环添加一个向量的元素:
1 | aVector do: [ | :elem | sum: sum + elem ] |
如果源码的改变导致了编译器无法获得 aVector 的准确类型,循环就不能内联从而性能会显著地下降。而使用了类型反馈,循环可以任意的内联(使用来自运行时系统的类型信息),这个的固有开销是要加上一个额外的类型测试。类型反馈的动态特性能比静态分析有更稳定的性能。
7.4.1 类型分析表现的不稳定性
为了测量静态类型信息减少对于性能的影响,我们从 Stanford 测试套件中取出九个小的整型程序,用来评估 SELF-91 编译器[21]。这些小的测试集的内循环典型的只有一到五行,大部分只执行整型运算和数组访问。就如最初所写的,这些测试集大部分为编译器提供了许多重要值的静态类型信息。例如,数组冒泡排序的测试集是一个常量槽,因此编译器可以内联所有的数组访问(at: 和 at:Put:sends)。同时,有一个常量数组让编译器能确定数组的大小,因此允许编译器来推断循环下标的加法计算不会溢出。为了建模”正常“使用场景,我们创建了每个测试集的第二个版本,消除静态类型信息的一些来源,通常是将常量槽改为分配槽。所有的改变都是比较小的,不会影响到测试集的算法属性。例如,bubble 测试集的唯一修改是将被排序的数组从常量槽改为可分配槽。图 7-9 显示了 SELF-91 在测试集上的性能(显示的性能是相关于用全优化的 GNU C 编译器编译的等价 C 的性能)。
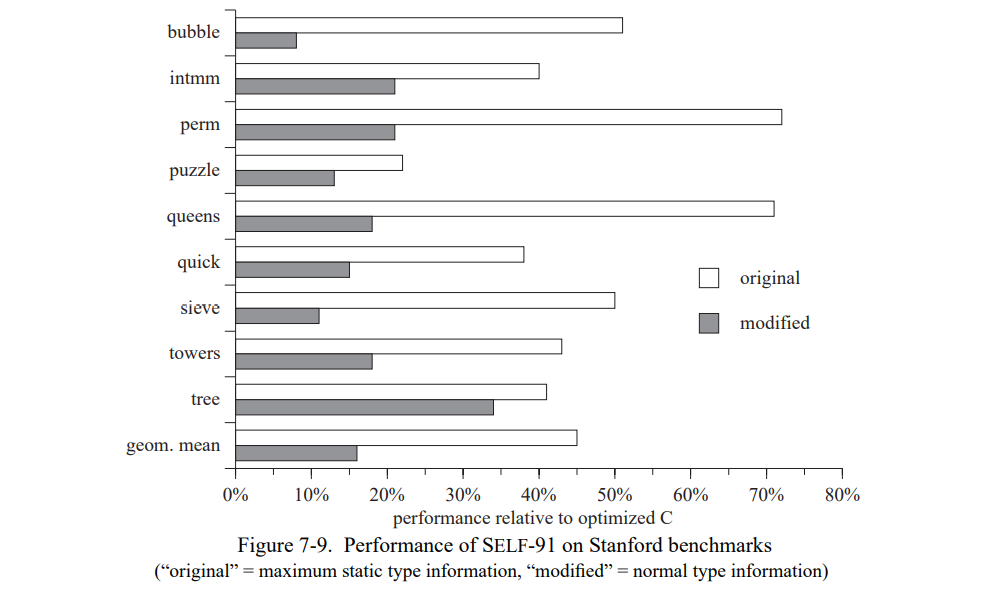
在 SELF-91 有完整的类型信息时,它会执行的非常好,能达到优化的 C 的速度的 45%。当缺少类型信息时 SELF-91 的性能会陡然下降;例如,bubble 变慢超过了六倍。平均而言,在 SELF-91 中修改过的测试集变慢了 2.8 倍。在失去了静态类型信息的重要来源,编译器不再能够很好地优化测试集。
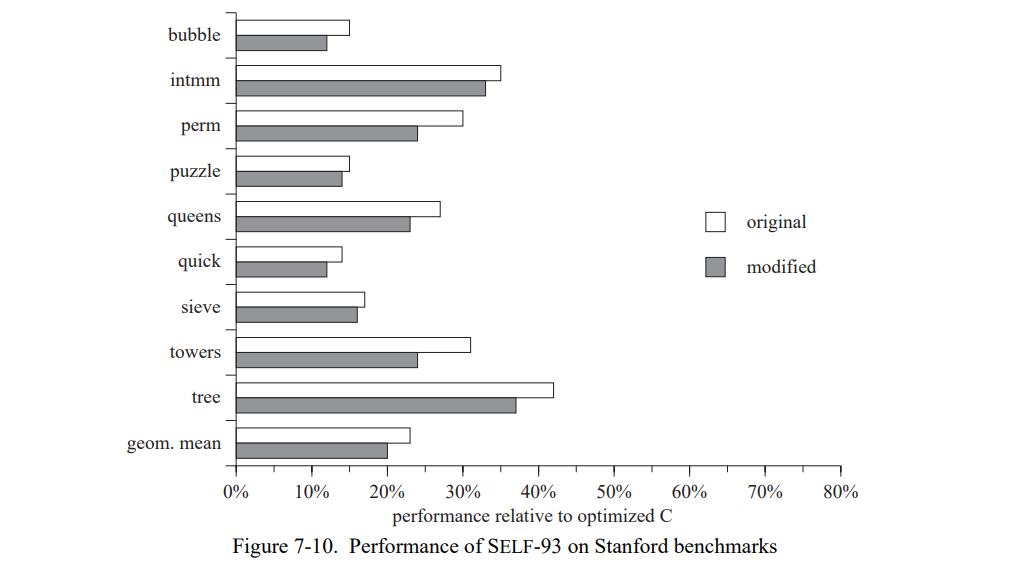
SELF-93 的性能更稳定,平均只下降了 16%(图 7-10)。即使一个对象的类型静态不可知,类型反馈也可以提供它的类型,通过添加一个类型测试的形式附带一个小的运行时开销。类型反馈让SELF的性能更少的依赖于静态类型信息,因此当这些信息缺少时性能变化更小。
7.4.2 静态类型预测失败
在没有类型反馈的系统中,静态类型预测存在着相似的问题。许多系统(如,大部分 Smalltalk-80 和 SELF 实现)静态预测某个消息的类型。例如,ifTrue 的接收者:被预测为 true 或 false 的对象,而 + 的接受者被预测为整型[128, 58, 44, 130]。静态类型预测会获得明显的性能优势,但它会导致不稳定的性能。首先,特化的消息执行得比语义等价的使用非特化选择器的代码快得多。第二,如果预测失败,消息预测的开销会显著地高于正常的发送。例如,就像 6.1.4 节里讨论的,SELF-91 在一个类型预测失败时,不得不落入一个明显没有优化的代码。
7.4.2.1 非预测消息非常的慢
第一个例子来自于 Smatalk 世界,一个 Smalltalk 程序员在 comp.lang.smalltalk 新闻组里指出,下面的两个代码序列有着完全不同的性能,即使它们执行着相同数量的工作(在源码级别上):
1 | “nil1:” x isNil ifTrue: [ 1 ] ifFalse: [ 2 ] |
程序员对于这个情况感到困惑,第一个表达式在他的 Smalltalk 系统上运行几乎十倍于第二个表达式,即使它调用了两个发送(isNil 和 ifTrue:ifFalse)而另一个只有一个。这个性能的变化是因为 Smalltalk 优化了 ifTrue:ifFalse 消息发送,通过类型预测接受者,然后硬编码控制结构(换句话说,ifTrue:ifFalse 消息的源码被忽略了)。因此,Smalltalk 系统不只是避免了实际的发送,同时避免了为两个参数块创建实际的块对象。因为 ifNil:ifNotNil: 没有得到这种特殊地对待,它的执行调用了实际的数据发送和两个参数块的创建,因此运行得更慢。Smalltalk 得一些消息得特殊场景导致了不稳定得性能。
前一代的 SELF 实现也有相似的问题,因为它们也只类型预测了 ifTrue: 而没有预测 ifNil:。我们将这个例子翻译为 SELF,然后每个表达式运行 100,000 次(表 7-5)。
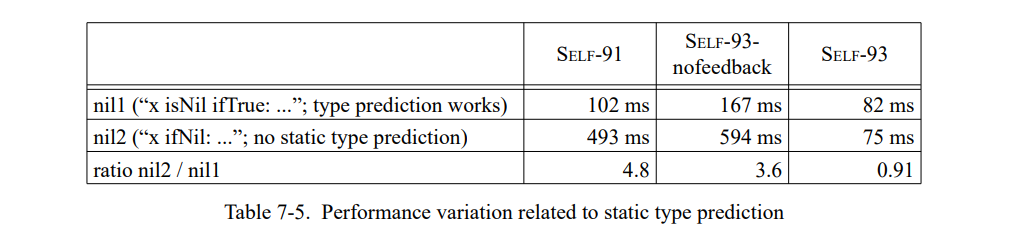
在 nil 上,SELF -93 比 SELF-91 稍微快了点,因为类型反馈使得它可以内联 isNil 发送;SELF-93-nofeedback 相当的慢,因为有一个相对低质量的编译器后端。但是,所有的系统都做得比较好因为它们正确地预测了 ifTrue:。在 nil2 上,使用静态类型预测的编译器遇到了同 Smalltalk 系统完全相同的问题,因此产生了明显较慢的代码;例如,SELF-91 几乎是慢了 5 倍。相比之下,因为类型反馈预测了 ifNil:IfNotNil: 消息的接收者,SELF-93 为 nil1 生成了本质上相同的代码。因为类型反馈可以预测任意的消息发送,而不只是一些简单的特定场景,能提供更稳定的性能。
7.4.2.2 错误预测是消耗
第二个例子显示了 SELF 中消息发送被错误预测的影响。这个例子使用表达式 p1 + p2 和 p1 add: p2 来加两个点。两个表达式计算出完全相同的结果。在第一个场景中,静态类型预测会预测 p1 为一个整型,因为它是 a+ 消息的接受者;在第二个场景中,不会发生这样的错误预测因为 add: 不是一个类型预测消息名。Table 7-5 显示运行每个表达式 100,000 次的结果。
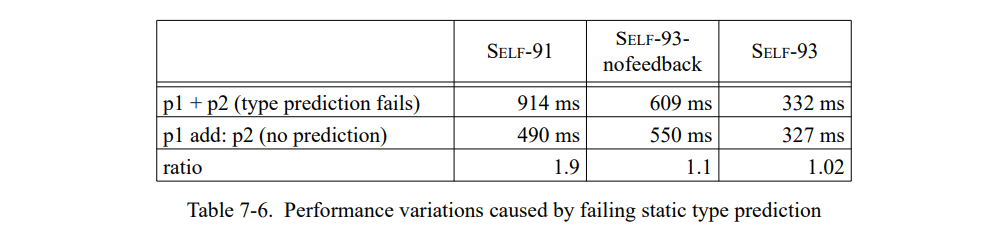
既不使用反馈而不使用重编译,SELF-91 变现出很大的变化,大约是 1.9 倍。SELF-93-nofeedback 预测一个整型接收者(像 SELF-91)但是在遇到一个特定陷阱时(见 6.1.4节)通过重编译方法退出错误的预测。在遇到特定场景后重编译降低错误预测的惩罚到 10%。因此,在错误预测的场景 SELF-93-nofeedback 运行得比 SELF-91 快;但是,缺少类型反馈,编译器不能内联 add: 发送,因此,代码仍然显著地慢于 SELF-93。最后,SELF-93 产生的代码在场景和显示里都几乎没有性能变化。SELF-93 从不会预测为一个整型接受者,因为来自未优化代码的类型反馈信息表明正确的接受者类型是 Point(重调用未优化的编译器执行一个发送即使是为了 +)。故,类型反馈和重编译有助于降低性能变化。
类型反馈提供更稳定的性能,因为它允许系统动态地适应于程序的实际类型使用。没有类型反馈的系统便显出更高的性能变化,因为它们无法应付静态类型信息缺失。这样的系统不得不依赖于静态启发式来加速通用的发送,但是在一个新的频繁使用的消息出现或者启发式失败的时候不能自适应。
7.4.2.3 在高级语言的性能变化
不稳定或者非预期的性能总是经常被引用为反对带有“昂贵”操作的高级语言的论据,这些开销无法精确地被程序员预测。例如,Hoare[68] 如下提出的:
1 | “唯一被普遍成功优化的语言是 Fortran,它就是专门为此设计的。但是即使在 Fortran 中,优化也有严重的劣势:[...]已优化程序里一个小的改变可能会非预期地关掉优化导致非预期和不可接受的效率损失。[...] |
我们相信这些年来这个论据已经失去大部分的力量。伴随着高速 RISC 处理器和缓存内存的来临,RAM 不在是 “随机访问”,因此访问一个数组元素等基础操作也有比较大的成本差异,即使在 Fortran 等相对低级别的语言里也是如此。例如,SPEC89 测试集套件里的一部分 matrix300 测试集(用 Fortran 写的)可以通过一系列的循环转化来提高缓存性能从而加速一个数量级。对于缺少机器架构知识的程序员而言,转换后的程序看起来越复杂,效率越低,而不是本质上更快。这就是任何的编程语言内存访问操作都会有显著地性能变化,而这从源码级别上是无法解释的。
7.5 详细性能分析
我们会更详细地分析固有开销源。首先,我们查找类型测试的固有开销。已优化的程序花费了多少时间在测试接受者性能,类型反馈如何影响这个固有开销。
7.5.1 类型反馈消除类型测试
类型反馈使用类型测试序列内联了发送,根据接受者类型它会从几个内联的代码序列选择一个。也就是用类型反馈替代了一个类型测试分派(在一个 PIC 或者方法导言中)用一行类型测试。例如,假设 print 是发送给 T1 和 T2 的对象类型:
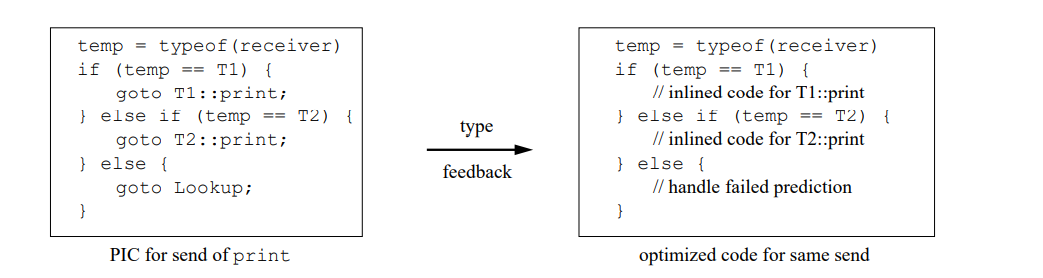
第一印象是,对于每个内联的发送,类型反馈替换每个分发测试都是一个确定的内联测试。因此,会认为在应用类型反馈优化前后程序执行的类型测试是相同的。然而,图 7-11 表明情况不是这样的:带有类型反馈编译的程序执行更少的类型测试。对于每个测试集,图中显示了相对于 SELF-93-nofeedback 的分配和内联类型测试的数量(上限是 SELF-93-nofeedback,下限是 SELF-93。)
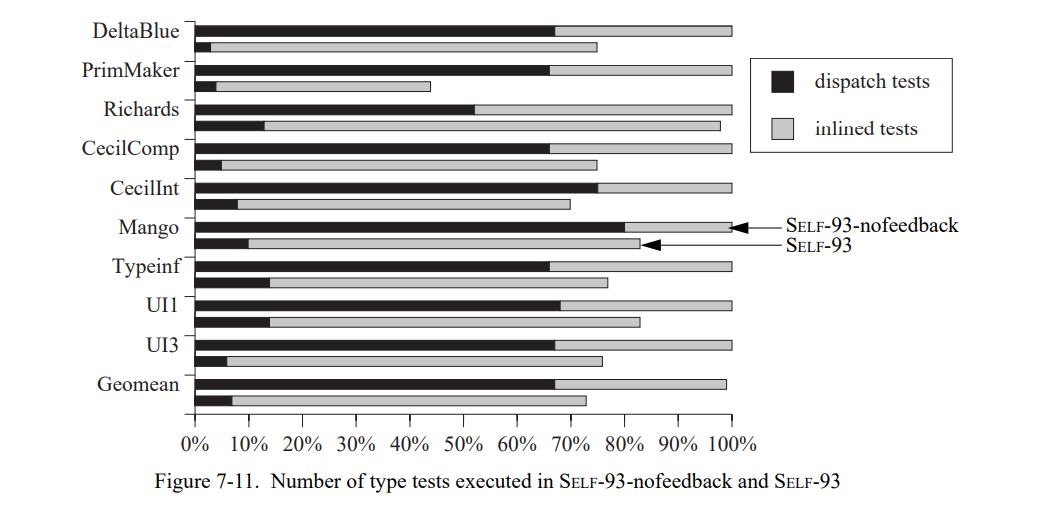
在所有的测试集中,SELF-93 执行比较少的类型测试;平均而言,只有原始测试的 73%。显然,一个简单的设想大概是是类型反馈的效果是不完整的。但是,类型反馈确实用内联测试替换了分发测试:然而分发测试的数量超过了内联测试,在 SELF-93-nofeedback 中大概是 2.1 :1 ,反之 SELF-93 中的比率是 1:10。
对于这个有点意外的惊喜结果的原因是内联一个调用(使用类型测试)可能会导致额外的类型信息,从而允许其它的发送被内联而不用任何类型测试。例如,如果一个内联调用的一个参数的类型是已知的,所有发送到这个参数的都可以被内联而不用测试。(这是一个常见的场景因为控制结构的参数如迭代器通常是块常量,即,常量。)在非内联的场景中,这些发送需要一个类型测试,因为参数的类型是未知的。因此,内联发送可以节省类型测试。
类似地,在一些情况下编译器可能会为另一个发送到相同值使用类型测试的结果,即使它没有执行通用的类型分析。具体来说,假设 x 是一个非赋值槽(即,一个参数)被类型反馈预测为一个类型 T,则编译器会决定“不是 T”的场景是不可能的。然后,语句序列“x foo. x bar”(发送 foo 到 x,然后发送 bar 到 x)会被转化为下面的代码:
1 | “x is T or unknown” |
因为第一个类型测试验证了 x 的类型,如果不是 T 会进入陷阱,在方法的剩余部分 x 就被当成类型 T,发送到它的子序列就可以被内联而不用任何的类型测试。
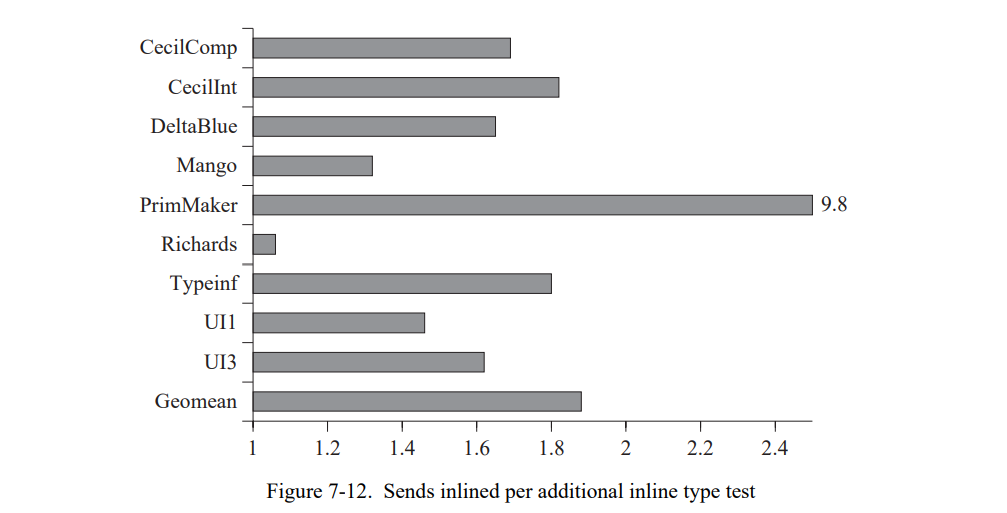
我们通过除以发送的数量来衡量这种影响的程度,这些发送通过额外的内联类型测试执行(如惯例,我们使用动态计数)被内联。1.0 的比率表示没有“收益”:每个新加的内联需要一个类型测试。值超过 1.0 的表明一些测试可以免费地内联。平均上,SELF-93 为每个新的它执行的内联类型测试移除了 1.88 个调用(图 7-12),所以“收益”是真实的即使编译器没有执行宽泛的数据流或者类型分析。程序通过类型反馈优化执行更少的类型测试。
7.5.2 类型反馈降低了类型测试的开销
类型反馈也降低了每个类型测试实际测试的类型数量(它的路径长度)。例如,在第一个类型测试成功之后的类型测试(即,对象类型测试是第一个类型测试)有一个长度的路径,即使这个类型测试包含几个场景。图 7-13 显示 SELF-93-nofeedback 和 SELF-93 的分发和内联测试的路径长度。每个类别的左框表示 SELF-93-nofeedback,右框表示 SELF-93。图 7-13 强调了两个效果。首先,内联的类型测试比起方法分发时的类型测试有更短的路径长度。例如,在 SELF-93 中每个类型测试序列的内联类型测试执行只有 1.08 个比较,但是分发测试执行了 1.62 个比较。
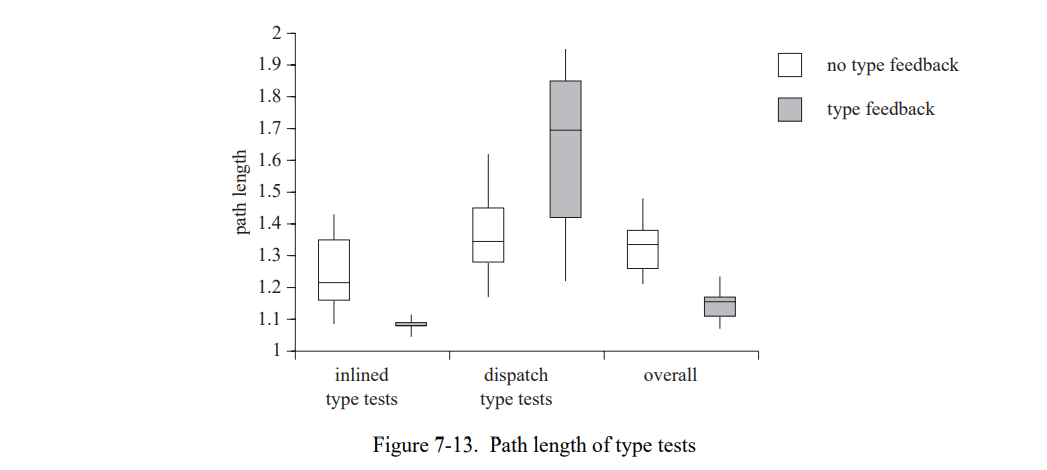
第二,类型反馈减少了内联类型测试的路径长度(从 1.24 到 1.08),但是增加了分派类型测试的路径长度(从 1.36 到 1.62)。内联测试中减少路径长度的主要原因是内联降低了代码中多态的度,通过为每个调用者创建被调用者的分离拷贝。因此,特定(内联的)被调用者中使用的类型只是它的调用者使用的类型,而不是几个调用者的合集。在 SELF-93 中内联类型测试的异常低路径长度(以及同样低的异常方差)显示绝大多数内联的需要一个类型测试的发送只需要执行单个比较来找到它们的目标。
分派测试增加的路径长度可能是没有内联的多态或者巨态调用的结果。因为许多单态调用被内联了,剩下的调用有更高的多态度,因此更长的路径长度。
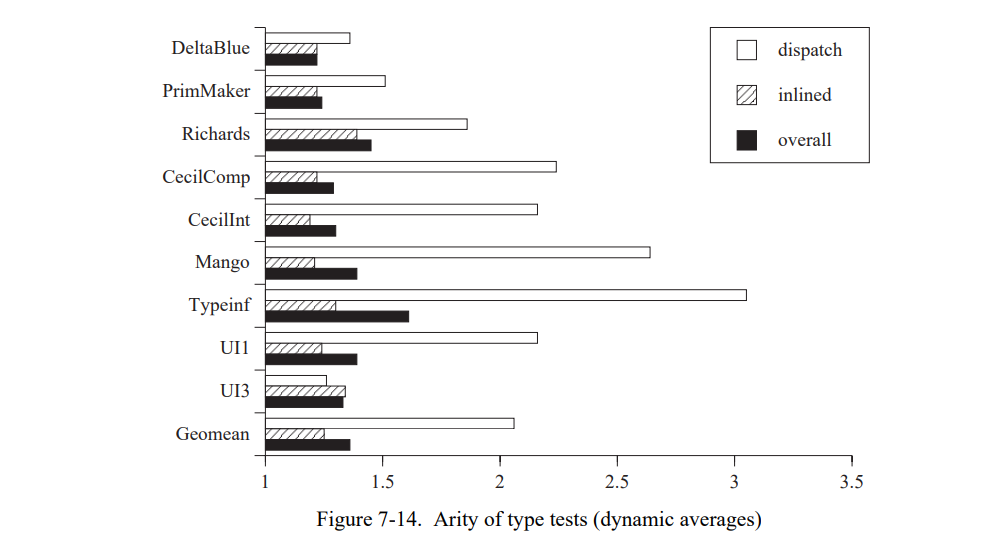
图 7-14 显示类型测试的平均稀有度,即,它们多态的度(类型测试中的场景数量或分派序列)。对于任意可能的执行类型测试的度总是大于或者等于它的路径长度。例如,一个度为 2 的测试(即,正确和错误的测试)可以有一个在 1 和 2 之间的路径长度,2是当它还包含未知场景,1 表示它不包含未知场景。数据表示了动态平均。
就像路径长度一样,(非内联)发送的分派的稀疏度高于内联发送的。因为内联发送从频率上占主导地位,所以总体的平均接近于内联发送的稀疏度。平均上,发送的度只是稍微高于它的路径长度。对于内联测试,平均度是 1.25 ,而 1.08 的路径长度。
如,图 7-13 观测的路径长度非常的小因为大部分的类型测试只包含一个或者两个类型。(一个稀疏度比路径长度高得多将会表明第一个被测试的场景与其它的非常相似。SELF-93 不会根据频率排序类型测试的场景,因为它不需要精确的边统计;低的稀疏度表明优化没有很大的不同。)
综上,类型反馈降低了类型测试的开销,因为它降低了它们的路径长度,即,每个发送的类型测试数量。路径长度和内联发送的稀疏度接近于 1,表明许多内联发送时是特化的就只有一个类型。
7.5.3 类型反馈降低了类型测试的时间开销
就像我们在前两节看到的,类型反馈降低了类型测试的数量和每个测试执行的工作。同时,这里有两个因素帮助降低 SELF-93 中类型测试的固有开销。图 7-15 显示了 SELF-93-nofeedback(上界) 和 SELF-93(下界)中类型测试花费的执行时间。在所有的测试集中,SELF-93 在类型测试中花费更少的时间;平均少于 1.62 次(几何平均)。这个降低不是分派和内联测试(即,更快的内联测试)不同代码序列的结果 – 两个序列几乎完全相同。
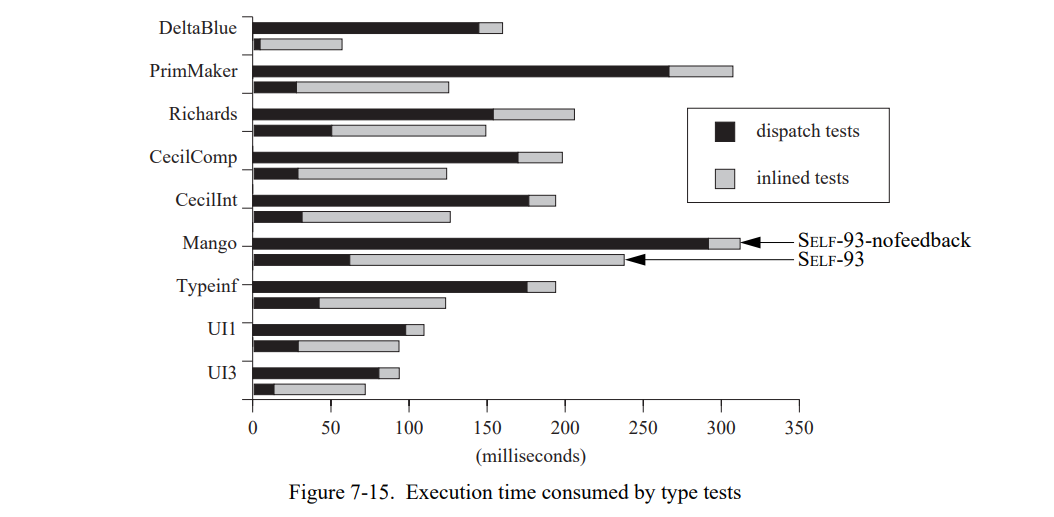
图 7-16 显示了 SELF-93 中类型测试花费的执行时间的百分比,分为分派和内联测试。平均上,在执行我们的测试集程序时,SELF-93 只花费了 15% 的时间在类型测试上;同时,大的测试集比小的测试集花费更少的时间在类型测试上。在与其它系统比较时,SELF-93 中的类型测试固有开销显得比较平和,特别是在考虑系统的绝对速度的时候(因为系统其它部分相关固有开销的增加看起来变得更快)。与之相比,SOAR,一个 RISC 处理器上带有特殊硬件支持的 Smalltalk 实现,花费了 23% 的时间在方法分派上,也花费了 24% 的时间在整数标签检查它没有包含特殊硬件[132]。在 Lisp 系统中,标签检查基本相似于类型测试,因为 Lisp 没有动态分派。Steenkiste 报告在 MIPS-X [121] 的 Lisp 上 11% 到 24% 的执行时间被花费在标签处理上,同时,Taylor 报告 SPUR 机器 (一个标签架构)上有 12% 到 35% 的指令调用了标签检查[126]。
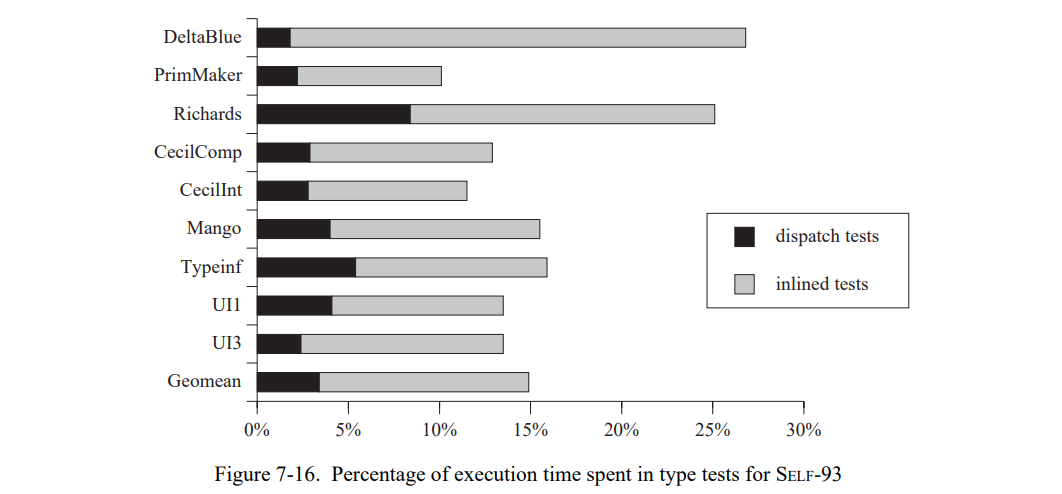
综上,类型反馈降低了类型测试的数量,每个测试的工作(路径长度)数量,和每个类型测试的总执行时间。平均上,程序花费小于 15% 的时间在类型测试上,即,消息分派。
7.5.4 类型分析 vs 类型反馈
如同我们在 7.3 节里看到的,一个使用类型反馈的系统(即,SELF-93)好于一个使用类型分析的系统(我们在大的面向对象的测试集上测试的 SELF-91)。那类型分析的价值是多少?比较 SELF-91 和 SELF-93-nofeedback,我们看到 SELF-91 只是勉强在测试集中快一点和内联近似相同数量的发送。虽然,难以拆分每个单独因素对于性能影响的不同(类型分析,静态类型预测,代码生成),结果强有力的说明了 SELF-91 中的类型分析无法偿还这些程序。
但是 SELF-93 中的类型分析的价值是多少,即,与类型反馈结合?因为 SELF-93 在我们测试的大的,面向对象的程序中花费了大约 10% 的时间在类型测试上(不包含类型测试需要的方法分派),似乎类型分析已经无法进一步提升性能了。但是,类型分析在一个特定的程序类中可能更有价值,带有一些小的循环。如果一个程序的内循环由少数几条指令组成,任意额外的类型测试会带来显著的性能命中它。例如,bubblesort 的内循环在 C 中由四条指令组成。单个测试验证数组的类型加上循环的四条指令,因此由一半的性能。此外,代码生成的影响微弱地(未填的延迟槽,冗余寄存器移除)倾向于放大很小的循环。
图 7-17 在原始 Standford 整数测试集上比较 SELF-93 和 SELF-91,一组小的整数测试集[21],大部分只有一行长。大部分程序带有两个版本,朴素和“OO”(面向对象)。oo 的版本已经被重写使得主要的数据结构为接收者。例如,bublle 让数据排序成为一个参数(接受者成为 bubble 测试集对象),但在 bubble_oo 中数组是排序消息的接收者。这个不同有巨大的性能影响(至少在 SELF-91 中),因为接收者类型由于客制化是已知的。SELF-91 在这些小的测试集中执行得比在我们主要的测试套中的应用来得好,优于 SELF-93 有 1.9倍。(但是SELF-93 在大的测试集上快了1.5 倍。)
SELF-91 在原始 Standford 测试集上性能比较好的原因有两个。首先,对于大部分测试集编译器可以静态地知道所有的接收者类型,因为它们是常量或者通过静态类型预测获得。(就像 7.4.1 节讨论的,SELF-91 的性能在静态类型信息被移除时会陡然下降。)因此,SELF-91 编译器可以内联所有的发送,相对于 SELF-93 并没有劣势。第二,SELF-91 执行各种优化在这些测试集上表现良好,如循环拆分,边界分析(用来消除数组下标边界检查和算术溢出检查),和通用的子表达式消除。因此,它的后端相当复杂。因为大部分的测试集非常的小,SELF-93 代码生成器的弱小(如额外的寄存器移除和重复加载)有比较大的性能影响。
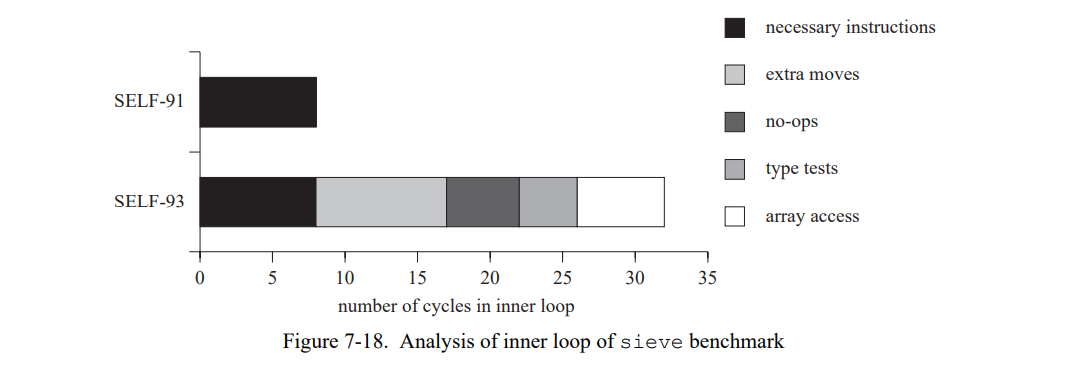
图 7-18 显示 sieve 的内循环执行的周期数,在 SELF-93 中是 32 周期 vs SELF-91 中 8 周期。后端不同对于性能不同有更多的影响。不必要的寄存器移动和未填充的延迟槽,在 32 个周期中有 14 个,缺少数组优化消耗了另外 6 个周期(SELF-91 使用了派生的指针来一步通过数组,而 SELF-93 在每个迭代中索引数组。)类型分析只消除 4 条指令,两个 k 的整数类型测试。因此,如果 SELF-93 有 SELF-91 的后端优化但不执行类型分析,它在 sieve 上的性能会更有竞争力。
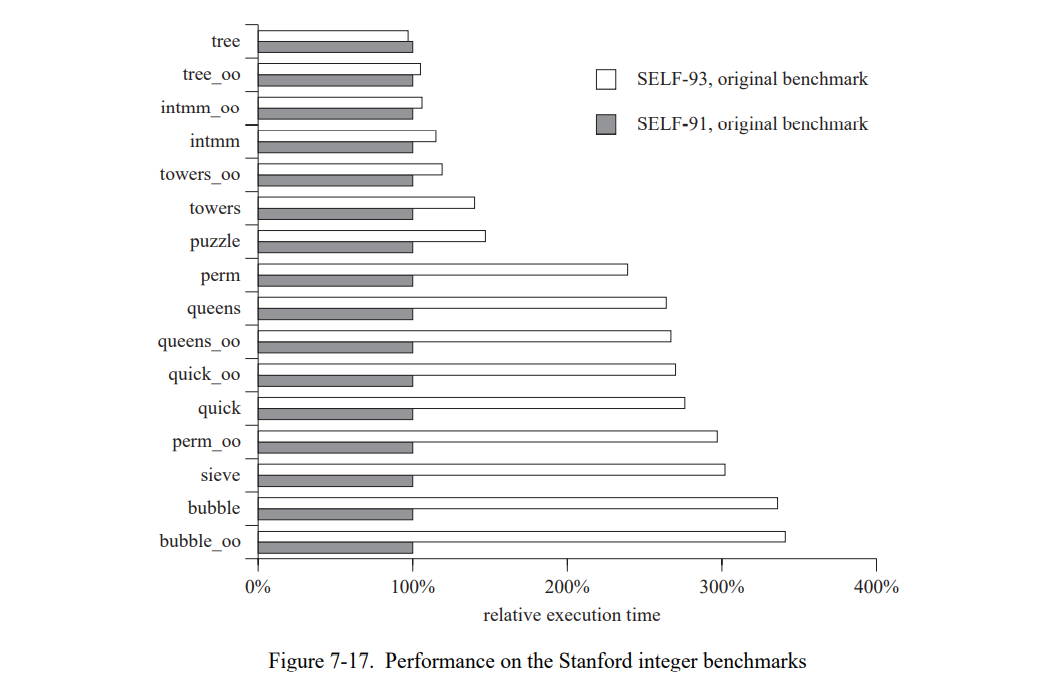
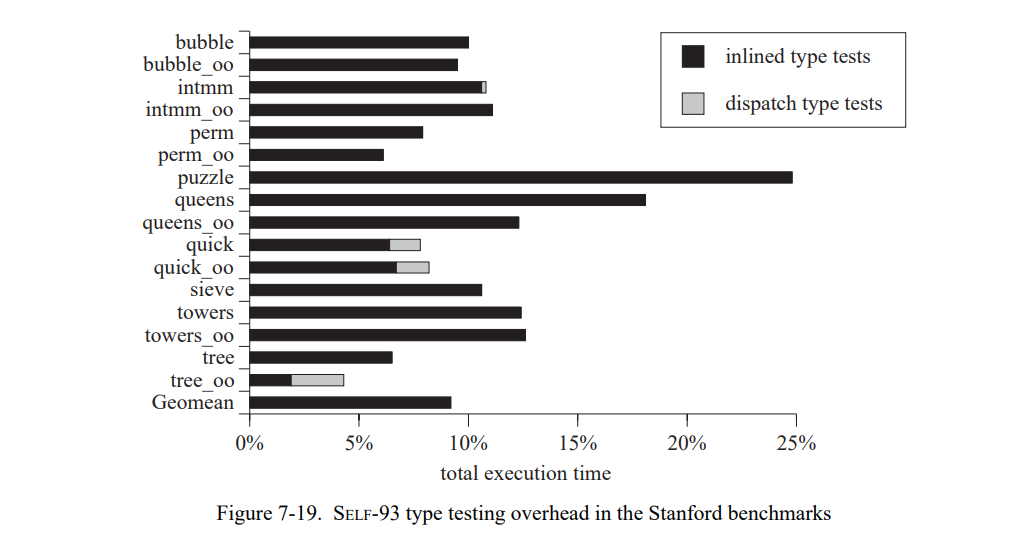
图 7-19 显示在 SELF-93 中加入类型分析不大可能可以加速任何的测试集,因为平均类型测试开销低于总执行时间的 10 %。例如,bubble 在 SELF-93 中慢了 6 倍,也只花费了 10% 在类型测试上。
综上,SELF-93 在这些测试集上相对比较低的性能源自我们最初决定保持编译器小和快速的决定。当有一个带有全局数据流分析和标准优化的后端,SELF-93 能达到一个好的性能水平,可以和 SELF-91 在这些测试集上竞争。标准的数据流技术也会降低类型测试的固有开销:对于值 v 的一个类型测试的每个分支 i,定义一个辅助值 typev 来表示类型测试的结果, 在分支 i 开始的地方加入一个赋值语句 typev = Ti(Ti 表示正在测试的),然后加入 kill(v)到 kill(typev)中。然后,我们可以优化的类型测试使用了标准的值传播:如果 typev 的一个单定义点到达 v 的一个类型测试,这个类型测试可以被消除。使用标准的数据流测试而不是成熟的类型分析,牺牲了一些精度,因为当超过一个定义点到达一些点时值传播会 “丢失” typev 的值,而类型分析会保持追踪值的集合。但是,前面提到的大部分主要的类型测试调用单个类型然后标记“例外”跳到不通用(82 页中的图 7-14)。因此,typev 最多一个定义点会到达其它的类型测试,类型信息丢失信息的情况将不会发生。因此,我们相信加入标准的数据流到编译器中将会和全类型分析系统差不多,能消除大部分冗余的类型测试。
7.5.5 重编译效果
迄今为止 SELF-93 所有的性能数据都包含一些未优化的代码,因为重编译系统不会优化程序中所有的函数。如果系统编译了每个函数程序会运行多快,即,未优化代码花费了多少时间?表 7-7 回答了这些问题。优化代码和未优化代码花费的时间都是通过 Unix Kernel 的分析工具测量的;我们重复测试集 100 次(重编译关闭)来获得精确的数据。
对于大部分的程序,未优化的代码只占总执行时间的 5% 。有两个程序花费了大部分的时间在未优化代码上,PrimMaker 和 UI1,两个都使用了动态继承(DI),在我们的比较中这降低了所有优化编译器的效果。对于动态继承,一个对象可以实时地改变它的继承结构,从而改变了继承的方法集合。当前 SELF 无法内联任何可能会被动态继承影响的发送,DI 的查找结果不是一个编译时常量。DI 也会对重编译系统造成问题;因此,它从不重编译会被 DI 影响的方法。
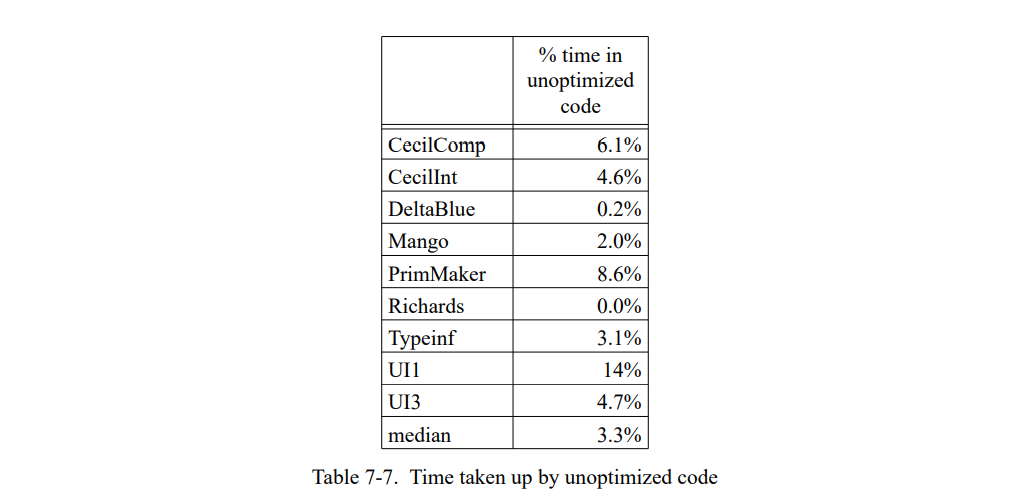
有两个测试集几乎没有花费时间在未优化的代码上,Richards 和 DeltaBlue,是两个较小的测试集,大部分时间花费在非常快的已编译方法上。例如,Richards 花费 95% 的时间在已有的 7 个已编译方法上。(对于大程序,前 20 的已编译方法合起来占了 40-60% 的执行时间。)
综上,未优化代码的速度对于测试集的测量基本是无关紧要的,因为它们没有花费太多的时间在未优化代码上。例如,它可能会替换无优化的编译器为解释器而不会损失太多的性能。
7.5.6 已编译代码的大小
不管额外的内联,程序生成 SELF-93 的代码没有比其它编译器生成的大太多。图 7-20 显示 SELF-93 生成的已编译代码的大小(每个测试集的上界)和 SELF-91(下届)生成的代码与 SELF-93-nofeedback 相比。平均上,SELF-91 的代码最小,比 SELF-93-nofeedback 的代码小 9% 。相对于 SELF-91 最好的后端不同的是 – SELF-93-nofeedback 生成更多的寄存器移动和冗余的加载和存储。SELF-93 的代码大于平均,比 SELF-93-nofeedback 大 14%,比 SELF-91 大 25%。
类型反馈使能的额外的内联有时候会导致大代码。例如,Typeinf 已优化的 SELF-93 代码比 SELF-93-nofeedback 大 40%。但是,除了 Typeinf,只有 CecilComp 的优化代码有较大的增加。此外,额外的内联也会降低代码大小。例如,Richards 在用 SELF-93 编译时变得很小。
第二,未优化代码的密度远小于已优化代码(见 4.3.5 节)。因此,一个程序未优化的代码部分比起它们被优化后使用更多的空间。我们测量使用的这个编译器配置会让重编译比较激进,因此程序中只有相当小的部分会保持未优化。更少的激进重编译,更多的代码保持未优化,总的代码大小更可能会增加。
7.6 总结
类型反馈在优化 SELF 程序里非常的成功:在 SELF-93 编译器中,一个大的 SELF 应用套件的性能提高了 1.7 倍。比起 SELF-91,这个前一代 SELF 编译器,SELF-93 快了 1.53 倍,即使 SELF-91 有明显更多的编译,执行更多的后端优化。类型反馈降低了程序 3.6倍的调用次数。基于统计的重编译系统在寻找我们应用中的时间关键路径上是高效的;大部分的应用花费少于 5% 的时间在未优化的代码上。
虽然,SELF 中的任意发送都是动态分派的,优化程序的分派的固有开销是比较合适的。SELF-93 用类型测试序列实现消息发送,用 PICs(第三章)或内联代码。即使 SELF-93 编译器执行昂贵的优化来消除冗余的类型测试,类型测试的执行时间开销还是比较小的,我们的测试套件大约只有 15%(包括方法分派的测试)。类型反馈比起没有使用反馈的系统实际降低了类型测试的固有开销。内联类型测试有更短的路径长度:平均上,一个类型测试序列在跳到目标代码前只要执行 1.08 个比较。
类型反馈可以降低那些使用静态类型预测或者分析的系统的性能变化波动。在那些系统里,一个小的改变会带来巨大的性能影响,如果改变移除一个重要的类型信息,或者它导致了类型预测失败。因为我们类型反馈的实现,从程序运行本身获得它的信息,更少地依赖于静态信息,因此,一个小的改变不会从根本上改变编译器可以执行的优化集合。
类型反馈是一个可以显著加速面向对对象程序的简单技术。我们希望这个结果能引导其它面向对象语言的实现(或者其它有相同实现属性的系统)考虑类型反馈作为一个吸引人的技术实现。
8. 硬件对于性能的影响
专用硬件可以多大程度上提升面向对象程序的性能?之前许多的研究已经表明大量的硬件特性可以提升性能,有些面向对象系统较重地依赖于硬件支持。例如,Ungar 报告 SOAR 系统 46% 的慢是因为没有寄存器窗口,26% 的慢是因为没有标签计算的指令[132]。Willians 和 Wolczko 争辩软件控制的缓存提高性能和面向对象系统的局部性[142]。Xerox Dorado Smalltalk,长时间是最快的可用 Smalltalk 实现,包含微代码支持 Smalltalk 虚拟机的大部分[43]。但是,和 SELF-93 相比没有一个系统使用优化编译器,因此,前面的研究结果对于当前的 SELF 实现没有效果。
为了评估哪个架构或者实现特性(任意)对于执行有利,我们分析了 SELF-93 编译的程序的指令使用情况。首先,我们比较 SELF 指令和 SPECInt89 测试集的混合,这个测试集是由 C 写的程序组成的。然后,我们评估 SPARC 架构的两个特性(寄存器窗口和标签计算),这些通常被认为是可以提高面向对象程序的性能。最后,我们检查测试集程序的缓存性能。
这个结果表明 SELF-93 编译的程序与已优化的 C 程序差异很小,小于 C++ 程序套件。不像前一个研究,我们不能找到任何的“面向对象”硬件特性,可以提升超过 10% 的性能。
8.1 指令使用
在设计一个架构的时候,一个首要的任务是识别经常使用的操作,然后优化它们。之前许多的研究已经找到面向对象语言的执行属性,与 C 非常的不同,因此有需要面向对象架构的争辩。例如,Smalltalk 的研究 [86,132] 表明调用比其它语言更频繁。即使和混合语言如 C++(以 C 为核心因此没有太多的不同) 比较,也能找到明显的不同。表 8-1 列出的数据来自于 Calder et al.[16],测量了几个大的 C++ 应用,然后与 SPECint92 套件以及其它 C 程序比较。这个研究使用 MIPS 架构上的 GNU C 和 C++ 编译器。即使 C++ 在理念上与 C 相似,也有明言了执行行为上的不同:例如,C++ 执行几乎 7 倍多的调用,且执行不到一半的条件跳转。
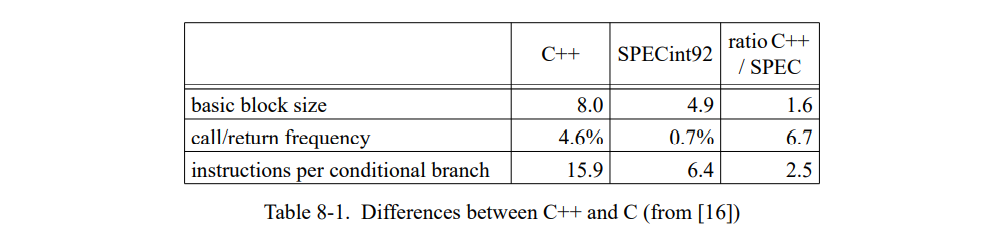
基于这些数据,一个期望是纯的面向对象语言如 SELF 与 C 离得更远,因为语言本质上与 C 完全不同。(之前说过,例如,即使是一个整数加法或者 if 语句都会调用消息发送。)但是,执行行为是一个功能,不只是源语言的属性,也有编译技术,后者会造成很大的不同。图 8-1 显示我们测量的四个 SPECint89 整型测试集(用 C 写的)和九个 SELF 程序的动态指令使用情况。总结的数据使用箱型图(下标包含详细的数据)。每个分类最左边的方框表示 SELF-only,即,已编译 SELF 代码的执行,排除所有花费在运行时系统的时间(用 C++ 写的)。每个分类中间的方框(全灰)表示完全的 SELF 程序(即,所有的用户模式指令)。我们测量了两者,因为 SELF 程序经常调用运行时系统的进程,例如,分配对象或者调用 C 库中的函数。有些程序花费三分之一的时间在这些例程上,我们要保证我们的数据不被这些非 SELF 的执行行为带偏。在另一方面,显示 SELF-only 也会误导,因为这些数据不能表示处理器实际执行的指令情况。
因为 SPECint89 套件里只有四个测试集,指向 C 的独立数据直接被显示,方框(点缀)只是用于引用。SPECint89 数据来自于 Cmelik et al[33]。
图 8-1 揭示了几个有趣的观点:
- 总体上,SPEC 测试集与 SELF 有些不同。通常在独立的 SPEC 测试集间的差异大于 SELF 和 C 的差异(在图中,SPEC 的盒子通常大于相关的 SELF 盒子)。
- 平均上,SELF 程序执行更多非操作,更多无条件跳转,更多逻辑指令。但是,大部分这些不同都可以被当前 SELF 编译器简单的后端解释,下面会详细的解释。因此,它们是当前编译器后端的一部分,不能链接到 SELF 面向对象的特性。
- SELF 基础块与 SPEC 程序的大小相似,4.5 条指令 vs SPEC测试集(几何平均)的 4.4 条。但是,调用和返回更加频繁,每 33 条指令(SELF-only)发生和每 25 条指令(SELF)发生 vs SPECint89 的每 57 条发生。有趣地是,SELF 的运行时系统(用 C++ 写的重度标记内联函数)比起 SELF 代码有更高的调用/返回频率。
为了更精确地比较,我们排除两类因当前 SELF 编译器后端不足而扭曲的指令。后端没有填充延迟槽(除了在固定的代码模式),因此 SELF 程序包含许多的非操作(6.2% vs C 的 0.45%)。同时,它没有优化跳转链和改变代码块来避免无条件跳转;因此,代码包含许多的无条件跳转(2.7% vs C 中的 0.8%),这些可以被一个更好的后端消除。因为这些额外的指令存在扭曲了其它指令分类的频率,我们在未来的图像中会排除非空操作和无条件跳转。
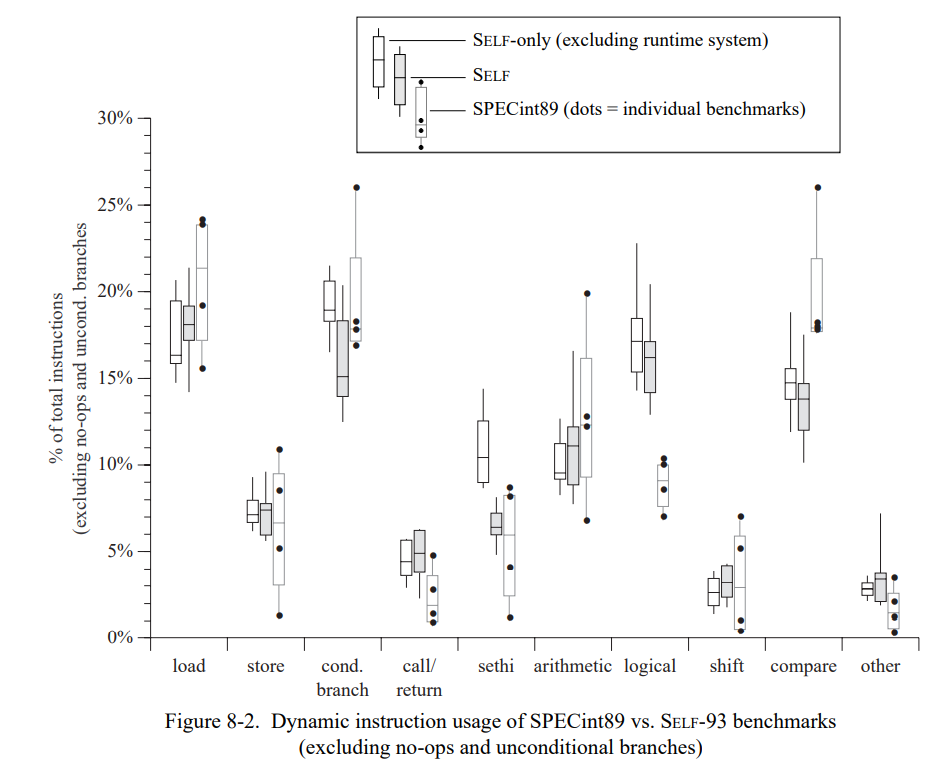
图 8-2 显示已调整的执行频率。比较 SELF 和 SELF-only,可知运行时系统不会影响整体的行为太多。只有两个表现出了明显的不同,分别是条件跳转指令和 sethi 指令。条件跳转指令在 SELF-only 比在 SELF 中更频繁,但和 SPEC 程序相比的话不是很多。sethi 指令用于加载 32位常量;有两个原因导致它们频繁地在已编译的 SELF 代码里出现:第一,SELF 中值 true,false 和 nil 是对象,通过 32 位代码常量表示;相反,C 程序使用短立即数 0 和 1 表示。第二,用类型描述器的地址来表示一个对象类型,消息分派的实现会比较接收者的类型和期望的类型。因为消息分派是频繁的,所以是 32 位常量。
与 SPEC 测试集比较,SELF 有稍微的不同。除了上面提到的条件跳转和 sethi 指令的不同,只有逻辑指令和比较变现出了明显的不同。逻辑指令在 SELF 中比较频繁有两个原因。首先,编译器后端只使用了一个简单的寄存器分配器,因此生成了许多没必要的寄存器移动。(移动指令在 SELF中占逻辑指令将近一半。)第二,SELF 使用标签对象表示,用低两位作一个标签。分派测试涉及整数,包括整数计算操作,使用一个 add 指令测试它们的参数标签;类似的,运行时系统(如,垃圾回收器)经常提取对象标签。相应的,这些 and 指令占了逻辑指令的 25 %。我们无法解释 SELF 和 C 程序剩余的不同,因为没有 C 使用逻辑指令的详细有效数据。
SELF 比 SPEC 整型测试集执行更少的比较。这个结果让我们感到意外;我们预期 SELF会执行更多的比较,因为消息分派调用了比较并且频率比较高。如果 SELF 使用间接函数调用来实现消息分派,可以解释面向对象编程模式低条件跳转频率的原因,这种模式典型的将 if 和 switch 替换为动态分派;Calder et al. 通过比较 C++程序和 SPEC C 程序来观察这个影响[16]。但是,因为 SELF 实现没有使用间接函数调用,我们无法用这个来解释差异。一个可能的方式是 SELF 优化器消除了足够多的分派类型测试,从而降低了比较的整体频次。
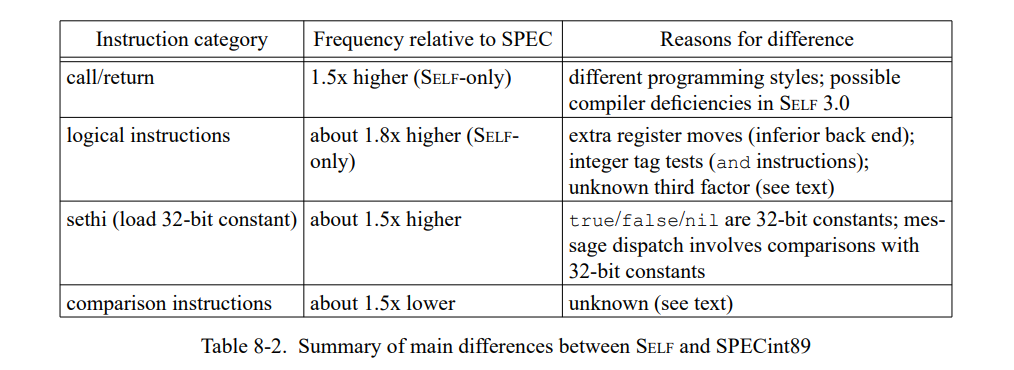
表 8-2 总结了指令使用主要不同。整体上,SELF 程序和 SPEC C 程序只有很少的不同,考虑到两个语言非常的不同,这是一个令人惊奇的结果。更令人惊讶的是 SELF 比 C++ 更接近 C。图 8-3 从 [16] 和 我们自己的测量总结了 C++ 的数据。在每个分类上,SLEF 都比 C++ 更接近 SPEC。例如,C++ 中的基础块大小高了 SPEC 1.6 倍,但 SELF 只比 SPEC 高了 1.1 倍。(有些不同可能是由于 SPARC 和 MIPS 编译器不同导致的,但 Calder 等使用了相同的编译器技术(GNU)来编译 C 和 C++。)
显然,执行行为是一个源语言属性更是一个编译器技术功能。我们相信当编译器使用特定的 O0 优化,C++(或其它面向对象语言)和 C 的大部分不同都会消失。当然,直到这样的系统实际被实现,不能确定一个更好的优化是否可以实际让其它面向对象语言更接近 C。但是,根据我们的数据,任何关于面向对象语言要有必要的硬件支持的宣称需要被谨慎对待,除非用于研究的系统采用了先进的技术,或者当这样的优化已经被在特定语言上展示位低效了。
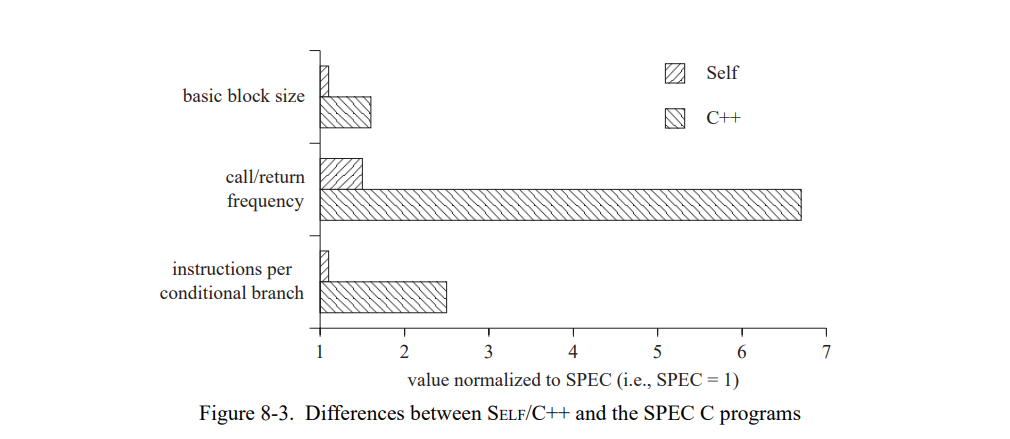
8.2 寄存器窗口
SPARC 架构 [118] 定义了一组重叠的寄存器窗口,允许过程通过选择一组新的寄存器来保存被调用者的状态。只要调用深度没有超出可用寄存器组的数量,这样的保存是在一个周期里完成而不需要任何内存访问。当一条保存指令执行时如果没有空的寄存器组,一个“寄存器窗口溢出”的陷阱就会发生,然后陷阱处理会透明地通过保存一组寄存器的内容到内存中来释放寄存器组。相似的,一个“窗口溢出”陷阱被用于当需要的时候从内存中重新刷新寄存器。
寄存器窗口最初是作为 Berkeley RISC 架构的一部分提出的,为了让过程调用尽可能地快[102]。如果过程调用深度的变化没有显著地超过可用寄存器窗口的数量(通常,当前的 SPARC实现是 7 或者 8 ),大部分调用执行没有任何的内存访问。
寄存器窗口对 SELF 有好处?图 8-4 显示了寄存器窗口溢出和下溢相关的方形图,分别是未优化 SELF,SELF-93,和 C++(使用 Riuchards 和 DeltaBlue),作为寄存器窗口有效的一个功能。固有开销被测量作为花费在程序用户模式指令的时间百分比。就是,刨除任何的缓存开销的基础时间和花费在窗口陷阱处理的时间。一个 100% 的固有开销,意味着执行时间是两次,只要有一个无限大的寄存器组。根据实际的系统,我们在 y = 100% 的地方截断图像,这是为了不失去有趣点的分辨率(SELF-93 是一个 8 窗口的寄存器,其中 7 个对用户程序有效)。
期望,有效寄存器窗口越多寄存器固有开销会下降,因为更少的溢出和下溢出。对于 7 个窗口(大部分的 SPARC 实现都是这个窗口数)的 SELF-93 固有开销中位数只有 11%。C++ 程序的固有开销波动比较大。对于大部分的 Richards 版本,固有开销是 0(因为它不会超过 7 个调用深度),但如果用 Sun CC 编译固有开销是 74%(显然,cfront-base 编译器比 GNU C++ 执行较少的内联)。类似的,DeltaBlue 的固有开销在 16% 到 74% 间波动,这取决于编译器和版本(虚拟与否)。没有意外的,未优化的 SELF 程序有极端高的固有开销,因为它们基本都有超过 8 的调用深度。对于 7 个寄存器窗口,未优化 SELF 代码的中位数固有开销是 140%。
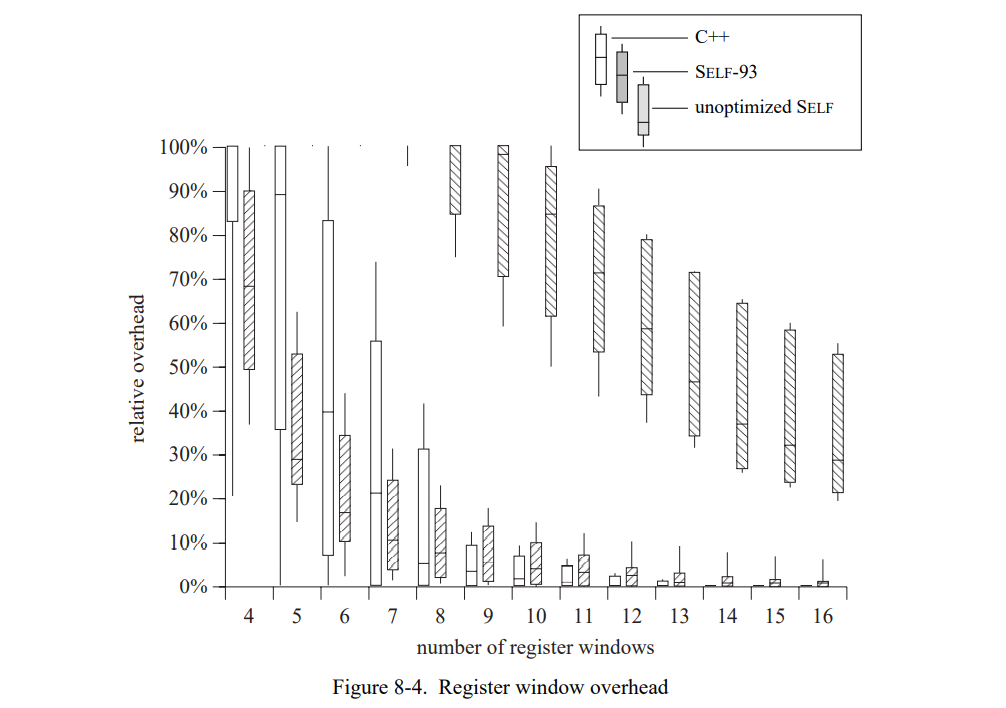
作为比较,SOAR 架构有 8 个窗口,每个窗口有 8 个寄存器;Ungar 报告所有调用中只有 2.5% 会导致寄存器溢出[132]。对于未优化的 SELF 这个比率是 9.4%。 显著不同的原因可能是大部分 SELF 没有硬关联通用的控制结构,但 Smalltalk-80 有。因此,在 SELF 中 if 语句或者循环导致了更多的调用深度,而在 Smalltalk 里是没有的。
上面的数据是基于溢出花费 205 周期,而下溢出花费 152 周期,这是在 SPARCstation-2 运行 SunOS 4.1.3 的经验测量值。寄存器窗口的溢出和下溢出的处理是很昂贵的,因为他们执行在管理者模式,这会导致许多复杂性。例如,陷阱处理必须保证存取要执行在用户程序的内存访问权限下,而不是内核。SPARC V9 架构修正了这个缺陷,因此窗口处理程序可以执行在用户模式。这个修改降低了窗口处理开销超过 10 (!)倍,每个陷阱只要 19 条指令。因为这个改动,窗口处理固有开销变得很小。即使只减少了 5 倍,SELF-93 剩余的固有开销也是微不足道的,尽管未优化代码有异常高的调用频率和调用链深度,也只有 28% 的开销。故,寄存器窗口没太大用–即使对调用深度比较高的程序–只要溢出和下溢出足够快。
寄存器窗口有两个潜在的优势。首先,它们在某些方面简化了编译器,因为它不在需要追踪跨函数调用需要被保存的寄存器,不用关心如何最小化寄存器溢出的结果。但是,效果似乎比较小,特别是在优化编译器上。第二,寄存器窗口潜在地为寄存器溢出节省了存取指令。寄存器窗口会提高 SELF 的性能吗?因为 SELF-93 缺少一个考虑寄存器溢出的寄存器分配器,我们无法测量寄存器窗口消除的内存引用的数量。但是,通过假设每个调用没有寄存器窗口会存 1.5 个值到栈上,我们可以得到一个估算值,即接收者和 0.5 个参数(这个平均参数数量来自 Smalltalk[86])。非叶子节点调用需要保存返回 PC 和帧指针(2 个字);我们也假设它们保存了两个局部。缺乏任何的数据,我们假设 50% 的调用是非叶子节点。同时,平均每个调用存取 3.5 字。因为调用大致为 SELF-93 所有指令的 1.5% ,这会增加 10.5% 的指令数量(每个调用 3.5 个存和 3.5 个取)。在我们相关的机器上,取需要 2 周期,存需要 3 个周期,所以会花费 26% 的周期(忽略缓存影响)。对于未优化的代码,相关的固有开销大致是两倍高,因为调用频率是原来的两倍。
基于这个大致的评估,会出现 SPARC V8 寄存器窗口(带有高的陷阱开销)提高了 SELF-93 的性能(11% vs 大约 26% 的固有开销来存取值),但是却显著地增加了未优化代码的执行时间(140% vs 大约 52% 的固有开销)。而对于 SPARC V9 寄存器窗口(至少 5 倍低的陷阱开销),两个场景的性能都提升了,大约有 24%(26% - 11/5%) 是优化代码的,而相同的 24% 是未优化代码的。但是,这样的机器可能也会提供一个周期的存取指令,降低了寄存器窗口的性能优势大约 8%(10.5% - 11/5%)在优化代码上,以及 -7%(21% - 140/5%, 即,劣势)在未优化代码上。
与之相比,Ungar 报告 SOAR 在没有寄存器窗口时会慢 46% [132]。这个差异来自于 SOAR 使用的非优化编译器,没有执行任何的内联,导致高的调用频率。因此,Ungar 的数据高估了寄存器窗口的收益,因为每个调用保存的寄存器数量被认为是方法返回时非空(即,使用过)寄存器的数量。
因此,虽然这些估算是相当粗略的,但是可以知道的是寄存器窗口没有显著地提升 SELF 的性能。在大部分相似的场景中,它们加速了 8 % 的优化代码,降低了 7% 的未优化代码的速度。
8.3 标签计算的硬件支持
标签整数加法和减法指令是一个独特的 SPARC 特性,一个被结果驱动的项目。SOAR Smalltalk 如果没有他们会慢 26% [132]。但是在一个带有优化编译器的系统如 SELF-93 它们有用吗?为了回答这个问题,我们首先需要关注 SELF-93 中的整数加法(或者减法)。假设 x 和 y 是整数,表达式 x+y 被编译成如下代码:
1 | if (x is integer) { // 3 instructions (test & branch, unfilled delay slot) |
当 x 或者 y 有错误的标签(最低两位不是 0)或者加法溢出时,tagged_add 指令会设置溢出位。x 的类型测试是 “+” 消息的类型反馈测试,当 x 的类型已知时可能会被忽略;通常,在类型测试和标签加法间会有其它的指令,这取决于整型 “+” 方法的定义。(当前,这些所有的指令都可以从标准定义中优化掉。)因此,SELF-93 中一个整数加法只要 6 条指令。
加法的理想代码序列,当标签加法指令,只要一条:
1 | tagged_add_trapIfError(x, y, result); |
标签加法(taddcctv 在 SPARC 的语法)赋值给结果寄存器这种变体只有当 x 和 y 都是整数标签且加法没有溢出时才会出现。否则,一个陷阱会发生。SELF-93 当前没有用到这种变体,因为运行时系统需要一些加法机制来处理陷阱和必要时重编译激进的已编译代码(当整数类型预测不在有效时,避免进到频繁重复的陷阱。)但是,这种支持不难添加。因此,为了获得标签指令收益的上界,我们会假设理想的系统会大量使用标签计算来持和执行所有的整型加法和减法都可以在一个周期里完成。
最后,如果 SPARC 没有标签指令,SELF-93 的代码序列如下所示:
1 | if (x is integer) { // 3 instructions (test, cond. branch, unfilled delay slot) |
对于额外的类型测试,这个序列只要两条额外的加法指令,共要 8 条指令。因此,标签算术指令对于每个算术运算最多可以节省 7 条指令。所有上面的代码序列都是假设像 SELF-93 一样的朴素的后端产生的;在有更好的优化后,代码序列可以更短。例如,在没有使用标签指令时,一个更好的代码序列会填充延迟槽,只使用一个标签测试(第一次,ORing x 和 y),消除额外的赋值,节省了 3 到 4 条指令。对于我们的比较,我们假设每个加法或减法是 6 条指令序列。
为了整数加法和减法,标签指令也被用于整数比较和其它整数标签测试(如,验证数组索引操作的索引是一个整数)。为了这些操作中的每个整数标签测试,我们假设了 2 个周期的固有开销(测试 + 跳转 + 未填充延迟槽–标签加法)。
因此,标签运算指令节省的周期数是 5 * number_of_adds + 5 * number_of_subtracts + 2 * number_of_integer_tag_tests。表 8-3 表示了 SELF-93 中这些操作的频次,假设它们每个都只要一个周期。 整数运算指令很少使用,平均上所有指令中只出现了 0.6%;整数标签测试更频繁,中位数是 2.2%。在没有硬件支持标签整数时,我们估计预测 SELF 会比最大使用标签指令的系统慢 7%。
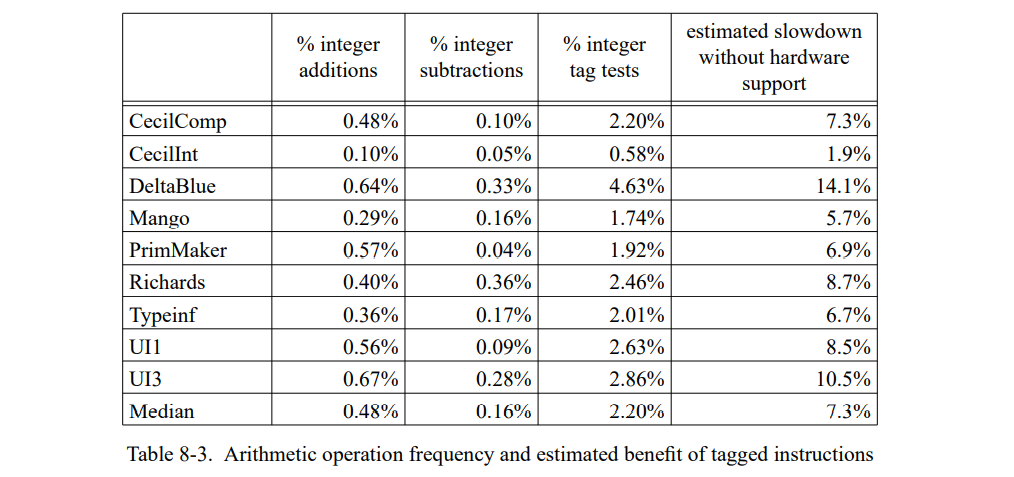
但是,真正的节省可能更小,因为我们的估算做了几个简化的假设,所有的这些都倾向于夸大标签运算指令的收益:
统计指令而不是周期高估了节省数,因为代码序列是没有内存操作的,因此执行可以接近于 1.0 CPI(每指令周期),然而我们的参考机全部的 CPI 接近于 2。因此,替换标签指令的序列消耗了所有指令的 7%,但只有全周期数的 3.5%。尽管高估的程度与机器相关,但我们相信非标签指令可以低 CPI 的执行,即使在带有高预测惩罚的超标量机器上也一样,惩罚是因为激进的预测(整数类型测试几乎总是成功的,溢出的比较少)。因此,已经存在的 SPARC 实现无法并行的执行标签指令和其它指令[123,因为它们会陷入,所以一条标签指令消耗和几条其它指令一样多的时间(SuperSPARC[123] 上是三条)]。
我们假设编译器没有整数加法或者减法的类型信息,因此,不得不显式地测试所有整数操作的标签。这边高估了显式标签检查的开销,因为,一个参数可能是一个常量(如,循环下标加 1),或者已知。
因为这些原因,我们将估算的 7% 作为支持我们测试集套件中程序的标签指令的收益上限。在我们的参考系统上,一个更精确的上限是执行时间的 4%。因此,移除 SPARC 架构的标签加法和减法指令不会显著地降低 SELF-93 的性能。
这个结果和 Ungar 的测量, SOAR 在移除标签指令时会有 26% 的下降[132],有所不同。为什么会有这么大的不同?通过分析 Ungar 的数据,我们可以找到几个估算过高的原因:
- Ungar 的数据包括了几个标签指令(如,“取” 和 “取类”)的加速,这些是不在 SPARC中,或者 SELF-93 不需要的。只包含标签运算指令的时候,Ungar 的估算为 12%。
- SOAR 整型运算代码序列没有标签指令会变慢,因为 SOAR 没有溢出时跳转指令。当有了这样一条指令后,代码序列会变得很短,降低估算下降值到 8 %。
- SOAR 中的整形计算比 SELF-93 的更频繁。在 Ungar 的测试集中,它们占全部指令的 2.26% vs SELF-93 中的 0.64%。我们不知道这个不同是编译器的不同还是测试集的不同导致的。
综合起来,这些因素解释了我们的估算和 SOAR 估算间的许多不同。
SELF-93 没有明显的从 SPARC 架构中的标签加法和减法中受益:一个充分使用了这些指令的系统,只节省了 4% 的总时间。
8.4 指令缓存行为
作为性能分析的一部分,我们测量了 SELF-93 的缓存行为,试了一个缓存配置的变种。所有的缓存同我们的参考机器的配置相同(两路关联,每行 32 字节,数据缓存带有子块放置的写分配,缓存失效惩罚 26 个周期。)我们分析最有趣的结果是,对于中型缓存,SELF-93 花费了显著的时间在指令缓存失效上,以及少量的时间在数据缓存失效上。图 8-5 表明执行时间的固有开销与一个带有无限快内存系统的系统的关系;例如,40% 的固有开销意味着系统比理想系统慢了 1.4 倍。对于 参考机上使用的 32K 指令缓存,指令缓存的固有开销从几乎为 0 (两个比较小的测试集,Richards 和 DeltaBlue)到几乎有 70%(CecilInt),中位数是 40%。 对于所有的大小测试,将缓存大小加倍几乎可以将平均固有开销减半。通过将结果和另一个使用 32路组关联的缓存比较,我们确定失效是容量失效主导的,不是冲突失效主导,所以增加缓存关联没有帮助。测试套件中的大部分程序都比较大(代码有 500 KB,或者更大),所以出现了 32K 缓存不够大,不能支持程序的工作集。但是,一个 128K 的缓存,可以降低固有开销到合理水平(平均 10%)。
SELF-93 的代码大约比 SELF-91 或者 SELF-93-nofeedback 大 25%,就像我们在 7.5.6 节看到的。增加的代码空间会对缓存固有开销有多大影响?为了获得一个近似解,我们测量了 SELF-91 的缓存行为,这个系统生成最小的代码(图 8-6)。SELF-91 的指令固有开销大约是使用了 128K 缓存大小的 SELF-93 的一半,当缓存更大时数据更低。对于参考系统的 32K 缓存,SELF-91 只比带有理想内存系统的系统慢 20%,相反却比 SELF-93 慢了 40% 。尽管增加了指令缓存的开销,SELF-93 却运行地相当的快。
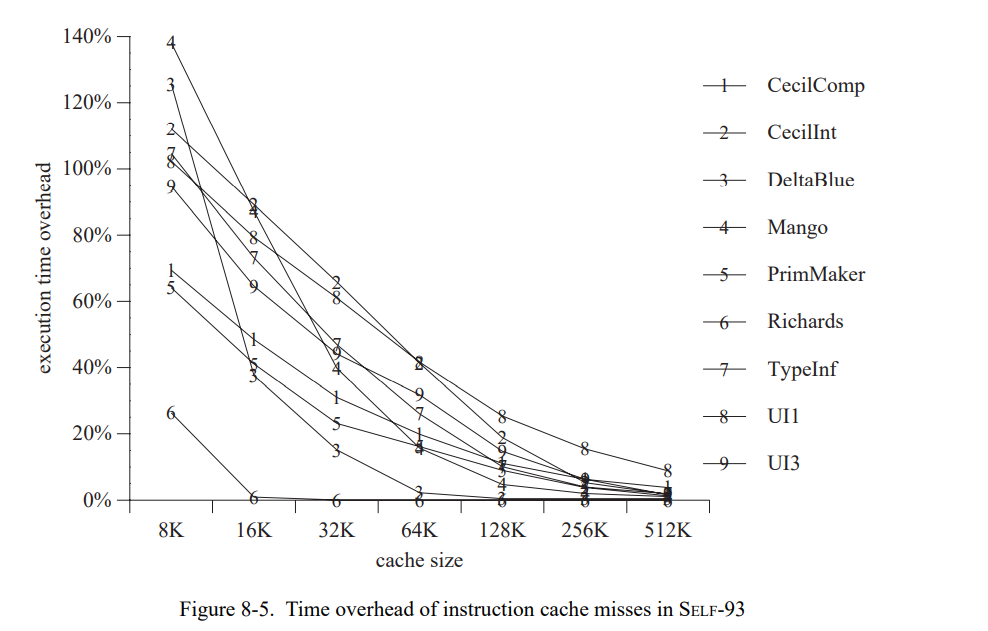
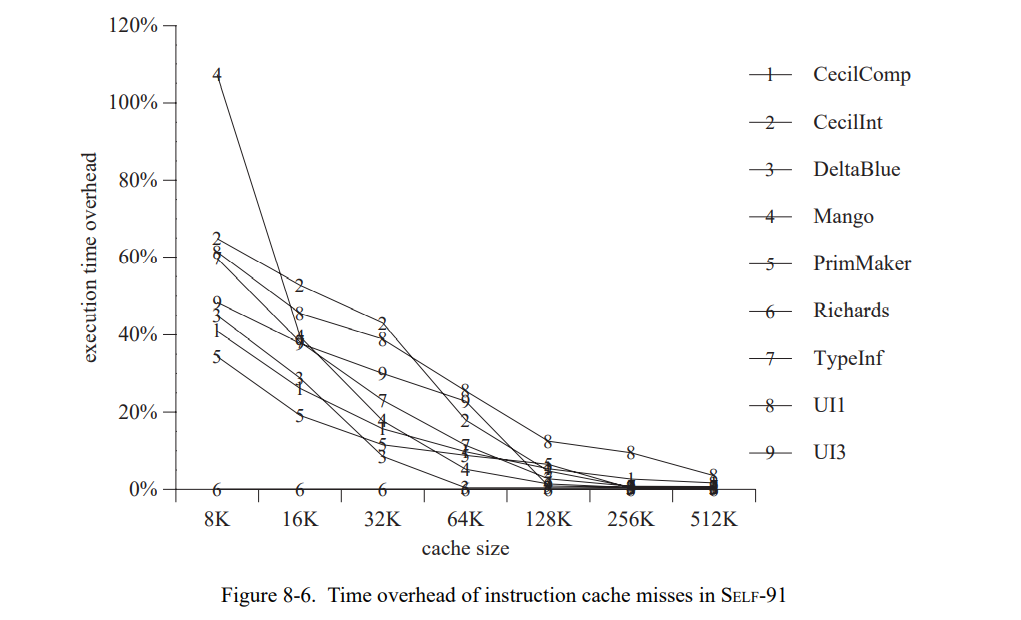
总结下,指令缓存失效在 SELF-93 上有重大的影响。对于我们基础的带有 32K 缓存系统,SELF-93 比带有无限大缓存的时候慢 40%。将缓存加倍到 64K 减少了一半的性能惩罚,而减少缓存一半大小会加倍惩罚。因此,比起寄存器窗口和标签指令的组合,指令缓存的大小对于SELF-93 的性能有巨大的影响。
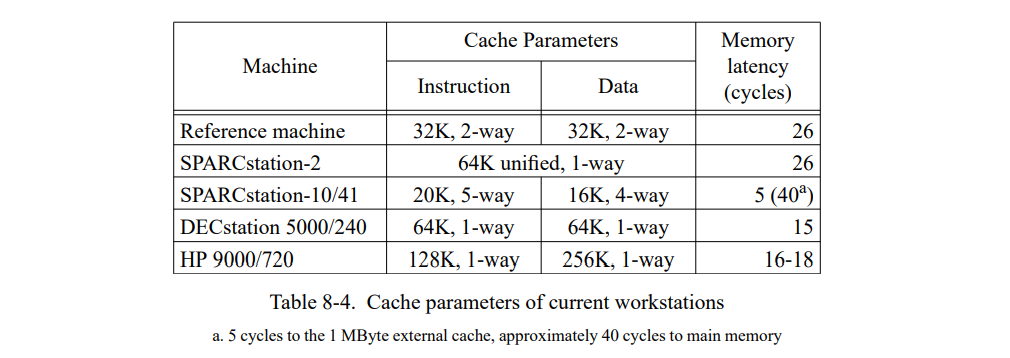
但是,我们应该强调的是,对于我们参考机器的缓存设计,大缓存的固有开销部分原因是保守参数导致的。特别是,主缓存的延迟是 26 周期,与 SPARCstation-2 的缓存相同,是当前工作站典型缓存的上边界(表 8-4)。但是,我们觉得保守的缓存参数对于预测未来的性能更有帮助,因为处理器(缓存)和主存间的速度差距预计在未来会扩大。其它研究已经表明科研上和商业负载上指令固有开销与 SELF 测量的开销相似。例如,Cvetaovic 和 Bhandarkar [38] 报告了运行在 DEC Alpha 系统上的一些 SPECint92 和 TCP 测试集上,指令缓存失效开销占总执行时间的 30-40%。
8.5 数据缓存行为
图 8-7 表明数据缓存的固有开销非常的小。对于 32K 数据缓存,一个无限缓存的中位数固有开销只有 6.6%。缓存大小翻倍通常会降低平均固有开销,大约是 1.5 倍。即使是一个 8K 的数据缓存,固有开销仍然比较合理,平均 12%。这是相当意外的,因为大部分的程序都分配了几 MB 数据。但是,我们的数据和 Diwan 等的是一致的,他们测量了分配密集的 ML 程序[48],然后为相同的缓存组织(写分配,子块替换)找到了非常低的数据固有开销。我们的数据也证实了 Reinhold[108] 的结论,他调查了大型 Lisp 程序的缓存性能。
Diwan 等也测量到他们的 ML 程序的数据缓存开销会随着使用写不分配策略大幅增加,即,缓存不会再写失败的时候分配缓存组。在 SELF-93 上也是这样的(见图 8-8)。对于 32K 缓存,写不分配增加了平均 1.6 倍的缓存开销,这个倍数会随着缓存变大而增加,当 512K 时达到了 2.1 倍。使用写不分配,写失败率令人震惊的,对于一个 32K 的缓存从 22% 到 70%(!),几乎没有随着大缓存下降(见图 8-9)。虽然我们的模型中没有写失败的相关开销,但是找到这些极端高的失败率是关注点,因为它们帮助解释了为什么写不分配对于如 SELF-93 这样的分配密集的系统是不好的缓存策略。
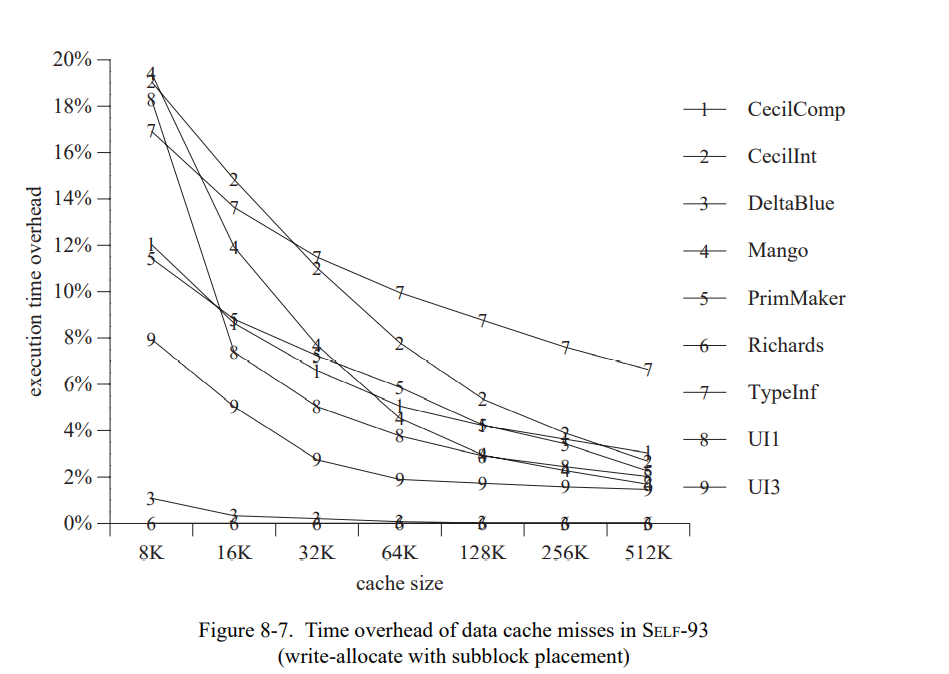
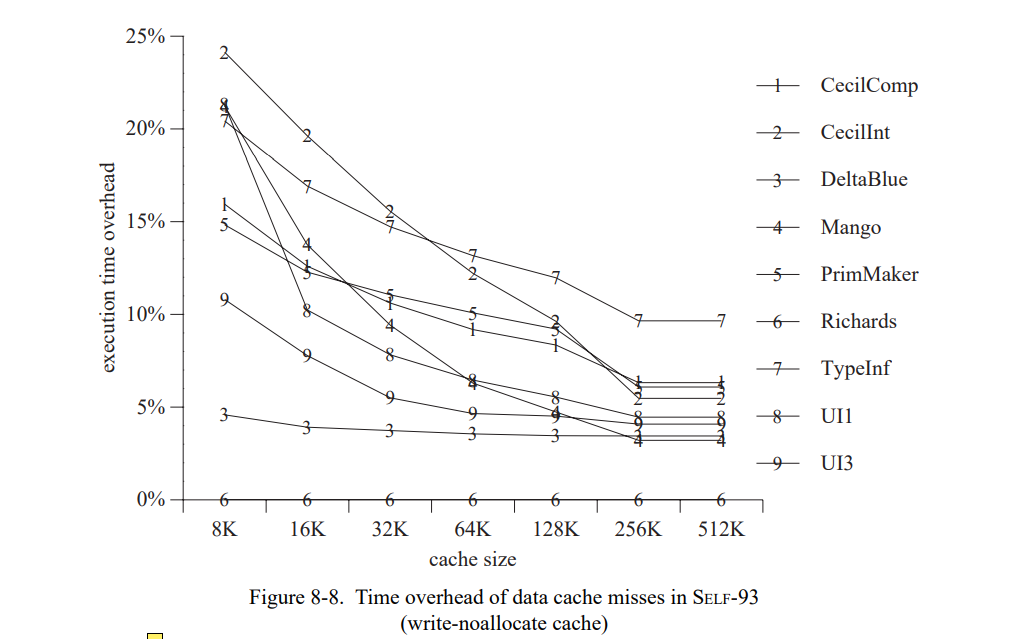
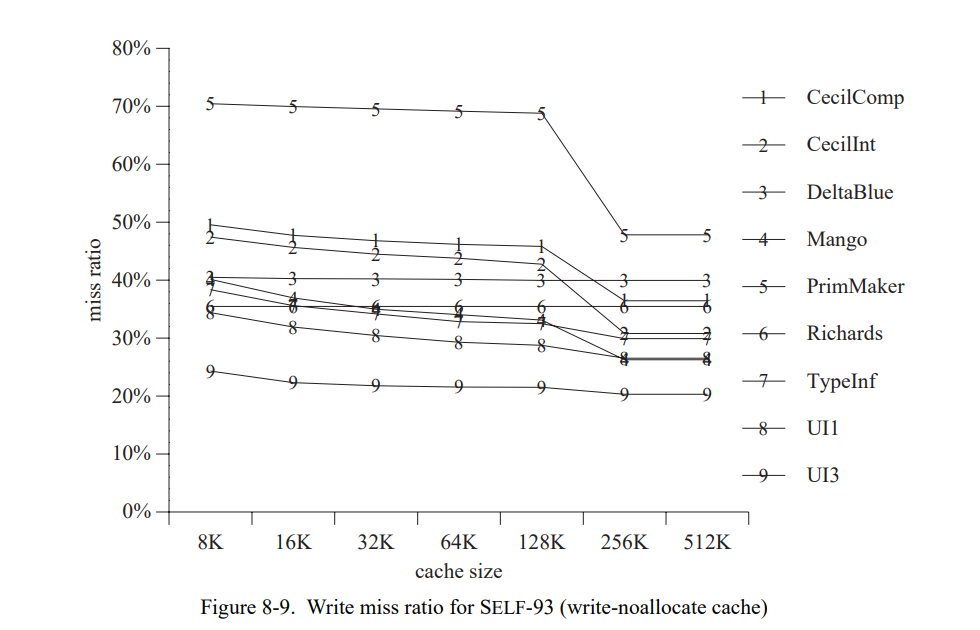
写失败率之所以那么高,是因为系统中对象分配的方式是通过一个拷贝分代垃圾回收做的(见图 8-10)。通常,这样的系统连续在“创建区”分配对象[131]。在每次清除后,创建区变为空。因此,所有的系统在分配一个对象时都不得不增加一个指针来标记有效空间的开始位置;如果一个指针指向的空间超出了创建区,一个清理会被发起,它会将所有的存活对象从创建区搬运到另一个内存空间。
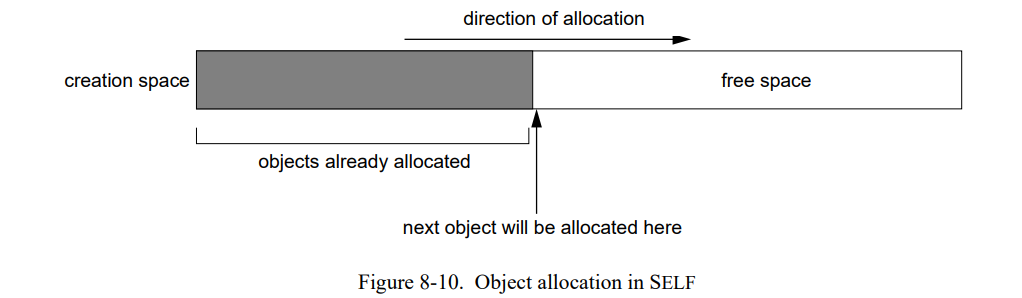
创建区比起最大的缓存都大–400K 字节 在 SELF 中。新分配的对象的内存位置几乎可以保证不在缓存中,因为分配器涉及到一个连续的 400 K字节的块,从最后一次对象被分配就在这个地址上。因此,存储初始化的对象在写不分配缓存里都将会缓存失效,因为对象的所有字在它们第一次读的时候已经被初始化了;第一次读的时候会导致一个额外的缓存失效,从而分配一个缓存组。
与之对应的是,写分配缓存会在第一次写失败的时候分配缓存组,因此后续所有的访问都会在缓存上。如果缓存使用了子块替换,缓存惩罚不会发生,因为当前新分配的组对应的内容不需要从内存中读(包含无效数据的子块被标记)。没有子块替换,内存中久的内容不需要被读,只要通过初始化存覆写就行。
Wilson 等人 [140] 争论这样的分配方式会将导致直接映射缓存有特别高的缓存开销,因为分配指针会扫过整个缓存,剔除每个单一缓存组。因此,缓存应该是关联的,创建区的大小应该比缓存大小来得小。为了验证这个假设,我们测量了 SELF-93 的一个版本,它使用了 50K 字节大小的创建区来确定缓存的影响。结果表明以如此小的创建空间运行 SELF 是不可取的:整个执行时间几乎增加了 1.5 倍,大部分是因为垃圾回收开销增加导致的。(一个 50 K字节 的创建区,扫描频率增加了八倍,但是代价没有下降八倍(每次扫描),因为根处理时间是一个常量;同时对象存活率增加了,因为扫描周期变短了。)
因此,我们的实验没有证实 Wilson 等人的基本假设。对于几乎所有的测试集和缓存大小,数据读取失败率比参考机上高得多。例如,从 64K 到 256K 的缓存,平均失败率翻倍。我们将这个增加归因于扫描导致的数据引用增加,因为扫描会污染程序缓存,当前我们没有数据证明这个假设。但是,它与一个事实一致,指令缓存失效率只有参考机的一半,即使是在我们没有改变任意的指令缓存参数。降低的指令缓存失败率是频繁扫描的结果–如果扫描经常发生,扫描器的指令会保持缓存常驻。同时,扫描器相当的小,因此比起整个系统有更好的缓存行为。
综上,尽管有高的分配率,SELF-93 上的数据缓存行为相当的好。因为大部分的数据访问都是到最近创建的对象,同时是按顺序分配的,许多访问命中了缓存。在 32K 字节下,平均数据缓存的开销小于 7%。
8.6 可能的提升点
根据我们的性能评估结果,有可以提升 SELF-93 性能的地方嘛?表 8-5 列出了 SELF-93 一系列提升点。
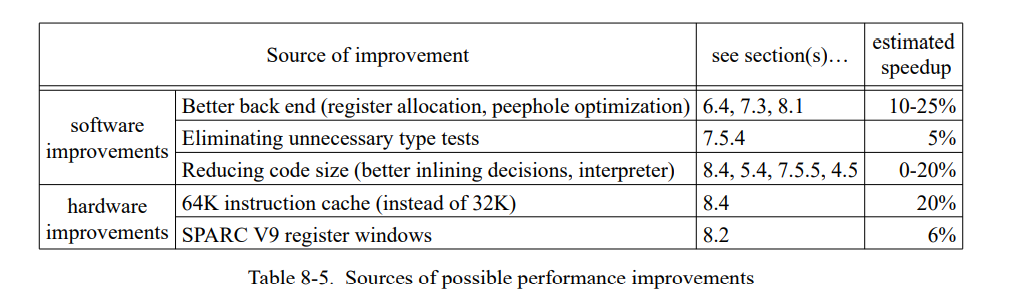
除了硬件改进带来的收益(最后两项),表中的加速点是基于测量开销和估算部分可以消除来大致估计的。两个主要的提升点是:
一个更好的后端加入了标准的,常见的优化。我们的估算是基于检查当前编译器生成的代码,和为其它语言带入编译器的优化的加速。基于未填充延迟槽的频率,特殊的寄存器移动,跳转链,在经过对生成代码一个简单的带入之后,我们估算下来已经带来了 5-10% 的加速提升。
但是,代价高昂的优化可能无法和交互系统适配,因为会增加许多编译暂停(见下一章)。
降低指令缓存失效。因为 SELF-93 使用了 32K 缓存,花费了 40% 的时间指令缓存失效上,降低这些失效可能会带来明显的性能收益。一个可以帮助降低代码大小的技术是做出更明智的内联决策的系统(类似于 Dean 和 Chambers 提出的[40]),进入计算的不只是内联候选的大小还有加速惩罚。这样的系统可能会降低代码大小,且不会明显的增加执行的指令数,因此整个的执行时间,因为缓存开销降低了。但是,我们没有足够的数据来判断这样的方式是否会成功。
合起来讲,加速估算揭示了 SELF-93 的速度在一定成本下是可以明显提高的,这个成本是更复杂的编译器和更慢的编译。当然,估算的加速不是累加的;例如,当软件技术成功的将代码大小减半,一个 64K 缓存只会带来 10% 的额外提升。尽管如此,软件技术的组合获得的加速收益会比较大,是未来研究有希望的领域。
8.7 结论
SELF-93 编译器降低了 SELF 纯消息传递的语言模型,变成类似于 SPEC‘89 整形测试集的指令使用方式的程序。在分解了相关本地代码生成器的效能之后(生成更多的非空操作和寄存器移动),最明显的不同是 SELF-93 的调用频率有两倍的高。但是基础块的大小非常的小。令人惊奇的是,通过 SELF-93 编译的程序与 SPEC’89 测试套件中的 C 程序差别很小,比起 C++ 程序。我们相信,当编译器也使用特定的 OO 优化的时候,C 和 C++(或其它面向对象的语言)的大部分差异也会消失。
SELF-93 的数据缓存行为即使是在小缓存的情况下也很好;在 32K 数据缓存和 26 周期内存延迟的情况下(一个相对高的延迟),比起一个无限快内存的理想系统,平均固有开销只有 6.6%。降低分配区的大小来适配缓存大小,不会提高性能,因为比较小的分配区,扫描会发生的比较频繁。指令缓存固有开销相对比较高,一个 32K 指令缓存平均固有开销是 40%。加倍(减半)缓存大小能大致将开销减半(加倍)。
其它的硬件特性对于性能没有太大的影响。寄存器窗口简化了编译器(可能会加速编译),但是它们不会提高 SPARCstation-2 的性能,窗口处理陷阱处理比较昂贵。当有一个廉价的窗口陷阱–即特别是在即将到来的 SPARC V9 实现–寄存器窗口将会提升 SELF-93 的性能,估算能有 8%。标签整数运算指令的性能提升甚至更小;比起能尽可能使用这指令的系统(这需要一个复杂的编译器后端),SELF-93 在没有这些特殊的指令的情况下只慢了 4%。
因为已编译的 SELF-93 代码类似于 C 代码,它能高效地运行在标准硬件上,这些硬件通常是为类 C 程序设计的。我们相信任何关于一个有利的架构特别是支持一个面向对象语言的论据都应该被谨慎对待,除非系统用于研究部署最新的优化技术,或者这些优化已经被证明为无效或者只对特定语言有效。
9. 响应能力
之前的章节在已编译代码方向上测试了 SELF 的性能。但是一个交互环境是用于快速原型的,原始的运行时性能只是一方面的性能。 另一方面是响应能力:系统可以多快反应编程的变化(即,一个程序员在输入之后可以多快尝试一块代码)?因为 SELF 使用运行时编译(解释执行会更慢),编译暂停影响了系统的交互。例如,第一次菜单弹出,画菜单的代码不得不进行编译。因此,在这个解决方案中运行时编译会导致一个明显的暂停。类似的,自适应重编译在后续运行中当要优化时也会引入暂停。这个章节探索编译暂停的严重性,会通过多方面的测量来进行,如编译速度,编译暂停的分布,和在一个实际交互过程的暂停过程。这个工作的一部分是 暂停聚类 的定义,一个新的表征暂停的方法会考虑到用户的暂停方式。此外,我们测量重编译系统的几个参数在性能变化和最后性能上的影响。
不像前面章节的测量,本章的性能数据不会从模拟器获得,因为许多的测量涉及到系统使用的交互。作为替代,我们测量一个空的带有 64M 字节的 SPARCstation-2 的 CPU 时间。由于第七章已经讨论过的缓存相关的性能影响,测量只可能精确到 10-15% 以内。
为了获得数据,我们运行一个带有仪表盘的 SELF 版本。独立的编译时间通过比较编译前后的 CPU 时间测量。9.4 节的数据通过 PC 采样获得,即,通过每秒中断程序 100 次,然后检查程序计数器来判断系统在中断时间里是在编译代码还是执行代码。这些采样的数据被写入日志文件。仪表盘大概降低了系统 10 % 的性能。
9.1 停顿聚类
这个章节的一个主要目的是通过测量编译暂停评价 SELF-93 的交互性能。但是编译暂停由哪些东西构成?尝试测量独立编译的期间;但是这样的测量会导致一个过于乐观的景象,因为编译往往发生在集群中。当两个编译接连的发生,它们作为一个暂停被用户感知,因此,应该被记为一个单一长暂停,而不是两个短暂停。这就是,即使单个暂停很短,当许多编译快速地交替发生,用户可能也会注意到暂停分布。因为当前目标是为了表征用户经验认为的暂停行为,“暂停”会按一种方式定义,即正确地处理时间上的不均匀分布停顿。
停顿聚类 尝试按一个以交互为中心的方式(生理上的)定义停顿。一个停顿聚类是满足下面三个标准的任意时间周期:
- 一个聚类开始于停顿,也结束于停顿。
- 停顿消耗了至少 50% 的聚类时间。因此,如果许多小的停顿发生在短的交替中,它们会被汇总到一个长的聚类,只要停顿在这个期间消耗了一半以上的 CPU 周期。我们相信 50% 的极限是保守的,因为系统仍然以一半的正常速度在运行,因为用户可能甚至无法观测到临时的减缓。
- 一个聚类包含的非停顿周期不超过 0.5 秒。如果两个可能会因为前两条规则合并的停顿组会因为超过半秒而分开,我们假设它们被感知为两个明显的停顿,因此不会将它们合并到一起。(对我们比较清楚的是两个事件分隔超过半秒会被区分。)
图 9-1 给出了一个例子。前四组停顿被聚集在一起,因为它们在时间周期里(规则2)使用了超过一半的总执行时间。类似的,下面三个短暂停被分成下个(长)停顿,形成超过一秒的长停顿。两个聚类不会融合成一个大的 2.5 秒的聚类(即使得到的聚类仍然满足规则 2,但它也没有在示例中),因为它们被一个超过 0.5 秒的无暂停周期分割(规则 3)。

这个停顿聚类的说明例子相当的保守,可能会高估了用户经验下的停顿。但是,我们相信比起测量独立的停顿,使用停顿聚类是更实际的方式。因此,我们希望这种方式会加强我们的结果,尽管是一个保守的方法,这个测量结果仍然是好的。我们也希望这个方式能启发到其它(例如,递增的垃圾回收),在表征暂停时间时会使用相似的方式。
图 9-2 表示测量编译停顿的停顿聚类的效果。图显示了在 SPARCstation-2 上超过一定长度的停顿的数量。在忽视停顿聚类后,我们可以报告 SELF-93 上只有 5% 的停顿超过了 10 ms,超过 0.1 秒的少于 2%。但是,加上停顿聚类后有 37% 的组合停顿超过了 0.1 秒。聚类停顿导致了一个数量级的不同。只报告独立的暂停会导致数据的扭曲。
当然,聚类停顿(CPU 百分比和组间时间)的参数值将会影响结果。例如,增加停顿百分比到 100% 会让结果更乐观。但是,这边呈现的结果相对于参数值的改变无关。特别是,停顿百分比的变化从 35% 到 70% 不会定性地改变结果,不会加倍组间时间到一秒。
9.2 编译暂停
这节测量发生在 SELF 使用接口的交互会话的停顿。除了特别提到的,所有的停顿测量使用停顿聚类。因此,“停顿”总是指 “聚类停顿。”
9.2.1 在交互会话间的停顿
我们测量一个 SELF 用户接口的 50 分钟的会话 [28] 中发生的停顿。这节涉及完成一个 SELF 教程,包括浏览,编辑,和做一个小的编程改变。在教程间,我们发现了一个复制黏贴代码的错误,所以这节也包含一些“真实生命周期”的定位分析。
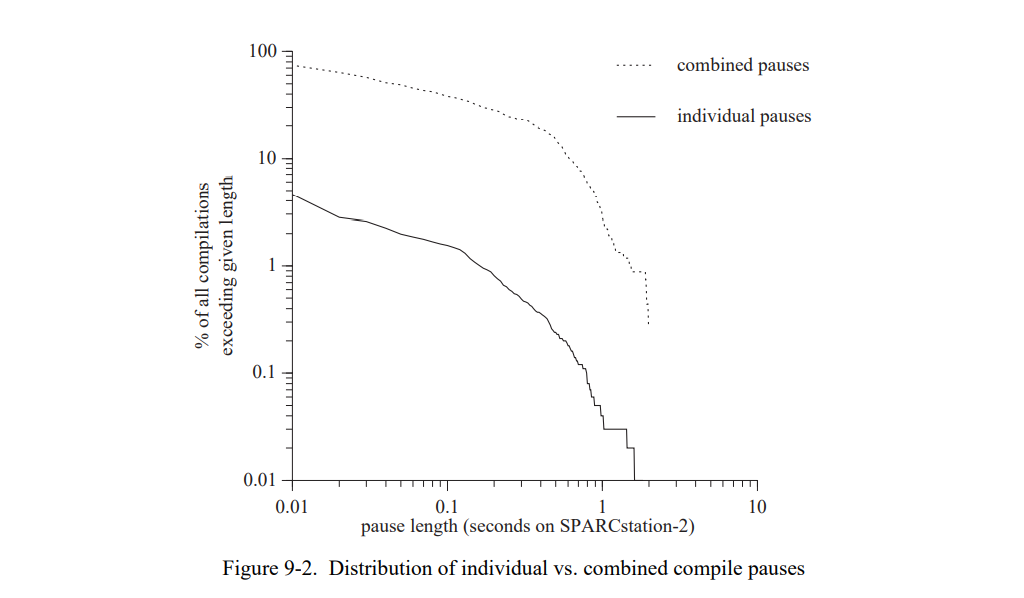
图 9-3 显示了实验期间编译暂停的分布。几乎三分之二的可测量停顿在十分之一秒以下。图 9-4 显示绝对时间里相同的数据;前两个框在 y = 50 的时候截断,从而可以在柱状图的剩余部分显示更多的细节。如果我们使用 200ms 作为可感知停顿的最低阈值,则只有 195 个停顿超过了这个阈值。类似的,如果我们使用一秒作为停顿分布的最低阈值,则在 50 分钟运行中,会有 21 个暂停。
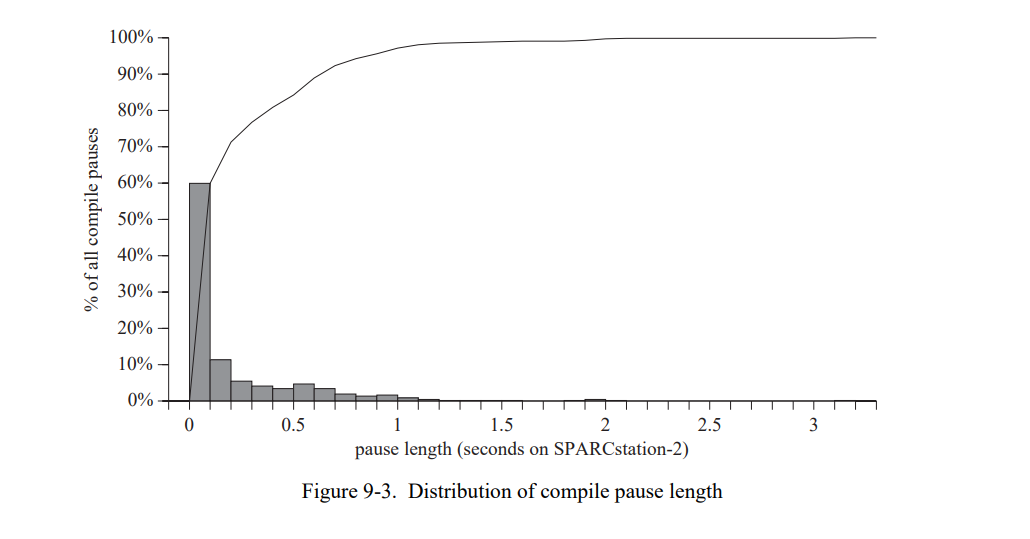
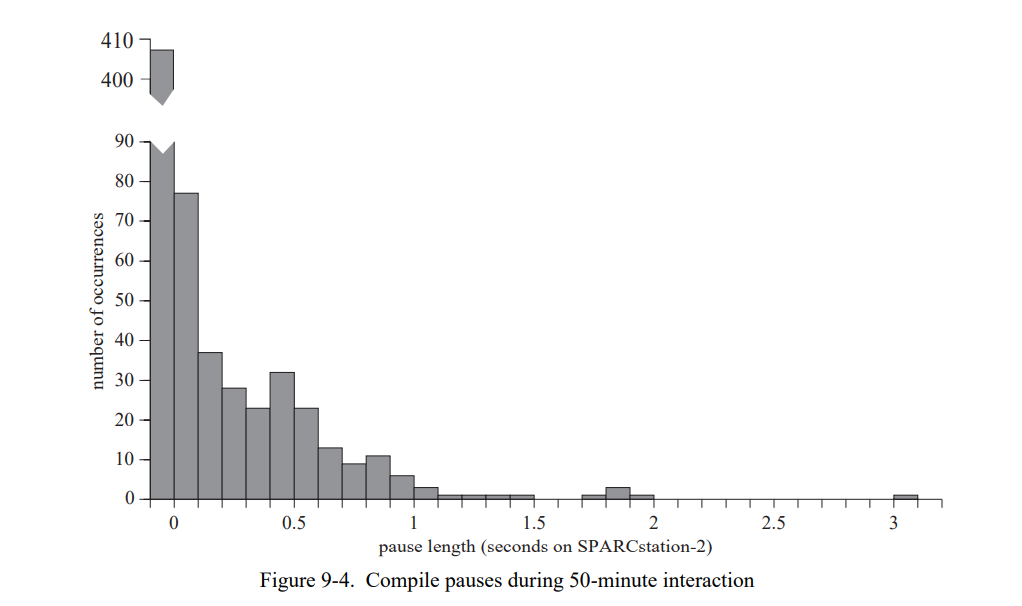
停顿聚类标记了编译停顿的短期聚集。但是,停顿不是均匀的分布在大的时间周期里的。图 9-5 (在 108 页)显示了如图 9-4 一样的停顿如何分布在整个 50 分钟的交互过程里。每个暂停是一个尖峰,它的高度表示(聚类)停顿长度;x 轴表示经过的时间。注意 x 轴的范围比 y 轴的范围大许多(有三个数量级),因此,图像通常夸大尖峰的高度和接近度。
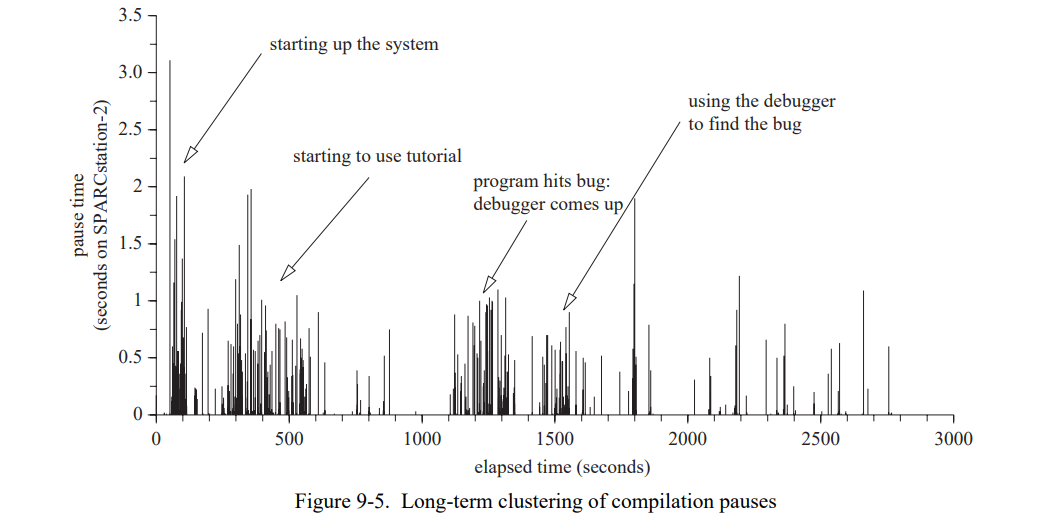
在运行时,几个重要的程序都是从 0 开始的(即,没有预编译代码)。这些工作集的每个改变都会导致编译的混乱,在图 9-5 表示为尖峰组。初始化组包括了最长的停顿,是由于启动用户交互界面导致的;下一组表示教程的第一阶段,这里大部分的用户交互代码都是第一时间执行。最后两组是在发现错误后调用调试器的,通过检查栈来找到错误的原因。
在 SPARCstation-2 上系统停顿行为似乎是足够的,特别是考虑到当今认为工作站是“低端的”(1994 年夏天)。虽然交互行为不如(非优化)Deutsch-Schiffman Smalltalk 编译器好,但是停顿比起传统的使用批处理方式编译的编程环境要小很多。
9.2.2 更快系统上的停顿
交互系统上的优化编译器的实用性是强依赖于 CPU 速度的。一个明显慢于 20-SPECInt92 SPARCstation-2 的系统会让停顿太分散注意力。因此,在 Deutsch-Schiffman Smalltalk 编译器已经开发了,我们的系统在常用的机器上就是不切实际的,因为它们至少慢了一个数量级。
另一方面,系统交互行为会因为更快的 CPUs 而得到提升。今天工作站和高端 PCs 已经明显快于我们测量使用的 SPARCstation-2(见表 9-1)。为了调研更快 CPUs 的效果,我们重新分析了我们的流程,通过选择代表当代工作站或者 PC (三倍快于 SPARCstation-2)以及未来工作站(十倍快)的参数。
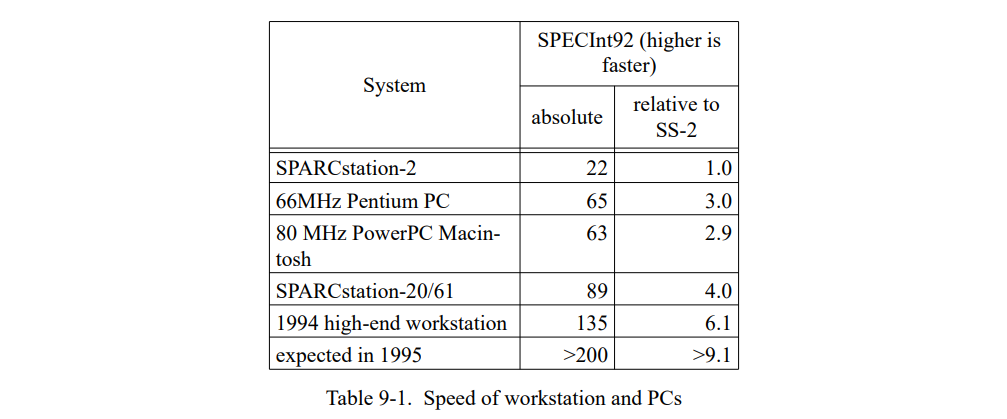
图 9-6 比较了 SPARCstation-2 和两个模拟系统上的停顿。对于每个停顿长度,该图显示了超过该停顿长度的停顿次数。注意对于更快的机器,该图不只是原始图像向左移动,因为它可能会结合编译,而慢的系统不会结合编译。例如,如果两组编译在 SPARCstation-2 相隔 1 秒,它们在 “当代” 工作站只相隔了 0.33 秒,所以会被合并成为单个停顿(见 9.1 节的规则)。但是,这个效果的整体影响是相当小的,这验证了我们早期的观察,停顿聚类相对不敏感于停顿间时间参数的值。
在当代的工作站上,只有 13 个停顿超过了 0.4 秒。这些数据验证了我们在当代 SPARCstation-10 机器上的非正式实验:停顿有些时候仍会引人注意,但它们很少分散注意力了。更快的下一代工作站将会消除几乎所有的让人注意的停顿:只有 4 个停顿会超过 0.2 秒。在相同的机器上,当前的 SELF 系统应该被认为是一个 “优化解释器。”(但是,停顿在实时动画或视频上仍然没有足够短,因为人类的眼睛在这些场景下可以识别出低于 0.1 秒的停顿的。)
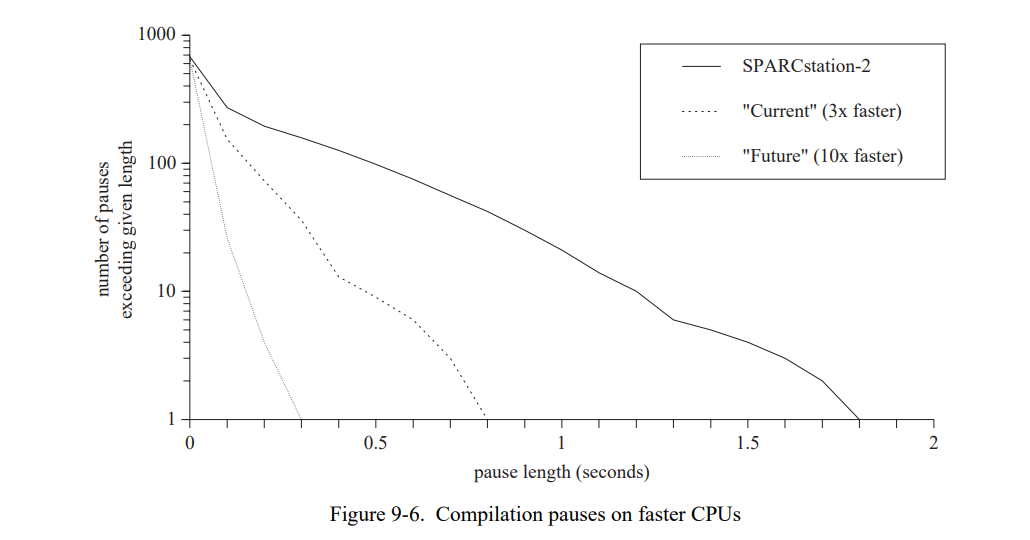
“在更快的机器上,任何东西都会更好” 的论据经常误导,特别是如果它们假设任何东西(如,问题大小或者程序大小)也保持常量。我们相信我们的论据跳出了这个谬论,因为独立编译的长度不依赖于程序大小或者程序输入,而是依赖于编译单元的大小,即,方法大小(还有在优化期间被内联进来的方法)。除非人们的编程风格改变了,不然方法的平均大小将会保持不变,因此独立停顿在更快的机器上会更短。因此,如上面已经注意到的,我们不会简单的通过加速因子除以停顿时间,但会重分析整个过程,通过正确的统计短的停顿间时间,然后将独立的短停顿合并成长停顿。更大型的程序会延长重编译需要的稳定时间(见下面的 9.4.1 节),但是我们的经验是程序大小不会影响到独立编译的聚合。换句话说,尽管大型的程序可能会导致更多的停顿,但它们不会加长停顿本身。因此,我们相信预测用户感知的系统的交互性会被更快的处理器提升是安全的,如图 9-6 显示的。
综上,我们可以认为 SELF-93 系统的编译停顿在前代系统上是可见的偶尔会分散注意力,在当代系统上有时候是可见的但几乎不会分散注意力,最终在下一代系统上是不可见的。当和自适应重编译结合,一个优化编译器确实可以和一个交互编程环境共存。
9.3 开始新代码
一个响应系统应该能够快速地开始新的(还没编译的)程序或者程序部分。例如,用户第一次将光标放在一个编辑上,相关的编辑代码就会被编译。开始没有预编译的代码类似于程序改变后的继续,因为这样的改变独立于前面的已编译代码。例如,程序员改变了一些关于弹出菜单的代码,然后尝试测试这些改变,相关的已编译代码需要首先生成。然后,通过测量没有预编译代码需要完成的最小程序部分(即,用户交互接口),这可以代表系统行为,即在一个典型的调试会话中,程序员改变源码然后测试改变的代码。
为了评价快速非优化编译器和慢速优化编译器的结合的收益,我们测量了普通用户交互的执行时间,如显示一个对象,或者打开一个编辑器。这是典型的长编译停顿会特别的分散注意力的工作。在序列的开始,系统开始于空的代码缓存。表 9-2 显示了序列独立的交互。对于测量,交互序列中执行的交互显示在表中,中间没有其它的活动,除了一些琐碎的事情,如将光标放在文本编辑器上。因此,序列开始于一个空的代码缓存,交互可能重用前一次交互已经编译的代码。交互 13 到 15 测量了系统可以多快的反应函数定义的改变,使用了重定义的整形加法方法的 “错误场景”。
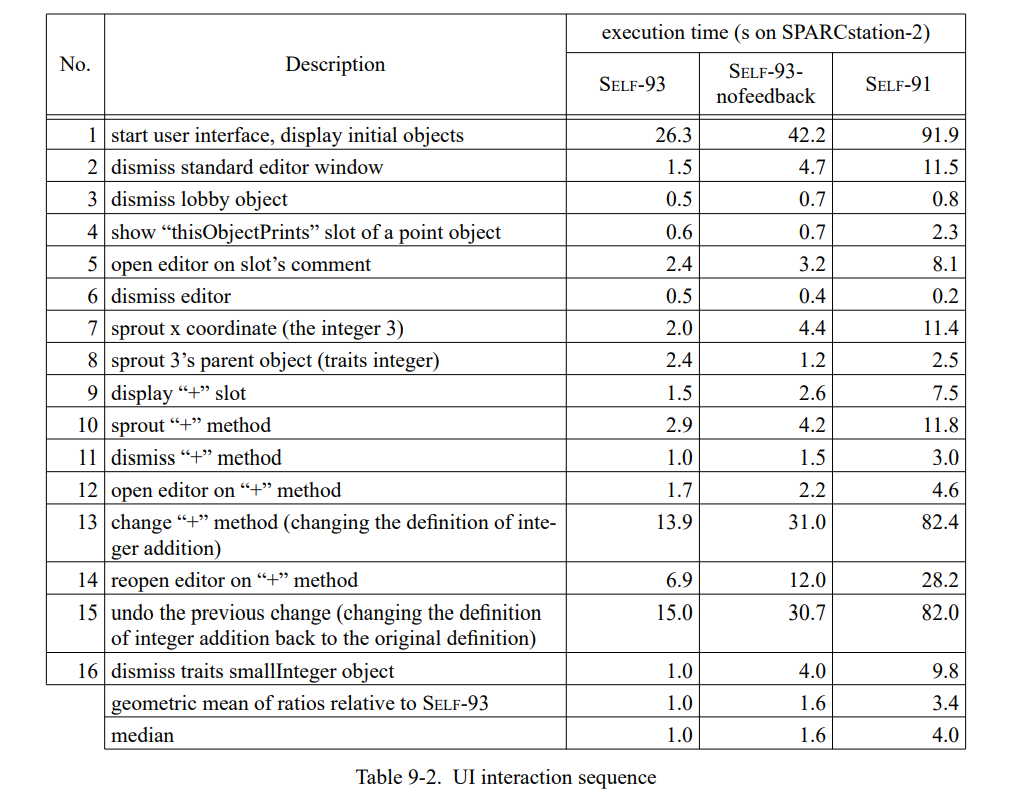
有几个点是值得注意的。首先,SELF-93 通常执行更快的交互方式;平均上,是 SELF-91 的 3.45 倍,是 SELF-93-nofeedback 的 1.6 倍(几何平均;中位数是 4.0 和 1.6)。但是,有些相对大的变化:一些测试运行得比 SELF-93 快(如,编号 16 分别是 9.6 和 3.6 倍快),但是少量的用例(如,编号 6)运行得比没有重编译的系统慢。自适应重编译在运行时引入了一定的变化,使得一些交互因为重编译变慢了。
几个因素促成了这些结果。SELF-93 通常更快,因为非优化编译器节约了编译时间。但是,动态重编译在运行时引入了一定的变化,减缓了一些交互。当重编译过于谨慎(因此太多的时间花费在未优化的代码上)或者它过于激进(一些方法被过早的重编译,不得不再次被编译),就会上面的情况。SELF-93-norecomp 快于 SELF-91,因为类型反馈允许它不影响已编译代码的性能时,设计得更简单。
13 到 15 行表明系统可以多快从大量改变中恢复:在两个例子中,大量已编译用户接口代码,在整形加法定义被改变后需要被重新生成。因为整形加法方法比较小且频繁被使用,它被许多的已编译方法内联,在改变后所有的这些已编译方法都要被丢弃。自适应系统允许系统在 15 秒以内恢复(前面67页表 7-1 提到的,用户接口大约由 15000 行代码组成,不包括通用系统如收集器,线性表等代码。)。这个时间包括了接收(解析)改变的方法,解除编辑,更新屏幕,下一次鼠标点击的反应。比起 SELF-93-norecomp,动态编译在这个例子中获得了 2 倍加速;比起 SELF-91,加速了 5 到 6 倍。当然,随后的交互也会因为这个改变变得比较慢,因为代码需要重新创建。例如,打开一个编辑器(14行)需要比改变前(12行)多花费四到六倍长的时间。
在自适应优化中,小段代码编译得更快,因此程序小的改变可以处理得更快。比起之前的 SELF 系统,SELF-93 有了明显的短停顿;平均上,上面的交互运行快了三到四倍。
9.4 性能变化
如果一个程序(或者程序的部分)重复的运行,它的性能会随时间变化。初始的,它会运行的比较慢,因为代码没有优化且由许多的编译和重编译发生。随着时间变化,性能会稳定在某个渐进值上。在这一节中我们调研我们的测试集程序的执行过程是如何随时间变化的,和不同的编译配置参数是如何影响这个行为的。
解决了三个问题:
- 性能是否稳定,程序在这方面有何不同?
- 配置参数怎样影响如何快速的性能稳定(即,性能曲线的坡)?
- 配置参数如何影响最后的性能(即,性能曲线的渐进)?
表 9-3 表示主要的配置参数和他们的功能。
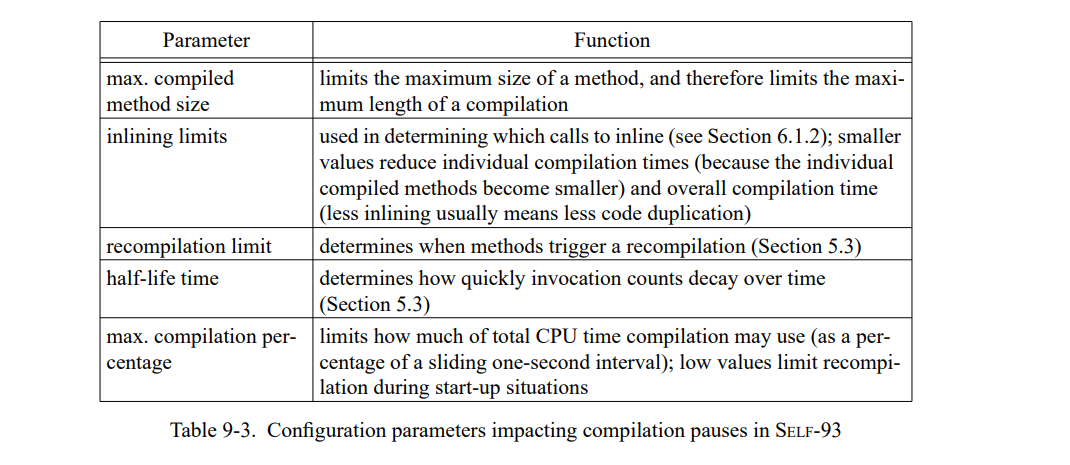
9.4.1 大程序的启动行为
前一节描述了(重)编译小段代码导致的停顿。本节调研了大程序从零编译会发生的事情。为了看看性能是如何随时间推移而变化的,每个测试集开始于空的代码缓存,然后重复执行 100 次。虽然测试集相对比较大,测试运行得比较短,优化代码大约两秒。因此,前几个运行取决于编译时间,因为大的代码体已经被编译和优化了(图 9-7)。例如,Typeinf 第一次运行花费了超过一分钟,然而第十次运行小于三秒。在几次运行之后,编译结束,大部分程序的执行时间变得稳定了,除了 UI1,它在运行 15 的时候有了另一个编译。但是,初始的尖峰是比较大的:典型的,第一次执行慢了第 100 次执行 20-50 倍。为什么会出现初始执行峰值?
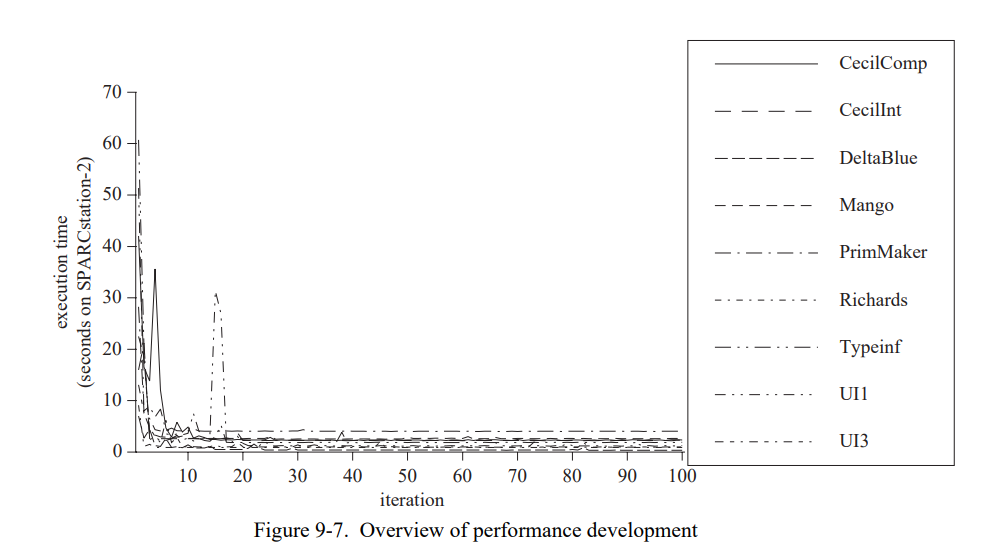
图 9-8 (114 页)将几个测试集的启动阶段分为编译和执行。UI1 的大部分初始执行时间消耗在非优化编译上,和慢速执行的非优化代码;在 UI1 上,优化编译时间从不决定执行时间。为了降低 UI1 的初始执行尖峰,非优化编译器不得不更快和生成更好的代码。与之相比,优化编译决定了 Typeinf 启动阶段,也(基本)决定了 CecilComp 的。CecilInt 位于中间–在优化编译是第一次运行的一小部分消耗,但是是第二次运行的主要消耗。总之,测试集之间高的初始执行时间的原因是不同的,没有单一的瓶颈。
程序启动时间应该与程序大小相关:一个预期是大程序需要更长来达到稳定的性能,因为更多的代码需要(重)编译。图 9-9 (115页)显示了测试集的 “稳定时间”,根据程序大小绘制。(稳定时间是指程序的编译时间发生到初始启动尖峰的“膝盖”。)如预期的,一些相关性是存在的:通常,大程序需要更长的时间启动。但是,相关性并不完美,它不能预期。例如,大程序花费更多的时间在小的循环上,将会更快达到好的性能,因为只需要小部分代码被优化。
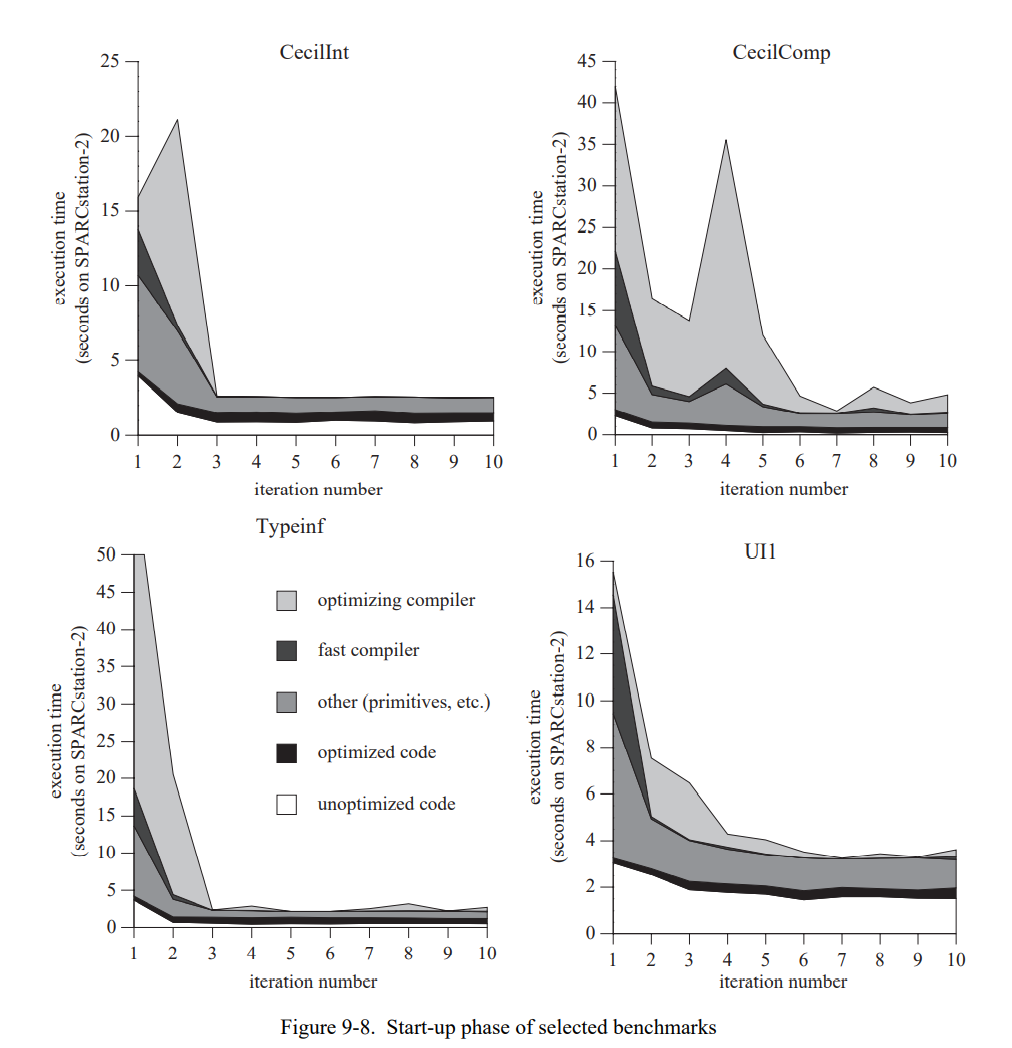
如果启动编译相关于程序大小,我们可以用上面的测量来表征系统的启动行为,它依赖于程序大小和执行时间(表 9-4)。如果程序是小的,启动时间也比较小,因此小程序的启动行为是好的。如果程序长时间运行,启动行为也会很好,因为初始编译被长执行时间隐藏了。但是,如果大程序只执行比较短的时间,当前的 SELF 系统不能隐藏动态编译导致的启动时间。我们的测试集都进入了这些分类里,因为它们选择的输入都是让执行时间更短,因此可以合理的方式来模拟它们。在实际环境里,预期程序会运行的更长,因此,启动行为会好于测试集的。
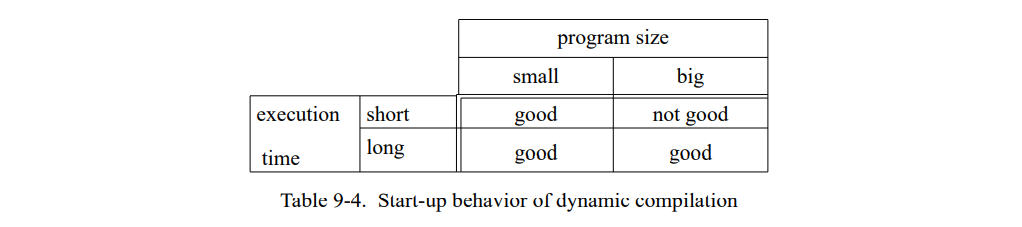
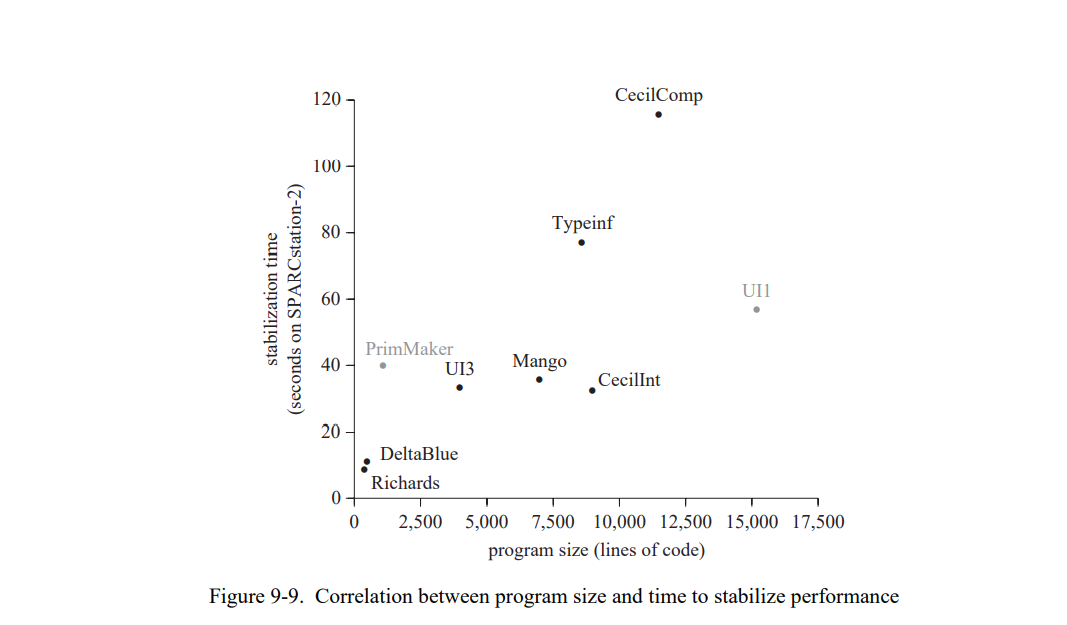
9.4.2 性能稳定性
即使在最初的大量编译之后,程序仍然会经历一些因为编译导致的性能变化。对于这节剩余的部分,我们会限定 Y 轴在 y = 10 秒,为了显示后续运行更多的性能细节。图 9-10 显示了运行在标准系统里的所有测试集用例的性能发展。在运行了 20 之后,所有的测试集在执行时间上基本没有变化,其中有许多在运行了 10 之后就收敛了。三个测试集收敛得特别的快,迅速地达到了稳定的级别,然后没有后续的变化。这个组由 Richards 和 DeltaBlue (两个最小的测试集), 以及 Mango 组成。因为它们在我们测量的所有配置中都表现得比较好,所以这些测试集在后续的图像中都被排除,从而降低视觉混乱。
剩余的测试集组在启动阶段之后,在执行时间上也有些尖峰(图 9-11),但是变化很小。几乎所有的场景,这些尖峰都跟重编译固有开销有关。在 10 个迭代之后,只有 UI1 和 CecilComp 还没有达到稳定性能;在 20 个迭代之后,所有的测试集基本都稳定了。剩余的尖峰相对小,大约只有一秒或者更少;例如,UI3 显示了三个大约一秒的尖峰,分别在迭代 20,45,和 73。
总体上,除了启动阶段,性能相对稳定。我们的图像倾向于夸大系统性能的易变性,因为独立的执行时间(即,单次运行用时)比较短,因此即使是一个小的绝对编译开销,也注册为明显的尖峰。图 9-12 显示测量间隔造成了多少不同;它呈现了同图 9-7 相同的数据但分组从五到一,模拟大测试集的效果。如果我们使用更长的测试集运行,没有异常的话,性能似乎非常的稳定,初始的下降也会呈现的比较小。但是,我们相信保持较小的独立测量间隔是正确的测量变化的方式,因为它反应了一个交互系统典型操作花费的时间。直观上,尖峰的 “视觉高度” 表明尖峰对于交互使用的影响程度:一个 0.1 秒的小尖峰几乎不引人注意,但一个两秒的尖峰就令人担忧了。
本章展示的测量过程不是完全可以重现的,因为每次运行确切的事件顺序总是变化的。例如,调用计算器衰变是通过一个进程实现的,每 4 个CPU秒会醒一次。因为时钟中断不能达到可重现,调用计数器的值(因此重编译决策)在每次运行时都不同。但是,不同运行的形状通常时相似的。对于本节的图像,我们重复每个测量五次,然后排序结果图,使用排在第三(中间)的图像。图 9-13 显示的是排序后最坏的情况,配置与图 9-11 相同。除了 UI1,两个图像非常的相似。但是,UI1 的行为很不同,有三个大的重编译发生在运行 30,50,和 75。(这些不同出现是一个极端的例子:当我们尝试调查造成差异的原因,我们无法重现行为。)
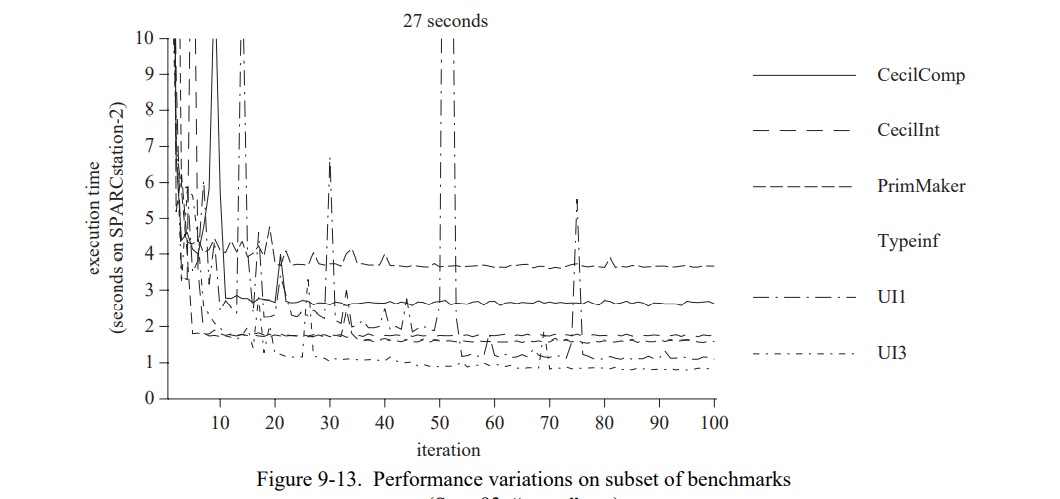
综上,大程序初始运行很慢,因为它们还没优化且花费更多时间在编译上。在启动阶段花费的编译时间大致和程序大小是成比例的。在两分钟后(在 SPARCstation-2上),所有的程序都达到稳定性能。
9.4.3 配置参数对性能变化的影响
当为我们的标准系统寻找好的配置时,我们实验了一个大范围的参数值。虽然我们无法建立一个硬规则(即,没有异常的规则)来预测参数变化的影响,我们找到了几个趋势:
- 调用计算衰减显著地降低了可变性,通过降低重编译的数量。半衰期影响了可变性:越接近无穷大(即,没有半衰期),执行时间变得越可变。没有半衰期,性能就不会达到真正稳定。
- 增加内联限制(导致更激进的内联)倾向于产生更高的尖峰,即长的重编译停顿。但是,效果不是很明显。
- 增加重编译的限制(即,重编译被触发的调用计数值)会加长启动阶段,因为更多的时间被花费在未优化的代码上。它并不总是降低性能变化。
- 降低重编译的 CPU 有效时间的百分比倾向于延长启动阶段,会稍微压平初始峰值。
计数器衰变对稳定性的影响最大;而且衰变和不衰变之间的差异是巨大的。图 9-14 显示了如同图 9-11 相同系统的变化性,除了半衰期不是15秒,而是无限大。所有的程序明显有了更高的变化。同时,这几个函数似乎没有收敛到一个稳定的性能级别上,即使是 100 次迭代后也没有。直观上,这些行为的原因是清晰的:没有衰变调用计数,每个单方法最终都会超过重编译的阈值,因而被优化。因此,只有在很少方法被重编译的情况下性能才会稳定。
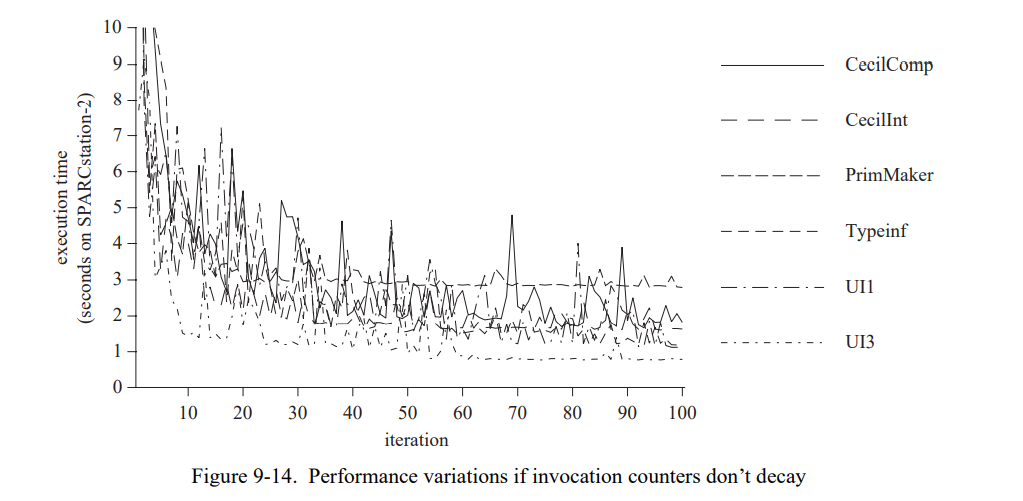
9.4.4 配置参数在最终性能上的影响
配置参数在最终性能上的影响是相当清晰的:通常下面的改变会提高性能:
- 提高内联限制(在合理范围里),
- 降低调用限制,同时
- 降低衰变参数(让它靠近 1.0)。
为了测量最后两个因素的影响,我们调整调用限制和半衰期时间,然后测量对应的执行时间。对于每个参数组合,我们从测试集 100 次重复里选择最好的执行时间,然后将这个时间归一化为测试集的最好时间。也就是说,对于特定测试集产生最好性能的参数配置获得 100% 的值。因此,对于另一个参数组合,一个 150% 的值将意味着这个组合会比最好的参数组合执行时间长 1.5 倍。在 SPARCstation-2 测量时间。
图 9-15 显示性能测试的结果概况,所有测试集的平均(数据被限制在 200%;最坏参数组合的真实值超过了 1100%)。整体上,两个参数的行为符合预期的:增加调用限制值和降低半衰期,都增加了执行时间,因为这会导致更少的方法被重编译,则应用中更少的部分被优化到。但是,性能概况“起伏不定,”表明性能不是同单个参数变化而单调变化。起伏一部分是测量误差的结果(之前说过在 SPARCstation-2 上缓存效果导致的变化会达到 15%),一部分也是使用基于时间衰变引入的随机性元素的结果。后一个效果在“坏”参数组合时特别强(短半衰期,高调用限制)。图 9-16 显示了 CecilComp 的性能概况,是我们测到的“最起伏”的中的一个;它在半衰期或者高调用限制值方面表现出强烈的变化。因为控制半衰期例程的计时器中断在程序执行过程中并不总是在确定的相同点上到来,一个循环可能在一个运行中被优化(如,在 4 秒的半衰期里),但在另一个运行中没有优化(在 8 秒的半衰期里),因为计数器在可以触发一个重编译前总是定时衰减的。这个解释与起伏不能准确重现的事实是一致的(即,现象被重现了,但精确的位置和起伏高度不能重现)。
综上,重编译的参数在可预测的方式上影响着性能;通常,降低调用限制值和增加计数器半衰期可以提高性能。在一定的参数值范围里,性能曲线相对平滑,运行系统在交互响应和性能之间达成一个最佳折衷方案。
9.5 编译速度
这节测量了交互性能相关的最后一方面,原始编译时间。图 9-17 和 9-18 显示了 SELF-93-nofeedback 和 SELF-91 编译器的编译速度与每个编译处理的字节码总数的函数(一个字节码对应一个源代码词)。数据点表示在测试集一次运行中发生的所有编译。例如,一个在 300 ms 里处理的总共 400 字节码(包括所有的内联方法的字节码)的编译会被表示为一个点,对应的坐标是 x = 400 ,y = 300。
对于两个编译器,在已测量的字节码数量来看,编译时间接近于源大小的线性函数,SELF-93-no-feedback 的相关性系数是 0.98,SELF-91 的是 0.96。因为两个编译器的编译速度都是源长度的线性函数(带有微不足道的启动固有开销),相应的编译速度可以被表示为单个数值。平均上,SELF-93-nofeedback 每字节花费了 1.1ms,SELF-91 花费了 2.6 ms;换句话说,SELF-93-nofeedback 编译快了大约 2.5 倍。更快的编译可以归因于更简单的编译器前端(不需要执行类型分析),和简单的后端。因此,除了消除更多的消息发送,类型反馈也加速了编译。比起第四章描述的非优化编译器,SELF-93-nofeedback 大约字节慢了 5-6 倍(见25页的图 4-2 的详细信息)。


如 114 页的图 9-8,一些程序的启动阶段被优化编译支配者,因此,希望进一步提高编译器速度。图 9-19 显示了 SELF-93-nofeedback 在编译上的时间分布是如何的。几乎有 60% 花费在前端,这个时间超过一半是执行消息查找和做内联决策。大部分的查找时间可以被查找缓存消除,即,一个缓存映射查找关键字到槽描述器上。这样的缓存还没有被实现,因为当前的消息查找执行了两个功能:它们寻找目标槽,然后记录这组槽和查找结果依赖的对象。后者在源码改变后需要无效化已编译代码。每个已编译方法包含了一个依赖组,其包含了在编译期间所有查找执行的查找依赖集的并集。无论何时一个对象改变,所有的包含这个对象的方法都会被丢弃。一个查找缓存不得不存储依赖集和查找结果,然后会需要一个依赖系统的重组织。
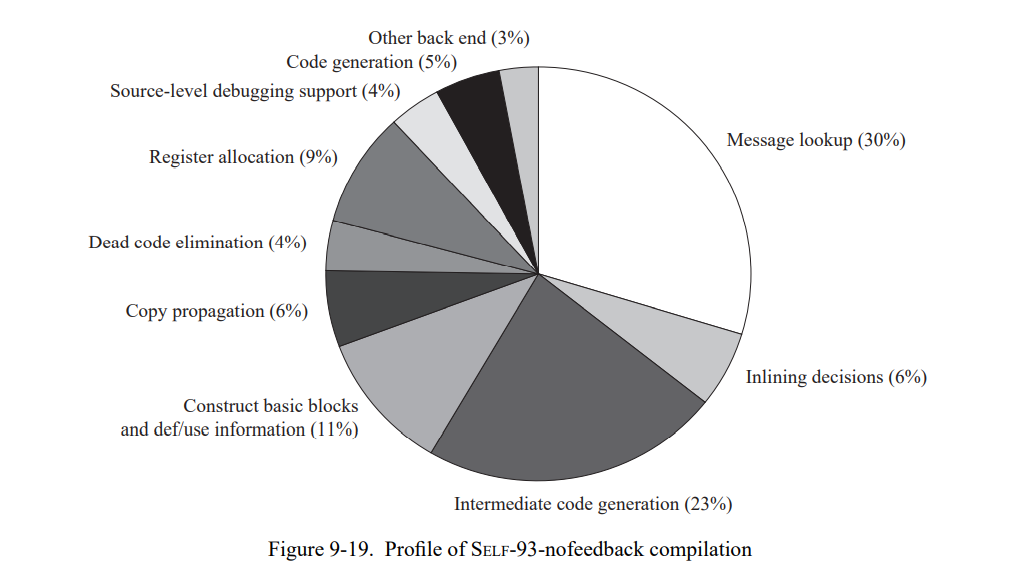
有了查找缓存,编译器将大约能快三分之一,然后后端将会开始支配编译时间,即使它没有执行太多的优化。虽然编译器可能因为使用了某些标准的编程技巧而加速,但更显著的提升需要基础的设计改变。一个主要的低效来源是编译器不得不执行许多的通用操作,这些操作被重复了许多次。例如,编译器不得不内联一个方法里的每个 if 控制结构的一些消息发送,创建许多的中间节点和伪寄存器。最终,大部分节点都被优化掉,但是也会消耗宝贵的编译时间。一个可能的降低编译时间的方式是部分评估通过消息发送的编译像 ifTrue:或者 +。如果这些消息可以生成预优化中间码模板,许多的编译效果就可以被避免。不幸地是,实现这样的模板涉及几个不平凡的问题,如怎样参数化模板,以及如何独立于它们嵌入(例如,一个方法实现了 for 循环的优化重度依赖于类型已知(整形)和参数的值(整数或者负数))来优化它们。
9.6 总结
当讨论到停顿时间,至关重要的是测量停顿,因为它们会被用户感知到。我们定义了一个停顿指标,停顿聚类。停顿聚类会将连续短停顿合并为一个长的停顿,而不是将它们作为独立的停顿统计。将停顿聚类为 SELF-93 系统的编译停顿改变了停顿分布的数量级,强调了停顿聚类的重要性。无论停顿长度是否重要,我们认为停顿聚类都应该被使用,例如,在评估增量的垃圾回收器可以用。
类似于其它语言,面向对象语言需要好的运行时性能以及好的交互性能。纯的面向对象语言认为这个任务很难,因为它们需要激进的优化来获得可接受的运行速度,因而会对交互性能妥协。当带有自适应重编译,系统可以同时提供好的运行时性能和好的交互性能,即使是一个纯的如 SELF 的面向对象的语言。即使是在前代工作站如 SPARCstation-2 上,在一次 50 min 的迭代中,超过 200ms 的停顿少于 200 个,且只有 21 个停顿超过 1 秒。当有更快的 CPUs,编译停顿开始变得不受关注的:在当代的工作站上,只有 13 个停顿超过 400ms,在下一代工作站上(可能在 1995 年可用),没有停顿超过 400ms,只有四个停顿超过 200 ms。
除了加速程序的执行,类型反馈也加速了编译。因为类型反馈允许编译器变得更简单,独立的编译会变得更短,且编译速度增加;比起 SELF-91,优化的 SELF-93-nofeedback 编译器编译每个源代码单元快了 2.5 倍。平均上重编译进一步降低了每个编译停顿,因为大部分编译是由更快的,非优化的编译器执行的,只花费了几毫秒。
自适应重编译也帮助提高了系统对于程序改变的响应能力。例如,在 SPARCstation-2 上,当整形加法方法重定义激进改变之后(会无效掉所有内联了整形方法的已编译代码),SELF 用户界面再次响应用户事件花费了少于 15 秒的时间。比起 SELF-91 系统(没有使用自适应重编译),SELF-93 在这个场景下提高了 6 倍的响应速度。
大程序如果在启动时没有预编译的代码,则初始运行非常的慢。达到稳定性能的时间与源代码程度密切相关:程序越长,初始启动阶段越长。通常,重编译模块安定非常的快;在 SPARCstation-2 上运行大约 45 秒后只有两个测试集没有达到稳定性能。在最糟糕的例子中(大测试集却只执行较短的时间),当前的系统不能隐藏初始动态编译的固有开销;但是,如果大程序执行足够长(如,一分钟),相关的固有开销会被压缩。系统可以保留预编译的代码到磁盘中,然后按需加载来降低启动固有开销。因此,虽然在程序开发阶段,在做出较大改变时,停顿仍然比较明显,但是它们在“产品模式”下不会成为问题,因为有预编译代码可以使用。
将来,甚至可以做到比当前 SELF-93 系统更好的隐藏编译停顿。当有了动态自适应编译,从优化的代码不是立刻需要的来看优化变成是“可选的”。因此,如果系统确定某个方法需要被优化,在需要的时候实际的优化编译可以被延迟。例如,系统可以将优化请求放入队列中,然后在用户“思考阶段”处理它们(类似于垃圾回收投机[138])。或者,在一个多核机器上,优化编译可以与程序执行并行工作。
随着硬件速度的提高,解释器或者非优化动态编译器(如同当前 Smalltalk 系统中使用的)可能不在是性能和响应能力间的最佳折中方案。今天,推动更好的性能是可行的–因此,扩大系统的应用能力–不影响响应能力。自适应重编译利用当代硬件的速度来协调运行时性能和编译时响应。我们希望这个工作可以鼓励面向对象语言在设计方面探索这个新的领域,达成面向对象语言新的高性能探索性编程语言环境。
10. 调试优化代码
SELF 纯的基于消息的计算模型需要昂贵的优化来达成好的性能。但是一个交互编程环境也需要快速的反应时间,和完成源码级别的调试。尽管进行了优化,但仅仅提供正确的语义执行时不够的:为了最佳的程序员生产力,系统应该提供直接执行程序员源码的错觉。换句话说,系统应该在已编译代码速度下提供解释器语义,将期望行为与全局优化结合[144] 。
大部分已经存在的系统不支持调试优化过的代码。程序只能为了全速进行优化,或者为了源码级调试编译不进行优化。最近,一个争取让调试优化代码的技术已经被开发了[65,143,37]。但是这些系统没有可以提供全源码级别的调试。例如,通常不能获得所有源码级变量的值,以及单步执行程序,或者改变变量的值。优化优先于调试,所以这些系统只提供了严格的方式来调试。
相比之下,我们不想对源码级调试妥协:为了最大化程序员的生产力,系统必须提供总是提供全源码级的调试。因此,我们选择限制一些优化来保护调试,然后让受到调试影响的性能尽可能的小。不幸的是,如果程序源码级的形态可以在程序的任意点被恢复,即,在几乎所有的指令边界上(为了支持单步调试),已经存在的技术严重的限制了可以执行的优化,有效地禁用了许多通用优化。
我们通过放松在优化代码上的调试要求来解决这个困境。比起需要在程序中每个点都能调试,已优化的代码只需要能恢复相对较少的点的状态(本质上,非内联调用)。对于程序员,这个限制是不可见的,因为如果需要提供细粒度的调试,代码会被退优化。如果程序完全没有优化,则总是可以被检查或者单步执行。据我们所知,这一节我们描述的系统是第一个在存在许多全局优化的情况下,提供期望行为的特定系统;比起之前的技术,我们使用动态退优化和中断点来使得我们可以在一些能执行的优化上有比较小的限制的同时获得期望的行为。
10.1 优化 vs 调试
全局优化执行的代码转换让在源码级上调试优化过的代码变得比较难。因为优化会删除,改变,或重排部分源程序,对于尝试调试优化过的程序的用户,它变得可见了。这节呈现了一些必须要解决的问题,才能提供优化过代码源码级别上的调试能力。
10.1.1 显示调用栈
一些优化如内联,寄存器分配,常量折叠,和拷贝传播使得方法的活动记录不能直接反映源码级别的活动。例如,一个简单的物理栈帧可能包含几个源码级活动,因为消息发送被内联了。变量在不同的时间位于不同的位置,同时一些变量可能没有运行时位置。
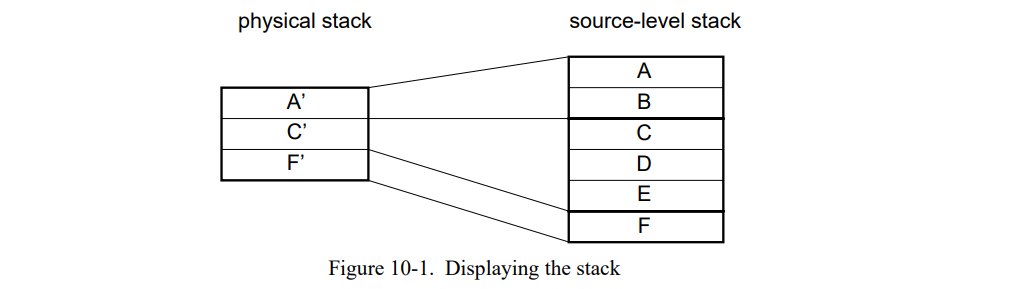
在图 10-1 中的例子显示了内联的效果。物理栈包含了三个活动A‘,C’,和 F’。与之相比,源码级的栈包含了额外的活动,这些被编译器内联了。例如,活动 B 被内联到 A’,所以 B 不出现在物理栈踪迹上。
10.1.2 单步
为了单步调试,调试器必须找到和执行属于下一个源码操作的机器指令。一些优化如代码移动或者指令调度,让它变成一个难题:一条语句的指令可能会穿插着其它相邻语句的指令,以及语句可能会重排从而不会按源码顺序执行。与之相比,在未优化的代码上单步调试是简单的,因为语句的代码是连续的。
10.1.3 改变变量值
考虑下面的代码段:

因为表达式 i + j 是编译时常量,编译器会在生成的代码中消除它的计算。但是,如果程序在给 k 赋值前暂停,并且程序员将 j 改为 10 会怎样?优化代码的执行不能被恢复,因为它会为 k 产生一个不是预期的值。当然,在未优化的代码上,他们是没有问题的,因为加法仍然被已编译的代码执行。
10.1.4 改变过程
当一个内联进程在调试时改变了,也会有类似的问题出现。假设程序刚好在执行函数 f 的内联拷贝时暂停,此时程序员改变了 f 因为找到了一个错误。显然,执行不能简单的继续,因为 f 的老定义是硬写入调用者的。在另一方面,未优化代码可以简单的提供期望的行为:f 的定义可以简单的替换,后续调用到 f 的代码能执行正确的代码。
10.2 退优化
这些问题都不会出现在未优化的代码上。如果优化代码可以按需转为未优化的,程序可以在大部分时间里全速运行的同时,能够简单的进行调试。SELF 的调试系统就是基于这个转换的。已编译的代码存在下面两个状态:
- 优化代码只能在相对宽的中断点暂停。在每个中断点,源码级的状态可以重构。
- 未优化的代码可以在任意源码级的操作上停顿,因此支持所有调试操作(如单步)。
10.2.1 节 解释了用于从已优化的程序状态中恢复源码级状态的数据结构。10.2.2 和 10.2.3 描述了已优化代码如何按需转为未优化代码的,然后 10.2.4 节讨论了中断点如何减少调试对于优化的影响。
10.2.1 恢复未优化代码
为了显示源码级的栈踪迹和执行退优化,系统需要从已优化机器级状态重构回源码级状态。为了支持这个重构,SELF 编译器为已编译方法包含的每个范围生成 范围描述 [23] ,即,每个初始源方法和所有它内联的方法。一个范围描述指定了范围在物理栈帧的虚调用树上的位置,然后记录这个位置或者它参数的值和位置(见图 10-2)。编译器也描述已编译方法里每个子表达式的位置和值。这些信息是用于重建评估表达式的栈的,这些表达式等待被后面的消息发送消耗。

为了找到物理程序计数器的正确范围,调试器需要知道虚拟计数器(源码位置),即,范围里的一对范围描述器和源位置。因此,每个方法生成的调试信息也包含了物理和虚拟程序计数器的映射。
在这些信息的帮助下,调试器可以对用户隐藏一些功能的效果,如内联,拆分,寄存器分配,常量传播,常量折叠。例如,当编译器消除一个变量,因为它是编译时常量时,变量描述器将会包含这个常量。这个描述器的直接扩展可以用于处理变量,其值可以从其它值计算得到(如消除归纳变量)。
图 10-3 显示一个方法在两个不同时间停顿。当一个方法停在时间 t1 上,物理 PC 是 28,对应的源码位置是方法 B 的第五行。因此一个栈踪迹会显示 B 被 A 调用,隐藏了 B 通过编译器被 A 内联了的事实。相似的,在时间点 t2 上,源码视图上会显示 D 被 C 调用,C 被 A 调用,显示了三个栈帧,而不是一个。为了显示完整的栈踪迹,这个进程在每个物理栈帧上都是简单的重复。
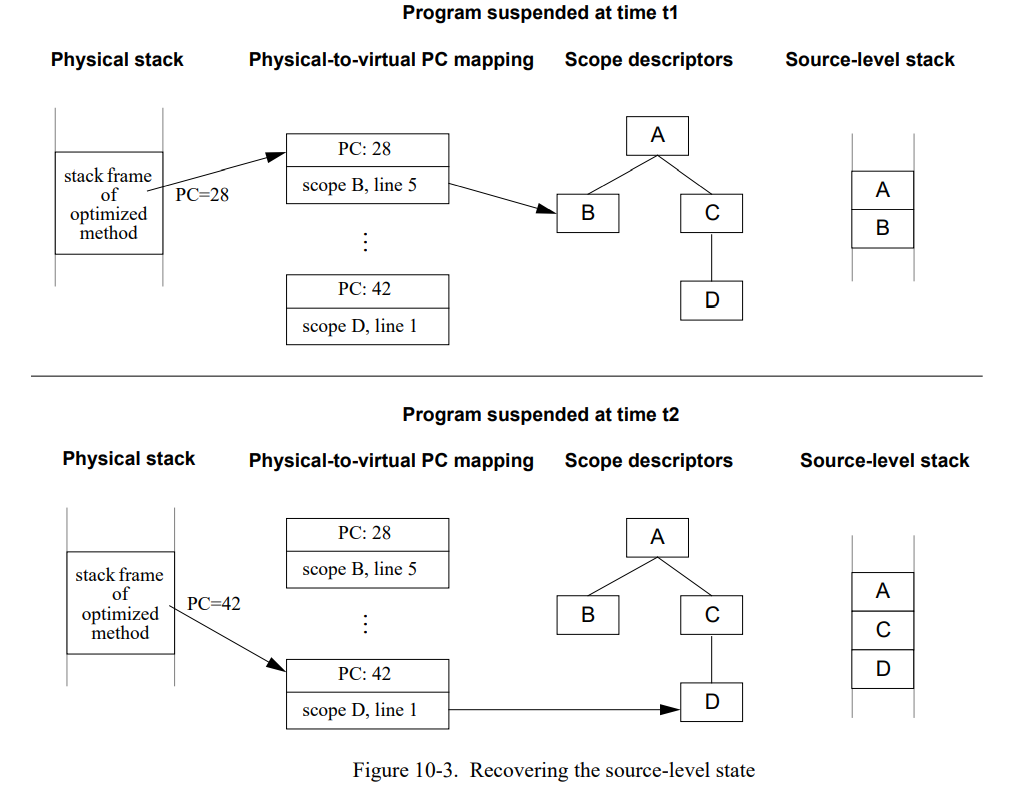
10.2.2 转换函数
无论何时需要调试,系统都会转换一个优化过的方法为一个或多个相等的未优化方法。为了这个时刻,我们假设只有最上层的栈活动需要被转换,因此栈帧可以简单的移除或添加;10.2.3 节解释了怎样移除这个限制。然后,退优化转换可以按如下步骤执行:
- 保存需要被转换的物理活动中的上下文(栈帧),从运行栈上移除。
- 使用上节描述的机制,决定物理活动中包含的源码级(虚拟)的活动,以及它们局部变量的值,和虚拟PC。
- 对于每个虚拟活动,创建一个新的已编译方法和一个相关的物理活动。为了简化转换函数和后续的调试活动,新的方法(目标方法)完全没有优化:一个调用相关所有的消息发送,都没有执行如常量折叠或通用子表达式消除等优化。
- 对于每个虚拟活动,在相关已编译方法上找到新的物理 PC。因为目标函数是未优化的,对于每个虚拟 PC 都有一个确定的物理 PC。(当目标方法已经被优化后就不是必要的。)前一步创建的栈帧初始化填充了返回 PC 和其它运行时系统需要的域,如帧指针。
- 对于每个虚拟活动,从优化活动拷贝所有参数,局部变量,表达式栈项的值到未优化的活动。因为未优化方法是从源方法一条一条的直接转换过来的,在目标活动中所有的变量都会映射到对应位置,所有的拷贝值都有明确的目的地。(当目标方法已经被优化后就不是必要的。)因此,由于目标方法没有优化,它不包含任何需要初始化的隐藏状态(如通用子表达式的值)。因此,结合第 4 步,新的栈帧对于所有的虚拟活动都是完全初始化的,转换也完成了。
图 10-4 说明了这个过程。转化扩展了一个包含三个虚拟活动的已优化栈帧为一组三个未优化栈帧,因此,创建了虚拟帧和物理帧间的一一映射。
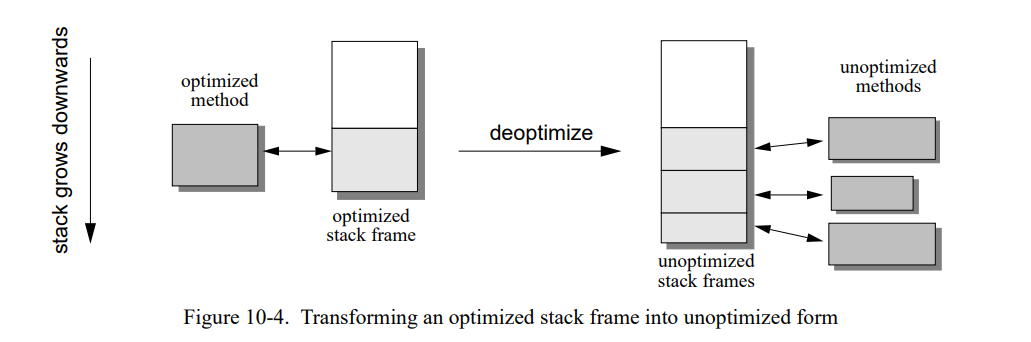
只有那些正在调试(单步)的程序部分需要被转换。这些程序部分将会运行非优化代码;其它部分会全速运行。如 10.2.1 节描述的,不需要转换就可以检查程序状态。
10.2.3 延迟退优化
但是当一个栈帧在栈的中间时,这时新的栈帧不能简单的插入,要如何退优化?为了解决这个问题,我们当前的实现总是延迟转化栈帧:退优化被延迟直到控制被返回到帧上(见图 10-5)。例如,在栈帧中间的被内联到帧 f 的虚拟活动 vf2 要退优化,f 不是立即退优化。而是,g 的返回地址(被 f 调用的栈帧)会被改为指向一个例程,这个例程会在 g 返回时转换 f。在那个点上,f 就是最上层的帧然后被退优化。只转换最近的活动简化转化进程,因为没有其它栈帧需要调整,即使退优化导致了栈帧大小增加了。
退优化可以大大简化系统,但是也可能会限制调试调试功能,除非采取额外的步骤。当前 SELF 系统不允许局部变量的内容在调试期间改变,因为一个变量可能没有运行时位置。除了为了变量创建一个运行时位置,可能还需要转化栈中间的活动,这是当前系统无法做到的。但是,这不是基础的问题;例如,已转化的栈帧可以用堆分配的方式[44]。甚至一个更简单的方式是为每个已消除的变量分配栈位置。这些位置在程序正常执行时可能没有用,但是在程序员手动改变已消除变量的值时就可能用到。因为已编译代码依赖于老(或者说恒定)值,当程序员改变了方法源码时它就会变成无效(见 10.3 节)。
10.2.4 中断点
如果优化过的程序可以在任意的指令边界中断,调试优化代码会变得很难,因为源码级的状态将不得不在程序的任意点上恢复。为了放宽这个对优化强加的限制,一个优化过的 SELF 程序只能在某些中断点中断,这些点的状态可以保证始终如一的。任何发生在两个中断点间的异步事件通知被延迟到下一个中断点到达。当前,SELF 系统定义了两类中断点:方法导言(包括一些进程控制原语)以及循环体的结尾(“回边”)。这个定义暗示了最大的中断延迟是由包含调用或者循环结束的最长代码序列决定的,通常只有数十条指令。因为延迟非常短,中断点的使用没有被程序员注意到。(如果只有发送时中断点,没有调用的循环被中断。)如果循环包含一个没有调用的执行路径,回边只需要检查中断;否则,每个循环迭代至少执行一个调用,因此检测过中断了。
中断点需要覆盖一个程序所有可能覆盖的点;这就是说,它们也需要处理同步事件如算术溢出。在 SELF 中,所有可能的运行时异常都是中断点,因为所有的原语都是安全的:如果请求操作不能被执行,原语调用一个用户定义的异常处理程序,通常是调用调试器。
一旦一个优化过的程序暂停,如果需要执行调试请求,当前的活动会被退优化。在一个非优化方法中,每个源点都是中断点,因此程序可以在任意点上暂停。
因为调试器只可以在中断点调用,只需要在这些点上生成调试信息。这个优化降低了调试信息使用的空间,但更重要的是允许在中断点间做大部分优化。本质上,编译器可以执行任意的优化,其不会影响到一个中断点或者在这样的点上不做。例如,编译器可以重用一个死变量的寄存器,只要在变量的范围里后续没有中断点。中断点间距越宽,源代码级调试对优化施加的限制就越少。
中断点也减少了垃圾回收对编译器优化的影响。垃圾回收可以只发生在中断点,然后编译器可以在中断点间生成暂时违反垃圾回收需要的不变量的代码[31]。
10.3 更新活动方法
在调试过程中,程序员可能不只是改变一个变量的值,也会改变一个方法的定义。为了无效化被这些改变影响的已编译代码,SELF 系统在已编译代码和表示源方法函数的对象间维护了一个依赖链 [23]。例如,一个包含改变了的内联拷贝方法的已编译方法,已编译方法会被丢弃。
但是,如果一个已编译方法,其含有被改变了的方法的内联拷贝,是活跃的(即,由至少一个活跃),它不能被简单的抛弃。相反,已编译方法必须在执行前可以连续的被新的已编译方法替换。幸运地是,退优化可以用于此目的。在活跃的已编译方法被退优化后,它将不在包含任意的内联方法。当它继续执行,后续调用到这个改变了的方法将会正确的调用新的定义。
如果改变的方法是当前活跃的,更新这个活跃是比较难的。幸运地是,在 SELF 中不用解决这个问题,因为在 SELF 的语言模型中,活跃是通过拷贝方法对象创建的。一旦创建,将与源相互独立,所以源的改变对于克隆不影响。
延迟转换优雅地解决了无效方法在栈中间的问题:我们简单地等无效方法到达栈顶,然后转换它。延迟转换在交互系统中是可取的,因为它会随着时间推移分散修复工作,避免分散注意力的停顿。因此,它可以很好的处理改变序列,例如,读取包含一组相关对象新的定义的文件。在激进的转换下,每个新的定义会导致所有受影响的已编译方法重编译,许多方法都会重编译几次,因为它们可能会被几个改变所影响到。在延迟转换下,这些已编译的方法将会被重复地无效(因为无效时很廉价的,所以没啥问题),但是只会转换一次。
综上,在我们的调试机制下,支持改变运行时程序几乎是微不足道的。我们当前的实现是在由几百行 C++ 代码和之前的说过的调试功能以及维护依赖的代码组成。
10.4 通用调试操作
这节讲述 SELF系统中实现的调试操作,强调可能的额外实现。有了退优化,能相对简单的实现通用调试操作,如 single-step 和 finish ,因为这些操作能简单的在未优化代码上执行,退优化可以按需的为每个程序段供应未优化代码。相比之下,前代系统通常没有为已优化代码调试提供 single-step 或者 finish [144,37]。
10.4.1 单步
因为退优化方法中每一个源点都关联着一个中断点,单步实现变得很简单。系统退优化当前活动,然后设置好中断标志后重启进程。进程会放弃控制直到到达下个中断点,即,在单步执行后。
10.4.2 完成
完成操作让程序继续执行直到选择的活动返回。通过改变已选择活动栈帧的返回地址到一个特殊的例程来实现,这个例程在活动返回时会暂停执行。因此,程序在完成 操作执行期间不会减慢,因为它可以运行已优化的代码。
如果选择的活动没有自己的物理栈帧(因为它被内联到另一个方法),它的栈帧通过延迟退优化来退优化。在这个例子中,程序仍然可以在大部分时间里运行已优化代码;只有在最后(当延迟退优化执行)才运行未优化的代码。
10.4.3 下步
下步 操作(也叫“跳过”)不进入调用而是执行到下一个源操作。也就是说,程序会在下一个源操作完成后暂停。下步 可以通过执行单步 合成,可能随后有完成(如果操作是调用)。最后,我们的系统中,单步 通过几行 SELF 代码实现。
10.4.4 断点和观察点
当前 SELF 通过源转换支持断点:程序员通过在源方法中简单的插入一个 halt 的发送来插入一个断点(halt 显式调用调试器)。为了实现不需要程序员显式修改的断点,调试器会透明地执行源转换。
观察点(”当变量的值改变时停止“)也容易实现,因为 SELF 时纯的面向对象语言,所有的访问通过消息发送执行(至少时理论上的;编译器通常会优化掉这些发送)。为了管理一个对象实例的变量 X 的所有访问,我们可以重命名变量为 private_x 然后加入两个新的方法 x 和 x: ,管理会分别地访问和赋值,然后返回或改变 private_x。(记住 SELF 的基于原型的模型允许我们改变单个对象而不影响其它的,因此我们可以轻松监控特定对象。)依赖系统会无效所有内联了 x 或 x:旧定义的代码(即,直接访问或改变 x)。
比起要求程序员显式做出这些改变,系统可以透明地执行它们来支持断点和观察点。在通用的场景里,一些代码需要重编译才能容纳新的中断点,但是这个系统不需要任意额外的基础机制来支持这个功能。
10.5 讨论
在这节中,我们讨论我们方案的优缺点和评估它的通用性。
10.5.1 益处
我们的调试技术有几个重要的优点。首先,它是简单的:转换进程当前的实现由少于 400 行 C++ 代码组成,基于 10.2.1 节描述调试信息实现。第二,它允许和编译器松耦合–都不需要直到双方太多东西。第三,它没有添加超出第二章描述的优化的限制,这些优化是编译器可以执行的。因此,许多通用的优化如内联,循环展开,通用子表达式消除,和指令调度都可以用在中断间,不会影响调试性。最后,我们的方法很好的适配了交互系统,因为它是递增的:通常,最多一个栈帧需要转换为用户要求的结果。
10.5.2 当前限制
在调试间使用未优化代码,当用户决定连续执行时,会引入了性能问题。执行应该全速的,但是一些栈帧可能没有优化。然而,这个问题通常不是很严重的,只有少数的帧运行未优化代码,在帧返回后未优化代码将立即丢弃。系统的其它部分都会全速运行。包含循环的方法仍然提出了一个问题,因为它们可以无限期的以未优化的形式留在磁盘上。但是,这样的帧会自动重编译,使用第五张描述的重编译系统的优化。
某些优化导致的问题我们的系统无法解决。因为它必须提供全源码级的调试,而 SELF 编译器不会执行这样的优化。通常是,死的存储不能被消除,以及死的变量的寄存器在没有先溢出变量到内存的时候不能被重用。相似的,如果调试器的恢复技术没有强大到在一个或多个中断点隐藏优化影响,则其它的一些优化(如,代码移动或归纳不变量消除)有时候也不能执行。
10.5.3 概论
这里提出的调试方式不只是针对 SELF,也可以用到其它语言。我们的系统似乎需要运行时编译来进行退优化,但是没有运行时编译的系统在需要时可以在可执行文件中包含每个过程未优化的拷贝或者动态链接它们。
对于指针安全的语言如 Lisp,Smalltalk,或者 C++指针安全的子集,我们的方案似乎可以直接应用。我们无法估算源码级调试在其它系统上的影响,因为它依赖于特定语言,编译器和中断点恢复值的技术等特性。但是,通常,一个使用中断点和退优化的系统比起其它提供全源码级调试的系统应该更快,因为退优化允许已优化代码只支持中断点所有逻辑要求的一个子集。在 C 等允许指针错误的指针不安全语言里,中断点的距离可能会更近,因为调试器可能会在每个存取点调用,因为编译器无法证明这些点不会发生地址错误。但是,即使由于不安全存取导致的中断点确实非常频繁,我们的方案仍然允许和其它源码级调试一样多的优化。
如果指向堆栈的指针的位置未知,则在去优化期间需要特别关注这些指针。在这种场景下,一个可能是引用栈变量的指针的地址可能不会被改变。但是,可能可以用一些昂贵的栈空间来解决这个问题,通过将优化的和未优化的栈帧布局成一致的。
10.6 实现开销
在存在优化编译器的情况下提供全源码级调试并不是无开销的。在这节中,我们测试我们的技术对于响应性能,运行时性能,和内存使用的影响。
10.6.1 对响应能力的影响
退优化过程和中断点使用对于用户都是不可感知的。在 SPARCstation-2 里编译器通常在 1ms 里创建一个未优化的方法,因此动态退优化引入的停顿时微不足道的。中断点对于用户和系统中断只增加了几毫秒,因为一个中断点在运行时已经设置好中断标志之后通常只要几十条指令就能到达。综上,在 SELF 系统中提供全源码级编译不会降低它的响应能力。
10.6.2 对运行时性能的影响
理想情况下,可以通过完全关闭全源码级调试然后重新测试系统性能来获得它的性能影响。但是,这是不可能的,因为源码级调试是 SELF 系统的基础设计目标。如果要获得更好的性能,禁用调试支持需要对编译器和运行时系统进行大规模重新设计。此外,垃圾回收器已经对优化器施加了一些限制,诸如活跃的寄存器不能包含派生指针(指向对象中间)等要求。被垃圾回收限制的优化与调试要求限制的非常相似,如死代码消除和一些通用子表达式消除的形式[31]。因此,从全源码级调试要求影响中分离出垃圾回收的影响是很困难的。当我们无法测量我们调试方案的全部性能影响时,检查生成的代码表明没有明显的与调试相关的低效。
但是,我们已经测量了一些 SELF 系统中源码级调试的影响。为了确定调试器可见名称的影响,SELF-91 改成了死变量会释放寄存器分配,即使它们在中断点是可见的。改变编译器带来的性能提升对于全程序范围里不是很显著[21](小于 2%)。也就是说,通过延长变量生命周期来支持调试,对于我们的系统几乎无影响。(对于这个,一个可能的原因是 SELF 的方法通常是比较短的,因此,很少有变量在其明显的范围里是没有用的。)
当前系统通过测试一个特殊寄存器来识别中断;在 SPARC 上每个任务花费两个周期。这个轮询会降低典型程序 4% 的性能;一些带有小循环的计算型程序会降低多大 13%[21]。更多的编译运行时系统使用条件陷阱,其固有开销可以降低到每个检查一个周期,然后循环展开可以减少小循环的问题。因此,系统可以使用非轮询的方案,这时中断处理程序可以分派当前执行中的例程,从而在下个中断点可以进行进程切换。
综上,SELF-93 系统上的源码级调试的明确的性能影响难以确定。但是,基于上面的数据点,我们相信源码级调试对于通常的程序性能降低 10%最多。
10.6.3 内存使用
表 10-1 表明已编译方法各个部分的内存使用与机器指令使用的空间的相对关系。例如,垃圾回收需要的重定位信息大约是实际代码大小的 17% 。数据是依次运行所有测试集程序获得,代表了 3.3 M 字节编译器生成的数据。因为未优化和已优化方法有不同的特性,只有优化编译的数据显示在第二列。因此,第一列表示的是实践中实际使用配置的数据分布,而,第二列数据表明纯已编译代码的特性。
空间消耗可以划分未三类。第一类包含方法头和机器指令;同时,还有实际方法执行需要的所有信息。第二类,包含在程序改变后使已编译代码失效需要的依赖链接(见 10.3)。第三类,包含所有调试相关的信息:范围描述、PC 映射(见 10.2.1 节)和垃圾回收的重定位信息(为了更新包含在调试信息中的对象指针)。这些包含了重编译需要的所有信息,但不包含源码本身。
调试信息消耗的空间随优化程度变化。已优化方法表现出了比起未优化方法相对更高的空间固有开销,因为内联方法的调试信息通常大于内联扩展的代码。因此,调试信息会随着已编译代码更激进内联而快速增长。
调试的总空间固有开销是合理的。在标准系统里,调试信息小于指令本身的一半大小;在会优化任意东西的系统里,固有开销是 76%。换句话说,添加调试信息会增加空间使用量(除了依赖)在 1.5 到 1.8 倍左右。
为了保守,我们留了方法头的使用空间,即使它们在没有调试时也可能在系统中被使用到。(头包含了查找关键字和各种控制信息。)如果我们包含了头,调试增加的使用空间大概 1.3 到 1.7 倍。
支持修改运行中程序的代价时比较小的;依赖信息占据指令大小的 0.45 到 0.55 倍。(由于当前依赖的表示有着明显的冗余,其它的替代实现可能可以明显降低空间使用)。
作个粗略的比较,当编译 SELF 虚拟机时,GNU C++ (使用 GNU 特定的 pragmas)生成一个 11.3 M 字节的可执行文件,其中代码段 2.0 M 字节。因此,C++ 调试信息比实际的大了 5.7 倍,而当前的 SELF 系统即使包含了支持程序改变和垃圾回收的总开销也小于 2.5 倍。虽然这种比较应该要细粒度的,但是它也表明了,尽管功能性增加了,用于支持源码级调试的数据结构的空间固有开销可能没有高于其它系统。
10.7 相关工作
Deutsch 和 Schiffman [44] 描述的 Smalltalk-80 系统最早提出使用动态编译和中断点。为了隐藏编译成本地代码的效果,已编译的方法包含了一个已编译方法到源码位置的映射。为了运行效率,活动正常创建在栈上,但是按需转换为语言需要的全成熟活跃对象,当执行需要时再转换回去。在我们的系统中,中断被延迟到下一个调用或者回边分支。因为编译器执行没有全局优化,系统可以提供预期行为而不用退优化。
Zurawski 和 Johnson [146] 描述了一个非常类似于我们的调试器模型(与这项工作同时开发),使用了“检查点”和动态退优化为已优化代码提供期望的行为。但是,系统没有使用延迟转换。因此,它们的检查点的定义允许异步事件,如它们的中断会被任意延迟。他们的一些想法在 Typed Smalltalk 编译器上实现了[79],但是系统显然只能运行一些非常小的程序,因而无法在实际中使用,不像我们的系统可以在日常中使用。
其它大部分调试已优化代码的工作与我们是正交的,因为他们解决的是程序中给定点的源码级值恢复问题。与之相比,我们的工作解决的是在哪里恢复源码级值的问题,而不是它们如何恢复。因此,使用中断点和退优化放大了用于恢复源码级值的收益。下面讨论的大部分技术都可以与我们的工作结合来支持更多的优化。
Hennessy [65] 解决的是,当存在已选的局部和全局代码被重排序优化时,如何恢复变量的值的问题。他的算法可以识别当一个变量有不正确值时(在源码程序上),可以在某些时候重建源码级的值。Hennessy 使用停顿点类似于中断点:调试器只在停顿点调用,即,在语句开始的地方。代码序列被严格限制,所以没有存储完成,除非整个语句能运行完成。因此,如果在语句执行期间发生异常,调试器可以显示程序的状态,就像程序是停在语句开头一样。
Adl-Tabatabai 等人 [2,3] 调查了在指令调度存在的情况下如何识别和恢复源码级变量值的问题。其它的恢复机制由 Coutant 等人[37] 以及 Schlaeppi 和 Warren [114] 描述。
Zellweger [143,144] 描述了 Cedar 的一个交互源码级调试器能在大部分场景下有期望的行为,Cedar 有两个优化,过程内联和跨跳跃。虽然她的技术总是可以恢复源码级变量值,但是它们不能隐藏某些代码位置问题;例如,如果编译器执行了 Zellweger 没有考虑到的优化,如指令调度或死代码消除,则单步调试已优化代码会很困难。因为 SELF 系统可以切换为未优化的代码,可以避免这个问题。
LOIPE [52] 出于调试目的使用透明的增量重编译。例如,当用户在某些过程设置断点,这些过程会转为未优化的形式让调试更简单。但是,LOIPE 无法在活跃过程中执行这样的优化。因此,如果程序停在一个已优化的过程里,它通常不能被设置断点或者单步执行。为了缓解这个问题,用户可以指定优化的执行数量(可能影响调试能力)以及透明调试需要的数量(可能影响代码质量)。据我们所知,LOIPE 对于优化代码的支持大部分都没有真正实现。
Tolmach 和 Appel [127] 描述了 ML 的调试器,这边的编译器可以总是执行优化,但是程序在编译前会自动注解上调试语句。为了调试优化程序,程序员不得不手动重编译和重执行程序。就像未优化的程序,标注的程序运行明显慢于全优化的程序。
10.8 结论
在存在许多全局优化,如常量折叠,通用子表达式消除,死代码消除,过程内联,代码移动和指令调度,SELF 系统提供了全源码级调试能力增强了程序员的生产力。其它系统不得不严格限制优化来达到全源码级调试,因为诸如单步或者中断点需要源码级状态来实现几乎每个指令边界的可恢复。与之相比,我们的调试系统让优化编译器有更多的自由,因为它不需要再每个指令上都需要全调试。
全源码调试不需要排除全优化。两个技术让它们可以结合在一起:延迟退优化和中断点。当需要时退优化代码会向用户隐藏编译器执行的优化。退优化支持单步调试,运行方法完成,替换内联方法,和其它操作,但时只影响正在调试的活动;其它方法都是全速的。调试信息只是在中断点相对范围里需要,因此编译器可以在中断点间执行昂贵的优化而不影响调试能力。调试系统也允许已优化程序在它运行的时候被改变(如此执行可以在改变后重新唤醒)。特别是,系统保证在改变之后不会再有调用使用老的定义,即使方法被内联到其它已编译方法。
据我们所知,SELF 系统时第一个为优化程序提供全源码级调试(特别时单步)的系统。据我们了解,它也是第一个当改变运行中程序时能提供源码级语义的。伴随着自适应优化,调试系统让它能整合一个优化编译器进探索性编程环境。
11. 结论
“后面更好”:延后绑定可以使用延后的编译进行优化。延后绑定对于传统编译器是一个问题,因为它们没有足够的信息从源代码中独自生成高效的代码。通过延迟优化直到需要的信息是有效的,一个编译器可以生成更好的代码。对于一个交互系统如 SELF,延迟优化还有一个额外的好处,那就是通过将代价高昂的优化限制在程序的时间关键部分来减少编译暂停。
多态内联缓存已经证明是一个吸引人的机制,能为类型反馈收集需要的类型信息。除了记录每个发送的类型信息,它们也实际加速了动态分派。换句话说,带有类型反馈“仪表”的程序比没有的程序运行快许多。因此,多态内联缓存是动态分派一个吸引人的实现,即使对于系统没有使用类型反馈也一样。
当结合时,类型反馈和自适应重编译提高了运行时性能和交互性能。平均上,当带有类型反馈时程序运行快了 1.7 倍且少了 3.6 倍调用。总体上,已优化的 SELF 程序的执行特性出奇的靠近 SPECint89 测试集套件。我们的测量结果表明面向对象程序可以高效地执行而不需要特殊的硬件支持,只要给予正确的编译器技术。
比起前代 SELF 编译器,新的编译器明显更简单(11,000 vs 26,000 行),编译每个源码单元大约快了 2.5 倍。自适应重编译进一步提高了编译基本速度,因为大部分的编译可以通过更快的非优化编译器执行,然后优化编译随着时间而扩大开。在 SELF-93 系统中,自适应重编译在很大程度上设法隐藏了当代工作站上的优化;对于更快的机器,编译停顿应该变得几乎不可见。
动态(重)编译最明显的效果是程序初始运行非常的慢,当从零开始的时候(即没有任何已编译代码)。我们的实验表明 一个 10,000 行程序在当代工作站上预期可以获得半分钟以上的速度提升。类似的,一个程序改变会暂时减缓执行,与它对当前存在的代码的影响成正比。通常改变越小和越局部,越可以连续执行而没有延迟。
最后,动态重编译允许我们调和全局优化和源码级调试。编译器提供的调试信息只需要支持从程序可能中断的点上获得源码级程序状态,而不需要在任意指令边界。在两个中断点间,允许任意的优化。需要读出超出当前状态的调试需求是通过透明地退优化已编译代码,然后在未优化的代码上执行这个需求。因此,程序员不会被要求在速度和源码级调试上做选择:程序可以在任意时间点调试,即使它们被优化了。
动态重编译经常被视为复杂和难以实现的。 我们希望我们的工作表明动态重编译可以实际让实现者更轻松。一旦底层机制可行,基于动态编译的新功能在添加时可以相对简单。例如,源码级调试系统(第十章)和异常情况处理(6.1.4节)可以用相对小的努力(分别时大约 3,000 和 100 行代码)就能实现,因为系统已经支持了动态编译。我们相信动态编译可以成为交互开发环境一个有吸引的选择,即使是在编译器可以获得超过 SELF 的静态信息的语言(即,编译器可以为调试目的生成合理的代码而不需要运行时信息)。
11.1 适用性
虽然我们的实现依赖于动态编译,但本文中描述的大部分技术并不需要它。类型反馈可以直接整合到一个传统的编译系统里,对于其它向导优化也是一样的。使用退优化的源码级调试可以通过保持预编译未优化代码到分离文件中来实现。多态内联缓存只需要一个简单的桩生成器,不需要全成熟的动态编译。只有动态重编译–自然而然–特定于需要动态编译。
本文描述的技术都不限制在 SELF 语言上。调试系统大部分是语言独立的,但它在指针安全的语言上更好用,因为在这些语言里中断点间的距离可以更远。类型反馈可以优化任意语言中的延迟绑定;除了面向对象的语言,重度使用了延迟绑定的非面向对象的语言(如,APL的泛型操作,Lisp的泛型计算)也可以从这个优化中受益。最后,任何使用动态编译的系统可能从自适应重编译中获得性能提升或者编译停顿较少的受益。
11.2 未来工作
一个可能的提升方向是编译固有开销。加速编译将会降低编译停顿和启动时间。增加处理器速度有助于降低停顿–当今的工作站已经优于我们测量使用的系统有三倍。但是,随着编译器速度的增加,问题规模也在增加,因此,进一步降低编译停顿的软件技术在仍是未来研究中的一个有趣领域。如 4.5 节讨论的,非优化编译器可以被解释器替换,只损失较少的执行速度。加速优化编译器更难,虽然引入一个编译查找缓存可以以较小的努力获得大约 25% 的编译速度提升。能显著加速的方案包括,提升内联系统,预编译经常内联方法的中间代码(9.5节)。在多核工作站上,重编译可以执行在独立的核心上,因此,重编译停顿可以降低到几乎为 0。或者,优化可以在用户“思考停顿上”投机执行。
在我们的系统上,重编译参数是静态定义的。因此,它们的值有些时候只是交互性能和最终性能间的妥协。例如,如果调用计数器的半衰期非常低,最终性能通常很好,但编译停顿会很糟糕。一个好的系统会延长编译自适应性通过根据场景变化半衰期参数。在启动场景下(特性是由许多的编译),半衰期会比较短来阻止过早的编译。然后,当最初的编译热潮已经平息时,半衰期可以动态的增加允许更多的应用被优化。类似地,一个长期的重编译机制可以优化长时间执行的程序部分;这样的系统会每几分钟而不是几秒的收集一次信息,例如,通过使用一些廉价的向导形式。
我们的结果通过结合类型反馈和更激进的全局优化器可以得到扩展。因为内联放大了全局优化的范围,一个好的优化器会明显地增加内联的收益。在探索性编程的环境下,更激进的优化无法保证,因为它很可能会增加编译停顿。但是,这样的优化可以用在应用提取器上,其可以生成应用独立可以执行文件,或者在批处理式的编译中。这样的编译器也可以使用来自向导器[30]提供的额外信息,或来自类型推导[5]的,从而生成更好的代码。
最后,SELF-93 禁止来自前代 SELF 系统的过度定制问题。因为系统总是客制化已编译代码到确定的接收者类型,有时候甚至是重复的,这时它最好是在不同接受者类型间共享已编译代码,既是因为代码完全相同,也因为客制化的优化收益为负。原始地(当 SELF-89 第一次引入客制化),即使没有机会也总是客制化,因为系统不是自适应的。现在,在自适应重编译下,延迟客制化成为了可能,即,只在性能关键的程序部分进行,除非客制化使代码受益(即,当许多消息被发送到 self)。类似的,系统可以选择代码克隆 [62] 而不是代码内联。这样的系统能同时降低代码大小和提高性能(因为将地了指令缓存开销),因此代表了未来工作的一个有趣领域。
11.3 总结
当 SELF 在 1987 年第一次提出时,大部分人(包括作者)在被要求判断一个有效实现的可行性时,都将其放入“没有希望”的分类里。仅仅几年后,Chambers 和 Ungar 表明严格限制程序集的情况下 SELF 可以获得杰出的性能 [26]。不幸地是大的面向对象的程序仍然不能很好的执行。此外,以相当大的编译器复杂度和编译速度为代价运行时性能是可以达到的,但这对于交互使用太慢了。本文呈现了一个第三代 SELF 系统,在降低实现复杂度的情况下,能同时提高执行和编译速度。在过去的五年里,我们显然得到的教训是“绝望”并非如此。我们希望这个实现 SELF 的过程将会鼓励其它人找到更好的解决方案,来实现面向对象语言,或其它重度使用延迟编译、抽象的系统,或其它简约语言带来的挑战。
我们也希望我们的工作有助于让探索性编程环境更流行。在过去,这样的系统经常遭遇性能问题,限制了它们的被接受度。例如,通过解释型 Smalltalk 系统执行的程序慢了等价 C 程序许多倍。自适应重编译和类型反馈,结合现代硬件的速度,可以显著地扩展探索性编程环境的应用。具有更好的性能和良好的交互行为,这些技术让探索性编程在纯语言和需要更高最终性能的应用域两个方面上的应用都可行,最终,调和了探索性编程和高性能。